 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCWM: Contrastive World Models for Action Feasibility Learning in Embodied Agent Pipelines
Feb 25, 2026A reliable action feasibility scorer is a critical bottleneck in embodied agent pipelines: before any planning or reasoning occurs, the agent must identify which candidate actions are physically executable in the current state. Existing approaches use supervised fine-tuning (SFT) to train action scorers, but SFT treats each candidate independently and does not explicitly teach the model to discriminate between actions that are physically correct and those that are subtly wrong. We propose the Contrastive World Model (CWM), which fine-tunes a large language model (LLM) as an action scorer using an InfoNCE contrastive objective with hard-mined negative examples. The key idea is to push valid actions away from invalid ones in scoring space, with special emphasis on hard negatives: semantically similar but physically incompatible candidates. We evaluate CWM on the ScienceWorld benchmark through two studies. First, an intrinsic affordance evaluation on 605 hard-negative test pairs shows that CWM outperforms SFT by +6.76 percentage points on Precision@1 for minimal-edit negatives -- cases where a single word changes the physical outcome -- and achieves a higher AUC-ROC (0.929 vs. 0.906). Second, a live filter characterisation study measures how well CWM ranks gold-path actions against all valid environment actions during task execution. Under out-of-distribution stress conditions, CWM maintains a significantly better safety margin (-2.39) than SFT (-3.96), indicating that the gold action is ranked closer to the top. These results support the hypothesis that contrastive training induces representations that capture physical feasibility more faithfully than SFT alone.
Physics-Informed Neuro-Symbolic Recommender System: A Dual-Physics Approach for Personalized Nutrition
Jan 27, 2026Traditional e-commerce recommender systems primarily optimize for user engagement and purchase likelihood, often neglecting the rigid physiological constraints required for human health. Standard collaborative filtering algorithms are structurally blind to these hard limits, frequently suggesting bundles that fail to meet specific total daily energy expenditure and macronutrient balance requirements. To address this disconnect, this paper introduces a Physics-Informed Neuro-Symbolic Recommender System that integrates nutritional science directly into the recommendation pipeline via a dual-layer architecture. The framework begins by constructing a semantic knowledge graph using sentence-level encoders to strictly align commercial products with authoritative nutritional data. During the training phase, an implicit physics regularizer applies a differentiable thermodynamic loss function, ensuring that learned latent embeddings reflect nutritional plausibility rather than simple popularity. Subsequently, during the inference phase, an explicit physics optimizer employs simulated annealing and elastic quantity optimization to generate discrete grocery bundles that strictly adhere to the user's protein and caloric targets.
Mining-Gym: A Configurable RL Benchmarking Environment for Truck Dispatch Scheduling
Mar 24, 2025
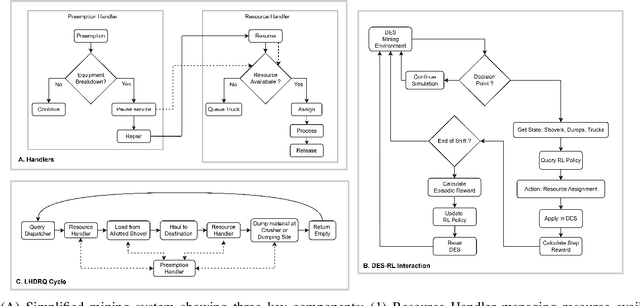


Mining process optimization particularly truck dispatch scheduling is a critical factor in enhancing the efficiency of open pit mining operations However the dynamic and stochastic nature of mining environments characterized by uncertainties such as equipment failures truck maintenance and variable haul cycle times poses significant challenges for traditional optimization methods While Reinforcement Learning RL has shown promise in adaptive decision making for mining logistics its practical deployment requires rigorous evaluation in realistic and customizable simulation environments The lack of standardized benchmarking environments limits fair algorithm comparisons reproducibility and the real world applicability of RL based approaches in open pit mining settings To address this challenge we introduce Mining Gym a configurable open source benchmarking environment designed for training testing and comparing RL algorithms in mining process optimization Built on Discrete Event Simulation DES and seamlessly integrated with the OpenAI Gym interface Mining Gym provides a structured testbed that enables the direct application of advanced RL algorithms from Stable Baselines The framework models key mining specific uncertainties such as equipment failures queue congestion and the stochasticity of mining processes ensuring a realistic and adaptive learning environment Additionally Mining Gym features a graphical user interface GUI for intuitive mine site configuration a comprehensive data logging system a built in KPI dashboard and real time visual representation of the mine site These capabilities facilitate standardized reproducible evaluations across multiple RL strategies and baseline heuristics
LOID: Lane Occlusion Inpainting and Detection for Enhanced Autonomous Driving Systems
Aug 17, 2024
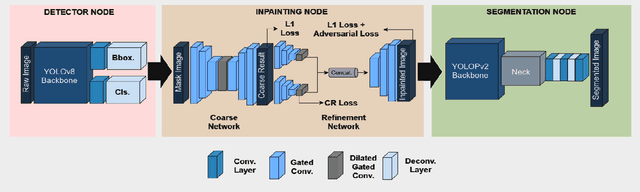
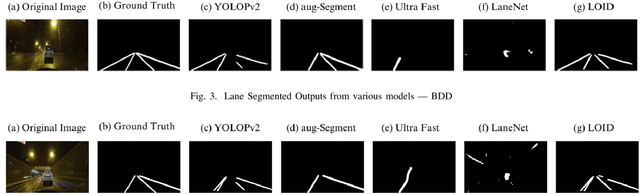

Accurate lane detection is essential for effective path planning and lane following in autonomous driving, especially in scenarios with significant occlusion from vehicles and pedestrians. Existing models often struggle under such conditions, leading to unreliable navigation and safety risks. We propose two innovative approaches to enhance lane detection in these challenging environments, each showing notable improvements over current methods. The first approach aug-Segment improves conventional lane detection models by augmenting the training dataset of CULanes with simulated occlusions and training a segmentation model. This method achieves a 12% improvement over a number of SOTA models on the CULanes dataset, demonstrating that enriched training data can better handle occlusions, however, since this model lacked robustness to certain settings, our main contribution is the second approach, LOID Lane Occlusion Inpainting and Detection. LOID introduces an advanced lane detection network that uses an image processing pipeline to identify and mask occlusions. It then employs inpainting models to reconstruct the road environment in the occluded areas. The enhanced image is processed by a lane detection algorithm, resulting in a 20% & 24% improvement over several SOTA models on the BDDK100 and CULanes datasets respectively, highlighting the effectiveness of this novel technique.
PINNs for Medical Image Analysis: A Survey
Aug 02, 2024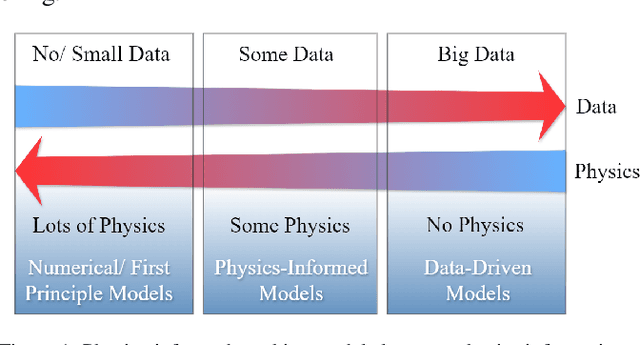

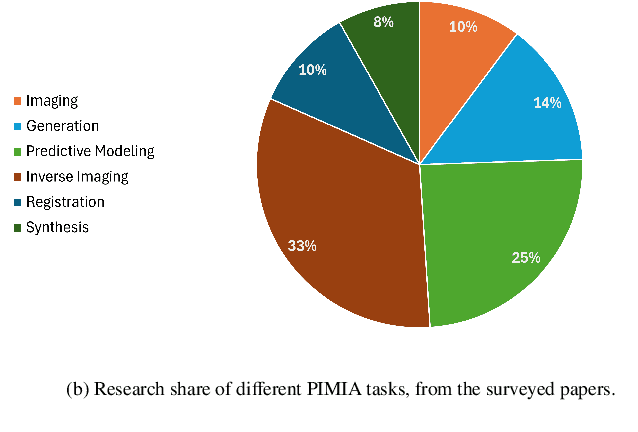

The incorporation of physical information in machine learning frameworks is transforming medical image analysis (MIA). By integrating fundamental knowledge and governing physical laws, these models achieve enhanced robustness and interpretability. In this work, we explore the utility of physics-informed approaches for MIA (PIMIA) tasks such as registration, generation, classification, and reconstruction. We present a systematic literature review of over 80 papers on physics-informed methods dedicated to MIA. We propose a unified taxonomy to investigate what physics knowledge and processes are modelled, how they are represented, and the strategies to incorporate them into MIA models. We delve deep into a wide range of image analysis tasks, from imaging, generation, prediction, inverse imaging (super-resolution and reconstruction), registration, and image analysis (segmentation and classification). For each task, we thoroughly examine and present in a tabular format the central physics-guided operation, the region of interest (with respect to human anatomy), the corresponding imaging modality, the dataset used for model training, the deep network architecture employed, and the primary physical process, equation, or principle utilized. Additionally, we also introduce a novel metric to compare the performance of PIMIA methods across different tasks and datasets. Based on this review, we summarize and distil our perspectives on the challenges, open research questions, and directions for future research. We highlight key open challenges in PIMIA, including selecting suitable physics priors and establishing a standardized benchmarking platform.
A Survey on Physics Informed Reinforcement Learning: Review and Open Problems
Sep 05, 2023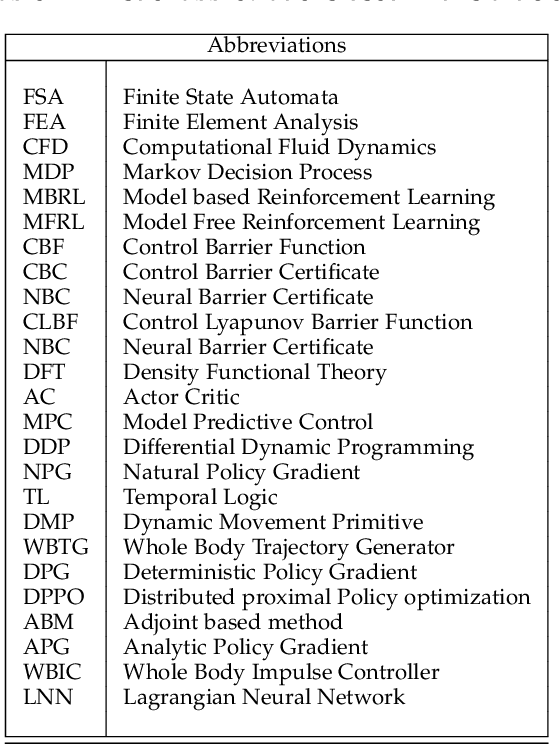
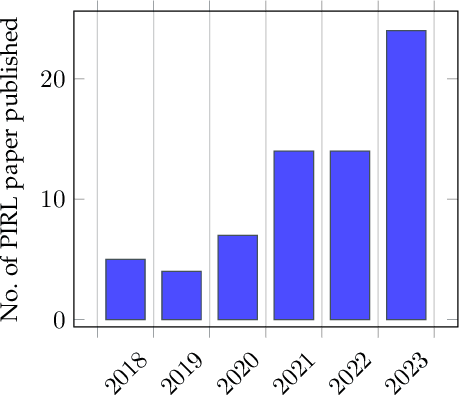
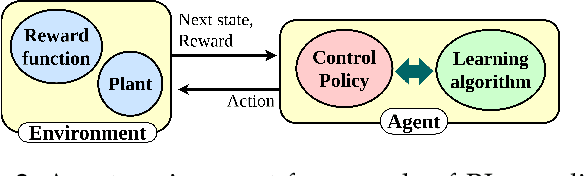

The inclusion of physical information in machine learning frameworks has revolutionized many application areas. This involves enhancing the learning process by incorporating physical constraints and adhering to physical laws. In this work we explore their utility for reinforcement learning applications. We present a thorough review of the literature on incorporating physics information, as known as physics priors, in reinforcement learning approaches, commonly referred to as physics-informed reinforcement learning (PIRL). We introduce a novel taxonomy with the reinforcement learning pipeline as the backbone to classify existing works, compare and contrast them, and derive crucial insights. Existing works are analyzed with regard to the representation/ form of the governing physics modeled for integration, their specific contribution to the typical reinforcement learning architecture, and their connection to the underlying reinforcement learning pipeline stages. We also identify core learning architectures and physics incorporation biases (i.e., observational, inductive and learning) of existing PIRL approaches and use them to further categorize the works for better understanding and adaptation. By providing a comprehensive perspective on the implementation of the physics-informed capability, the taxonomy presents a cohesive approach to PIRL. It identifies the areas where this approach has been applied, as well as the gaps and opportunities that exist. Additionally, the taxonomy sheds light on unresolved issues and challenges, which can guide future research. This nascent field holds great potential for enhancing reinforcement learning algorithms by increasing their physical plausibility, precision, data efficiency, and applicability in real-world scenarios.
Physics-Informed Computer Vision: A Review and Perspectives
Jun 01, 2023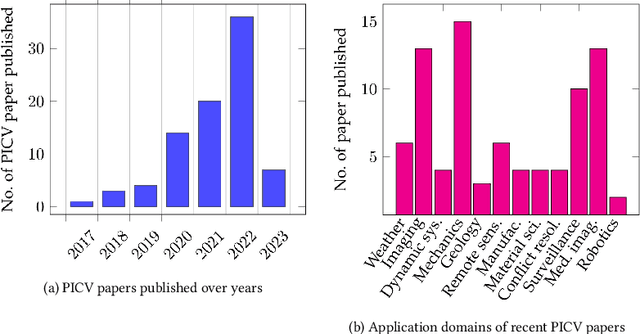
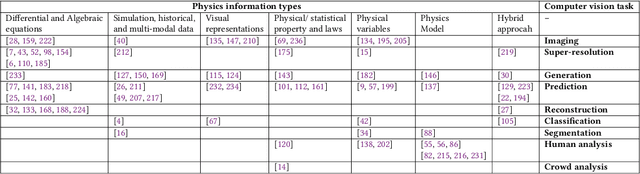
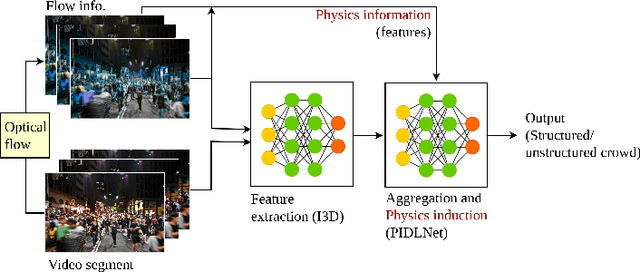
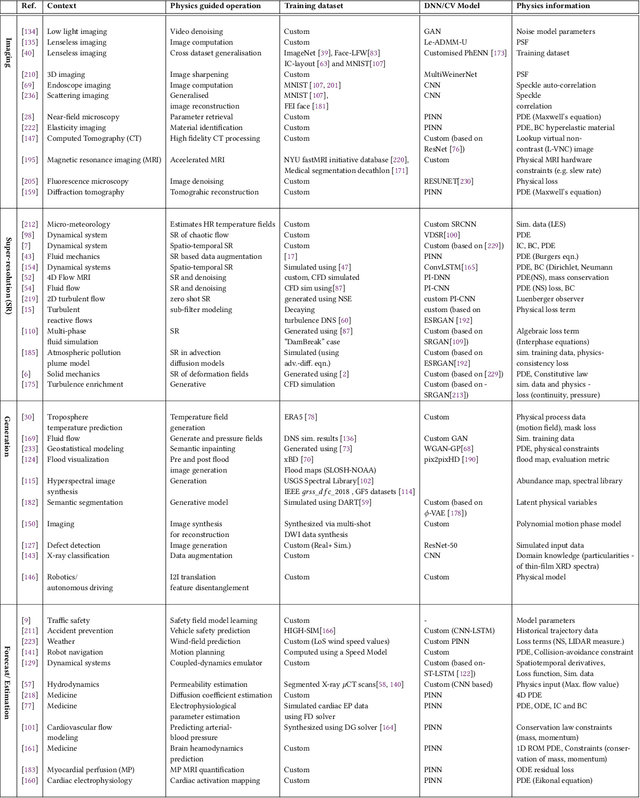
Incorporation of physical information in machine learning frameworks are opening and transforming many application domains. Here the learning process is augmented through the induction of fundamental knowledge and governing physical laws. In this work we explore their utility for computer vision tasks in interpreting and understanding visual data. We present a systematic literature review of formulation and approaches to computer vision tasks guided by physical laws. We begin by decomposing the popular computer vision pipeline into a taxonomy of stages and investigate approaches to incorporate governing physical equations in each stage. Existing approaches in each task are analyzed with regard to what governing physical processes are modeled, formulated and how they are incorporated, i.e. modify data (observation bias), modify networks (inductive bias), and modify losses (learning bias). The taxonomy offers a unified view of the application of the physics-informed capability, highlighting where physics-informed learning has been conducted and where the gaps and opportunities are. Finally, we highlight open problems and challenges to inform future research. While still in its early days, the study of physics-informed computer vision has the promise to develop better computer vision models that can improve physical plausibility, accuracy, data efficiency and generalization in increasingly realistic applications.
Boosting Exploration in Actor-Critic Algorithms by Incentivizing Plausible Novel States
Oct 01, 2022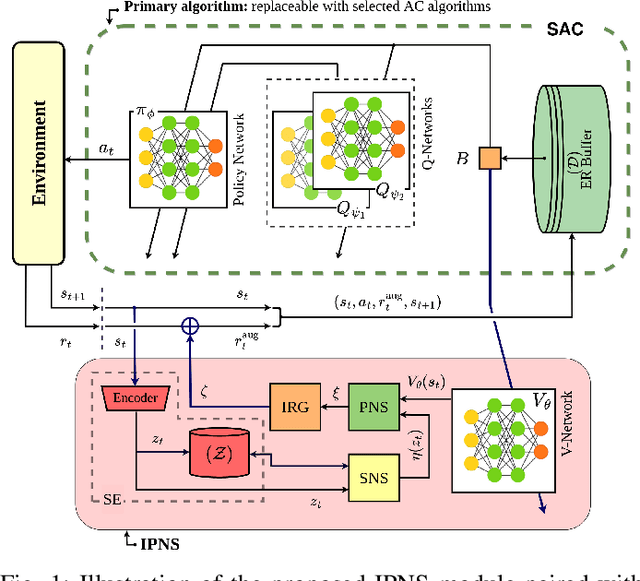
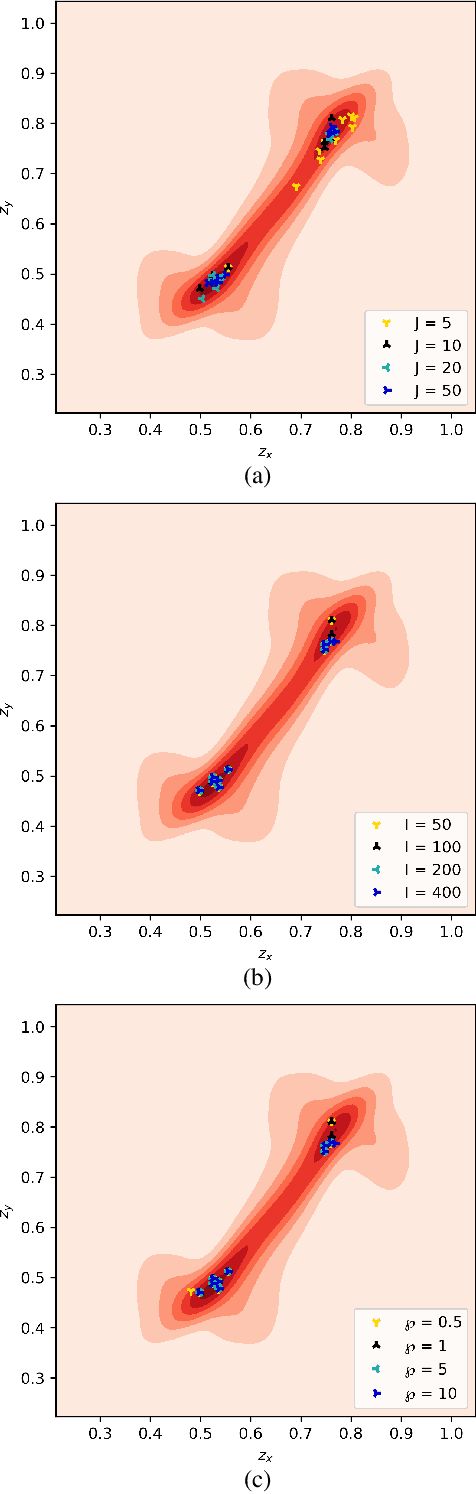
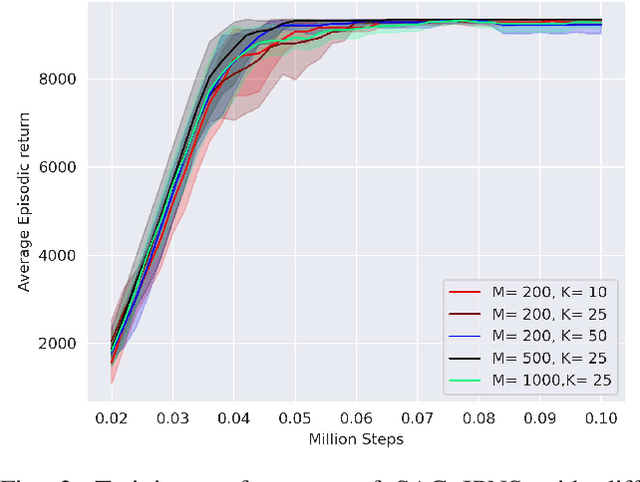
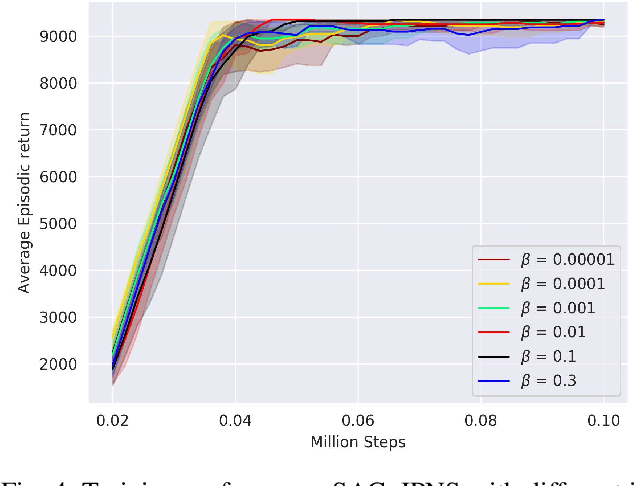
Actor-critic (AC) algorithms are a class of model-free deep reinforcement learning algorithms, which have proven their efficacy in diverse domains, especially in solving continuous control problems. Improvement of exploration (action entropy) and exploitation (expected return) using more efficient samples is a critical issue in AC algorithms. A basic strategy of a learning algorithm is to facilitate indiscriminately exploring all of the environment state space, as well as to encourage exploring rarely visited states rather than frequently visited one. Under this strategy, we propose a new method to boost exploration through an intrinsic reward, based on measurement of a state's novelty and the associated benefit of exploring the state (with regards to policy optimization), altogether called plausible novelty. With incentivized exploration of plausible novel states, an AC algorithm is able to improve its sample efficiency and hence training performance. The new method is verified by extensive simulations of continuous control tasks of MuJoCo environments on a variety of prominent off-policy AC algorithms.
Improved Soft Actor-Critic: Mixing Prioritized Off-Policy Samples with On-Policy Experience
Sep 24, 2021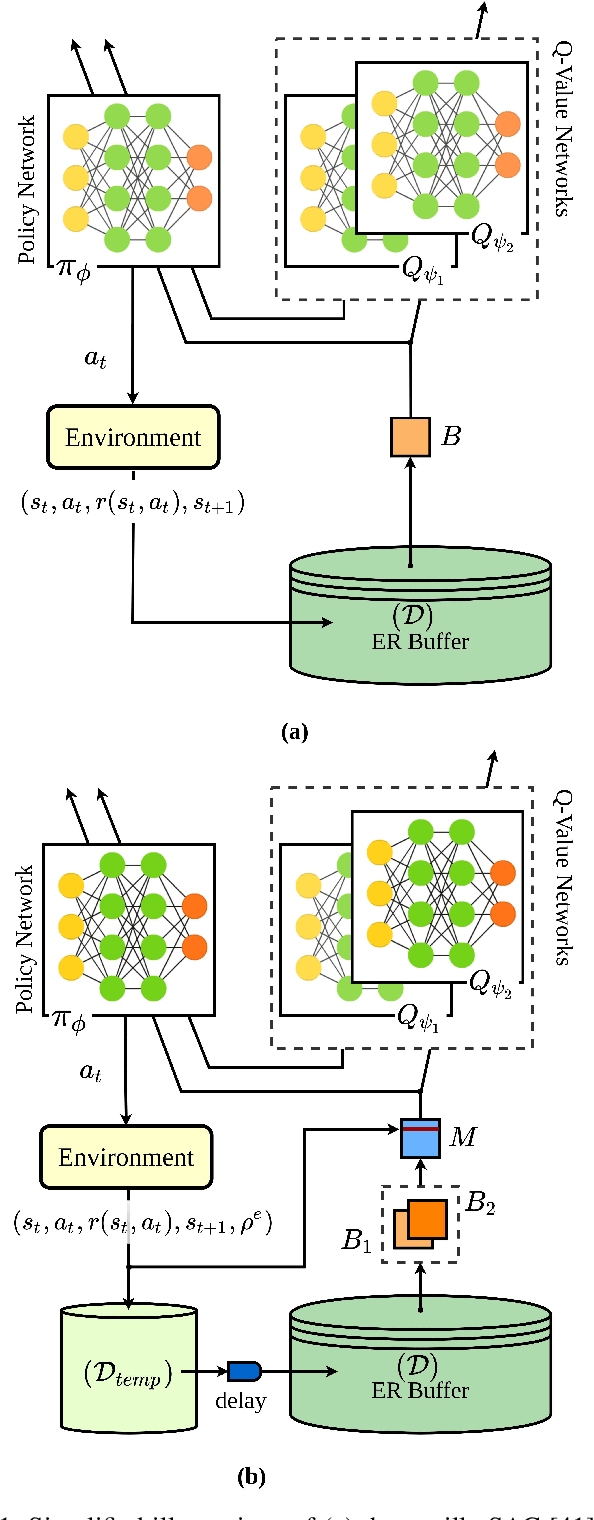
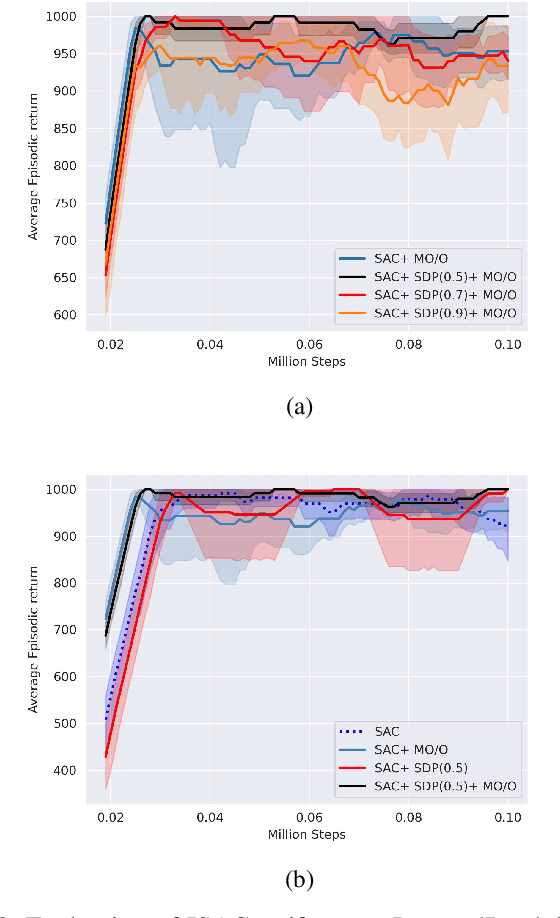
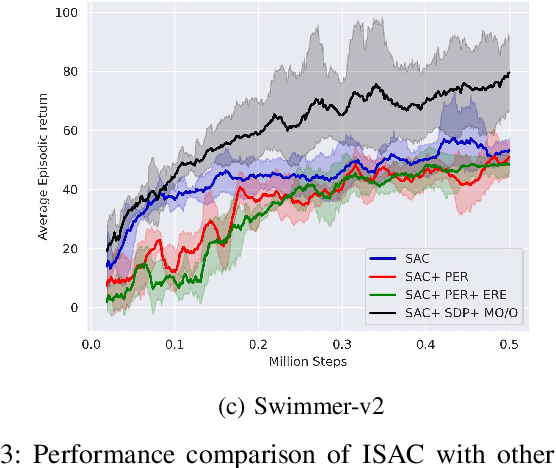
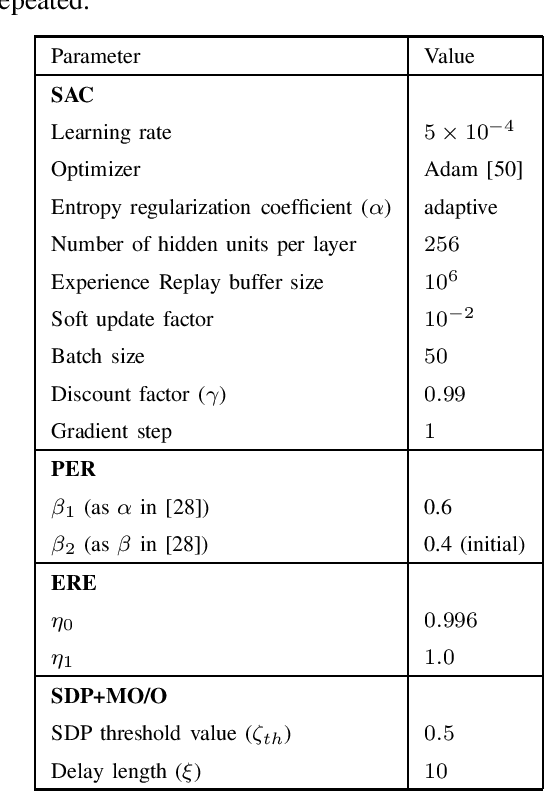
Soft Actor-Critic (SAC) is an off-policy actor-critic reinforcement learning algorithm, essentially based on entropy regularization. SAC trains a policy by maximizing the trade-off between expected return and entropy (randomness in the policy). It has achieved state-of-the-art performance on a range of continuous-control benchmark tasks, outperforming prior on-policy and off-policy methods. SAC works in an off-policy fashion where data are sampled uniformly from past experiences (stored in a buffer) using which parameters of the policy and value function networks are updated. We propose certain crucial modifications for boosting the performance of SAC and make it more sample efficient. In our proposed improved SAC, we firstly introduce a new prioritization scheme for selecting better samples from the experience replay buffer. Secondly we use a mixture of the prioritized off-policy data with the latest on-policy data for training the policy and the value function networks. We compare our approach with the vanilla SAC and some recent variants of SAC and show that our approach outperforms the said algorithmic benchmarks. It is comparatively more stable and sample efficient when tested on a number of continuous control tasks in MuJoCo environments.
Optimal Actor-Critic Policy with Optimized Training Datasets
Aug 16, 2021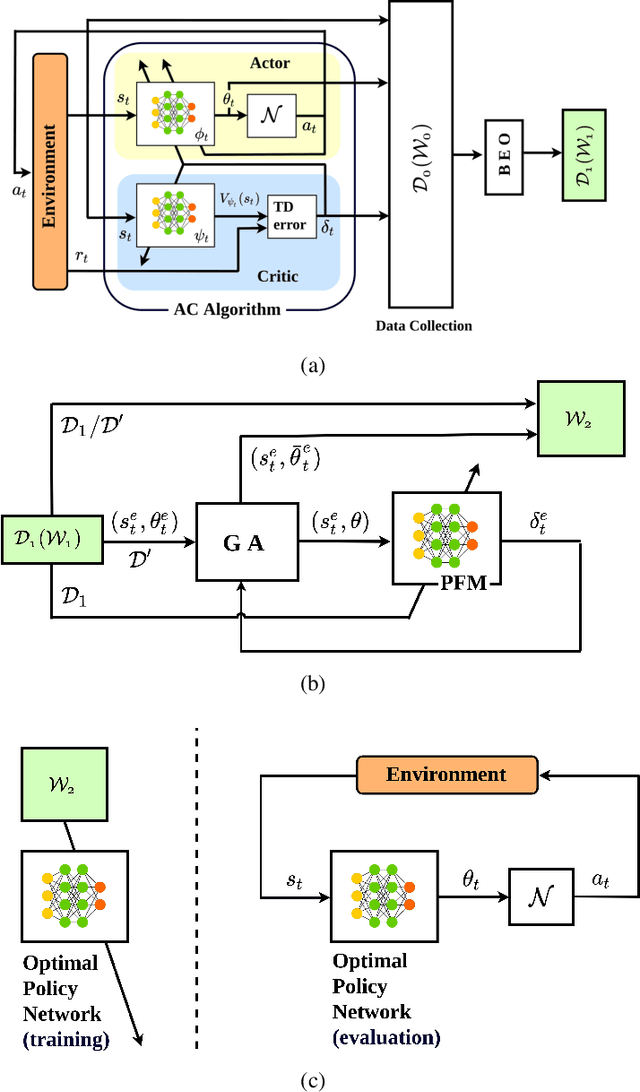

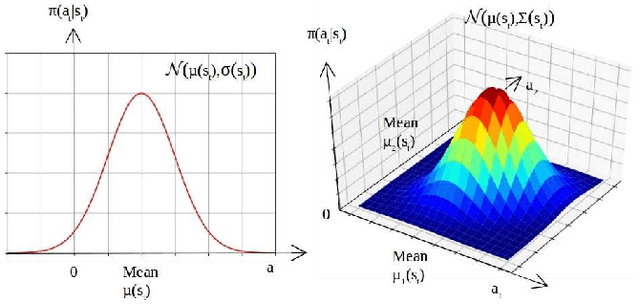
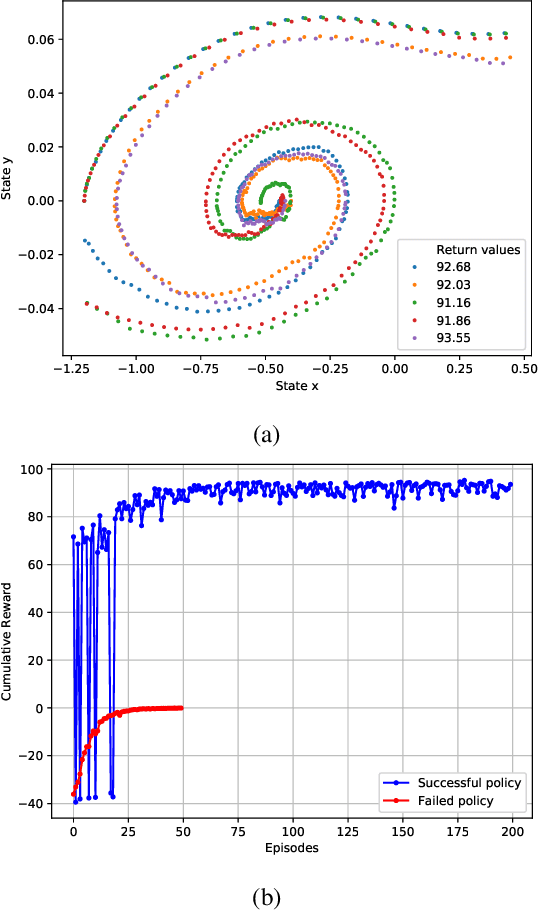
Actor-critic (AC) algorithms are known for their efficacy and high performance in solving reinforcement learning problems, but they also suffer from low sampling efficiency. An AC based policy optimization process is iterative and needs to frequently access the agent-environment system to evaluate and update the policy by rolling out the policy, collecting rewards and states (i.e. samples), and learning from them. It ultimately requires a huge number of samples to learn an optimal policy. To improve sampling efficiency, we propose a strategy to optimize the training dataset that contains significantly less samples collected from the AC process. The dataset optimization is made of a best episode only operation, a policy parameter-fitness model, and a genetic algorithm module. The optimal policy network trained by the optimized training dataset exhibits superior performance compared to many contemporary AC algorithms in controlling autonomous dynamical systems. Evaluation on standard benchmarks show that the method improves sampling efficiency, ensures faster convergence to optima, and is more data-efficient than its counterparts.