 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScore-based Integrated Gradient for Root Cause Explanations of Outliers
Jan 29, 2026Identifying the root causes of outliers is a fundamental problem in causal inference and anomaly detection. Traditional approaches based on heuristics or counterfactual reasoning often struggle under uncertainty and high-dimensional dependencies. We introduce SIREN, a novel and scalable method that attributes the root causes of outliers by estimating the score functions of the data likelihood. Attribution is computed via integrated gradients that accumulate score contributions along paths from the outlier toward the normal data distribution. Our method satisfies three of the four classic Shapley value axioms - dummy, efficiency, and linearity - as well as an asymmetry axiom derived from the underlying causal structure. Unlike prior work, SIREN operates directly on the score function, enabling tractable and uncertainty-aware root cause attribution in nonlinear, high-dimensional, and heteroscedastic causal models. Extensive experiments on synthetic random graphs and real-world cloud service and supply chain datasets show that SIREN outperforms state-of-the-art baselines in both attribution accuracy and computational efficiency.
Robust SDE Parameter Estimation Under Missing Time Information Setting
Jan 28, 2026Recent advances in stochastic differential equations (SDEs) have enabled robust modeling of real-world dynamical processes across diverse domains, such as finance, health, and systems biology. However, parameter estimation for SDEs typically relies on accurately timestamped observational sequences. When temporal ordering information is corrupted, missing, or deliberately hidden (e.g., for privacy), existing estimation methods often fail. In this paper, we investigate the conditions under which temporal order can be recovered and introduce a novel framework that simultaneously reconstructs temporal information and estimates SDE parameters. Our approach exploits asymmetries between forward and backward processes, deriving a score-matching criterion to infer the correct temporal order between pairs of observations. We then recover the total order via a sorting procedure and estimate SDE parameters from the reconstructed sequence using maximum likelihood. Finally, we conduct extensive experiments on synthetic and real-world datasets to demonstrate the effectiveness of our method, extending parameter estimation to settings with missing temporal order and broadening applicability in sensitive domains.
Rethinking Deep Alignment Through The Lens Of Incomplete Learning
Nov 15, 2025Large language models exhibit systematic vulnerabilities to adversarial attacks despite extensive safety alignment. We provide a mechanistic analysis revealing that position-dependent gradient weakening during autoregressive training creates signal decay, leading to incomplete safety learning where safety training fails to transform model preferences in later response regions fully. We introduce base-favored tokens -- vocabulary elements where base models assign higher probability than aligned models -- as computational indicators of incomplete safety learning and develop a targeted completion method that addresses undertrained regions through adaptive penalties and hybrid teacher distillation. Experimental evaluation across Llama and Qwen model families demonstrates dramatic improvements in adversarial robustness, with 48--98% reductions in attack success rates while preserving general capabilities. These results establish both a mechanistic understanding and practical solutions for fundamental limitations in safety alignment methodologies.
Planner-Refiner: Dynamic Space-Time Refinement for Vision-Language Alignment in Videos
Aug 10, 2025Vision-language alignment in video must address the complexity of language, evolving interacting entities, their action chains, and semantic gaps between language and vision. This work introduces Planner-Refiner, a framework to overcome these challenges. Planner-Refiner bridges the semantic gap by iteratively refining visual elements' space-time representation, guided by language until semantic gaps are minimal. A Planner module schedules language guidance by decomposing complex linguistic prompts into short sentence chains. The Refiner processes each short sentence, a noun-phrase and verb-phrase pair, to direct visual tokens' self-attention across space then time, achieving efficient single-step refinement. A recurrent system chains these steps, maintaining refined visual token representations. The final representation feeds into task-specific heads for alignment generation. We demonstrate Planner-Refiner's effectiveness on two video-language alignment tasks: Referring Video Object Segmentation and Temporal Grounding with varying language complexity. We further introduce a new MeViS-X benchmark to assess models' capability with long queries. Superior performance versus state-of-the-art methods on these benchmarks shows the approach's potential, especially for complex prompts.
Sparse Mixture of Experts as Unified Competitive Learning
Mar 29, 2025Sparse Mixture of Experts (SMoE) improves the efficiency of large language model training by directing input tokens to a subset of experts. Despite its success in generation tasks, its generalization ability remains an open question. In this paper, we demonstrate that current SMoEs, which fall into two categories: (1) Token Choice ;and (2) Expert Choice, struggle with tasks such as the Massive Text Embedding Benchmark (MTEB). By analyzing their mechanism through the lens of competitive learning, our study finds that the Token Choice approach may overly focus on irrelevant experts, while the Expert Choice approach risks discarding important tokens, potentially affecting performance. Motivated by this analysis, we propose Unified Competitive Learning SMoE (USMoE), a novel and efficient framework designed to improve the performance of existing SMoEs in both scenarios: with and without training. Extensive experiments across various tasks show that USMoE achieves up to a 10% improvement over traditional approaches or reduces computational inference costs by 14% while maintaining strong performance.
S2MoE: Robust Sparse Mixture of Experts via Stochastic Learning
Mar 29, 2025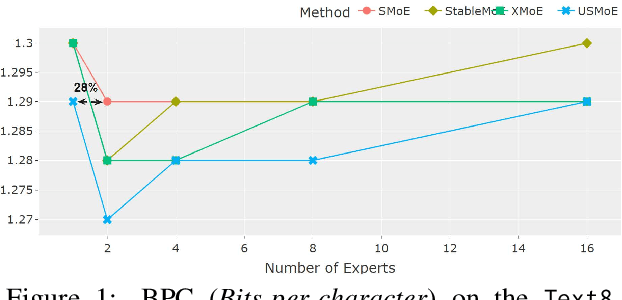
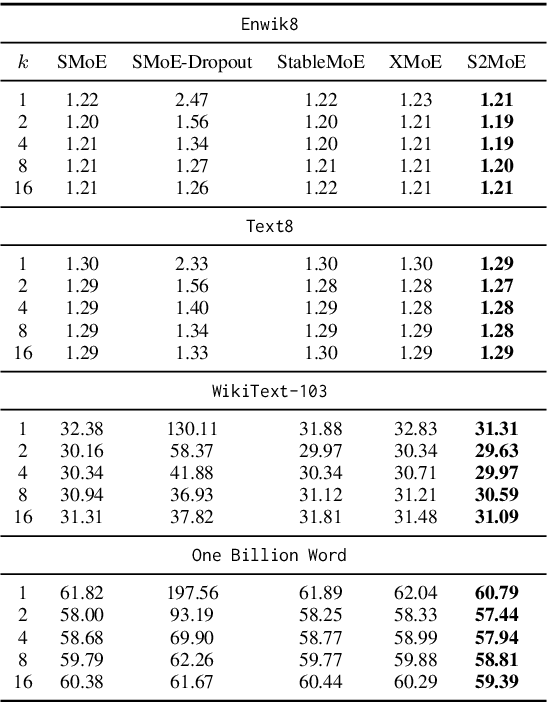
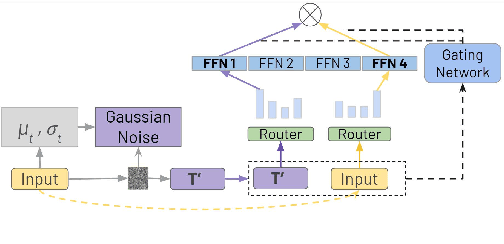
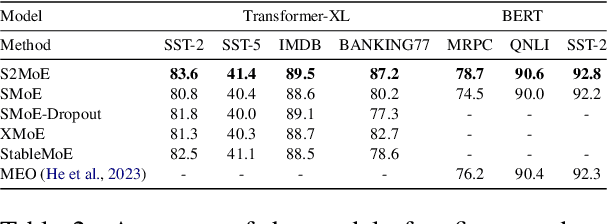
Sparse Mixture of Experts (SMoE) enables efficient training of large language models by routing input tokens to a select number of experts. However, training SMoE remains challenging due to the issue of representation collapse. Recent studies have focused on improving the router to mitigate this problem, but existing approaches face two key limitations: (1) expert embeddings are significantly smaller than the model's dimension, contributing to representation collapse, and (2) routing each input to the Top-K experts can cause them to learn overly similar features. In this work, we propose a novel approach called Robust Sparse Mixture of Experts via Stochastic Learning (S2MoE), which is a mixture of experts designed to learn from both deterministic and non-deterministic inputs via Learning under Uncertainty. Extensive experiments across various tasks demonstrate that S2MoE achieves performance comparable to other routing methods while reducing computational inference costs by 28%.
Finding the Trigger: Causal Abductive Reasoning on Video Events
Jan 16, 2025This paper introduces a new problem, Causal Abductive Reasoning on Video Events (CARVE), which involves identifying causal relationships between events in a video and generating hypotheses about causal chains that account for the occurrence of a target event. To facilitate research in this direction, we create two new benchmark datasets with both synthetic and realistic videos, accompanied by trigger-target labels generated through a novel counterfactual synthesis approach. To explore the challenge of solving CARVE, we present a Causal Event Relation Network (CERN) that examines the relationships between video events in temporal and semantic spaces to efficiently determine the root-cause trigger events. Through extensive experiments, we demonstrate the critical roles of event relational representation learning and interaction modeling in solving video causal reasoning challenges. The introduction of the CARVE task, along with the accompanying datasets and the CERN framework, will advance future research on video causal reasoning and significantly facilitate various applications, including video surveillance, root-cause analysis and movie content management.
Learning Structural Causal Models from Ordering: Identifiable Flow Models
Dec 13, 2024
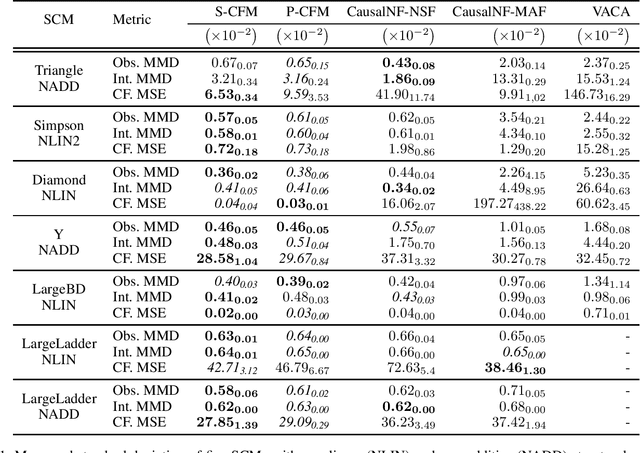


In this study, we address causal inference when only observational data and a valid causal ordering from the causal graph are available. We introduce a set of flow models that can recover component-wise, invertible transformation of exogenous variables. Our flow-based methods offer flexible model design while maintaining causal consistency regardless of the number of discretization steps. We propose design improvements that enable simultaneous learning of all causal mechanisms and reduce abduction and prediction complexity to linear O(n) relative to the number of layers, independent of the number of causal variables. Empirically, we demonstrate that our method outperforms previous state-of-the-art approaches and delivers consistent performance across a wide range of structural causal models in answering observational, interventional, and counterfactual questions. Additionally, our method achieves a significant reduction in computational time compared to existing diffusion-based techniques, making it practical for large structural causal models.
Progressive Multi-granular Alignments for Grounded Reasoning in Large Vision-Language Models
Dec 11, 2024Existing Large Vision-Language Models (LVLMs) excel at matching concepts across multi-modal inputs but struggle with compositional concepts and high-level relationships between entities. This paper introduces Progressive multi-granular Vision-Language alignments (PromViL), a novel framework to enhance LVLMs' ability in performing grounded compositional visual reasoning tasks. Our approach constructs a hierarchical structure of multi-modal alignments, ranging from simple to complex concepts. By progressively aligning textual descriptions with corresponding visual regions, our model learns to leverage contextual information from lower levels to inform higher-level reasoning. To facilitate this learning process, we introduce a data generation process that creates a novel dataset derived from Visual Genome, providing a wide range of nested compositional vision-language pairs. Experimental results demonstrate that our PromViL framework significantly outperforms baselines on various visual grounding and compositional question answering tasks.
On the effectiveness of discrete representations in sparse mixture of experts
Nov 28, 2024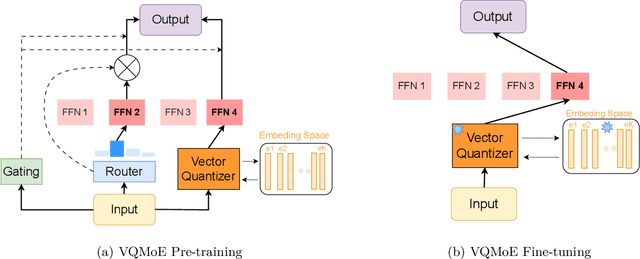
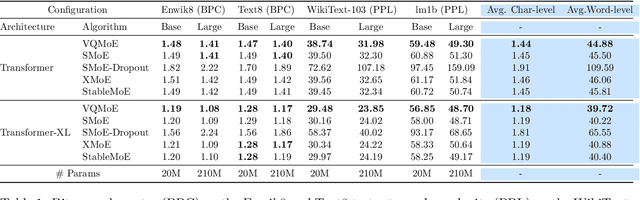
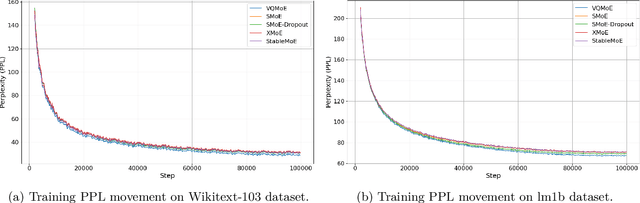
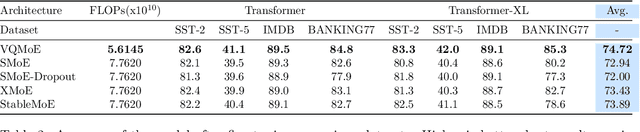
Sparse mixture of experts (SMoE) is an effective solution for scaling up model capacity without increasing the computational costs. A crucial component of SMoE is the router, responsible for directing the input to relevant experts; however, it also presents a major weakness, leading to routing inconsistencies and representation collapse issues. Instead of fixing the router like previous works, we propose an alternative that assigns experts to input via indirection, which employs the discrete representation of input that points to the expert. The discrete representations are learnt via vector quantization, resulting in a new architecture dubbed Vector-Quantized Mixture of Experts (VQMoE). We provide theoretical support and empirical evidence demonstrating the VQMoE's ability to overcome the challenges present in traditional routers. Through extensive evaluations on both large language models and vision tasks for pre-training and fine-tuning, we show that VQMoE achieves a 28% improvement in robustness compared to other SMoE routing methods, while maintaining strong performance in fine-tuning tasks.