 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Deep Alignment Through The Lens Of Incomplete Learning
Nov 15, 2025Large language models exhibit systematic vulnerabilities to adversarial attacks despite extensive safety alignment. We provide a mechanistic analysis revealing that position-dependent gradient weakening during autoregressive training creates signal decay, leading to incomplete safety learning where safety training fails to transform model preferences in later response regions fully. We introduce base-favored tokens -- vocabulary elements where base models assign higher probability than aligned models -- as computational indicators of incomplete safety learning and develop a targeted completion method that addresses undertrained regions through adaptive penalties and hybrid teacher distillation. Experimental evaluation across Llama and Qwen model families demonstrates dramatic improvements in adversarial robustness, with 48--98% reductions in attack success rates while preserving general capabilities. These results establish both a mechanistic understanding and practical solutions for fundamental limitations in safety alignment methodologies.
Planner-Refiner: Dynamic Space-Time Refinement for Vision-Language Alignment in Videos
Aug 10, 2025Vision-language alignment in video must address the complexity of language, evolving interacting entities, their action chains, and semantic gaps between language and vision. This work introduces Planner-Refiner, a framework to overcome these challenges. Planner-Refiner bridges the semantic gap by iteratively refining visual elements' space-time representation, guided by language until semantic gaps are minimal. A Planner module schedules language guidance by decomposing complex linguistic prompts into short sentence chains. The Refiner processes each short sentence, a noun-phrase and verb-phrase pair, to direct visual tokens' self-attention across space then time, achieving efficient single-step refinement. A recurrent system chains these steps, maintaining refined visual token representations. The final representation feeds into task-specific heads for alignment generation. We demonstrate Planner-Refiner's effectiveness on two video-language alignment tasks: Referring Video Object Segmentation and Temporal Grounding with varying language complexity. We further introduce a new MeViS-X benchmark to assess models' capability with long queries. Superior performance versus state-of-the-art methods on these benchmarks shows the approach's potential, especially for complex prompts.
Finding the Trigger: Causal Abductive Reasoning on Video Events
Jan 16, 2025This paper introduces a new problem, Causal Abductive Reasoning on Video Events (CARVE), which involves identifying causal relationships between events in a video and generating hypotheses about causal chains that account for the occurrence of a target event. To facilitate research in this direction, we create two new benchmark datasets with both synthetic and realistic videos, accompanied by trigger-target labels generated through a novel counterfactual synthesis approach. To explore the challenge of solving CARVE, we present a Causal Event Relation Network (CERN) that examines the relationships between video events in temporal and semantic spaces to efficiently determine the root-cause trigger events. Through extensive experiments, we demonstrate the critical roles of event relational representation learning and interaction modeling in solving video causal reasoning challenges. The introduction of the CARVE task, along with the accompanying datasets and the CERN framework, will advance future research on video causal reasoning and significantly facilitate various applications, including video surveillance, root-cause analysis and movie content management.
Progressive Multi-granular Alignments for Grounded Reasoning in Large Vision-Language Models
Dec 11, 2024Existing Large Vision-Language Models (LVLMs) excel at matching concepts across multi-modal inputs but struggle with compositional concepts and high-level relationships between entities. This paper introduces Progressive multi-granular Vision-Language alignments (PromViL), a novel framework to enhance LVLMs' ability in performing grounded compositional visual reasoning tasks. Our approach constructs a hierarchical structure of multi-modal alignments, ranging from simple to complex concepts. By progressively aligning textual descriptions with corresponding visual regions, our model learns to leverage contextual information from lower levels to inform higher-level reasoning. To facilitate this learning process, we introduce a data generation process that creates a novel dataset derived from Visual Genome, providing a wide range of nested compositional vision-language pairs. Experimental results demonstrate that our PromViL framework significantly outperforms baselines on various visual grounding and compositional question answering tasks.
Unified Framework with Consistency across Modalities for Human Activity Recognition
Sep 04, 2024



Recognizing human activities in videos is challenging due to the spatio-temporal complexity and context-dependence of human interactions. Prior studies often rely on single input modalities, such as RGB or skeletal data, limiting their ability to exploit the complementary advantages across modalities. Recent studies focus on combining these two modalities using simple feature fusion techniques. However, due to the inherent disparities in representation between these input modalities, designing a unified neural network architecture to effectively leverage their complementary information remains a significant challenge. To address this, we propose a comprehensive multimodal framework for robust video-based human activity recognition. Our key contribution is the introduction of a novel compositional query machine, called COMPUTER ($\textbf{COMP}ositional h\textbf{U}man-cen\textbf{T}ric qu\textbf{ER}y$ machine), a generic neural architecture that models the interactions between a human of interest and its surroundings in both space and time. Thanks to its versatile design, COMPUTER can be leveraged to distill distinctive representations for various input modalities. Additionally, we introduce a consistency loss that enforces agreement in prediction between modalities, exploiting the complementary information from multimodal inputs for robust human movement recognition. Through extensive experiments on action localization and group activity recognition tasks, our approach demonstrates superior performance when compared with state-of-the-art methods. Our code is available at: https://github.com/tranxuantuyen/COMPUTER.
SADL: An Effective In-Context Learning Method for Compositional Visual QA
Jul 02, 2024


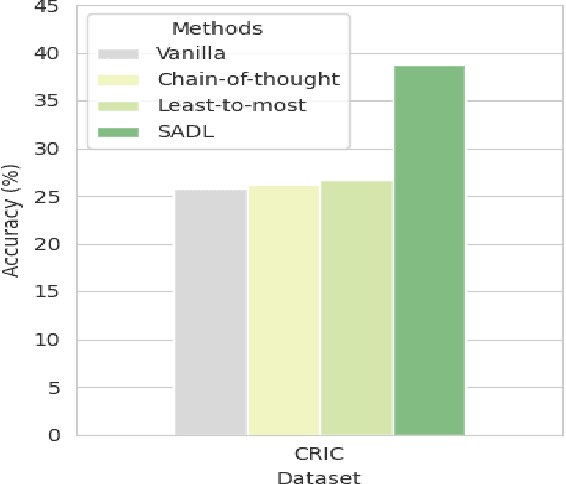
Large vision-language models (LVLMs) offer a novel capability for performing in-context learning (ICL) in Visual QA. When prompted with a few demonstrations of image-question-answer triplets, LVLMs have demonstrated the ability to discern underlying patterns and transfer this latent knowledge to answer new questions about unseen images without the need for expensive supervised fine-tuning. However, designing effective vision-language prompts, especially for compositional questions, remains poorly understood. Adapting language-only ICL techniques may not necessarily work because we need to bridge the visual-linguistic semantic gap: Symbolic concepts must be grounded in visual content, which does not share the syntactic linguistic structures. This paper introduces SADL, a new visual-linguistic prompting framework for the task. SADL revolves around three key components: SAmpling, Deliberation, and Pseudo-Labeling of image-question pairs. Given an image-question query, we sample image-question pairs from the training data that are in semantic proximity to the query. To address the compositional nature of questions, the deliberation step decomposes complex questions into a sequence of subquestions. Finally, the sequence is progressively annotated one subquestion at a time to generate a sequence of pseudo-labels. We investigate the behaviors of SADL under OpenFlamingo on large-scale Visual QA datasets, namely GQA, GQA-OOD, CLEVR, and CRIC. The evaluation demonstrates the critical roles of sampling in the neighborhood of the image, the decomposition of complex questions, and the accurate pairing of the subquestions and labels. These findings do not always align with those found in language-only ICL, suggesting fresh insights in vision-language settings.
Deep Neural Networks for Visual Reasoning
Sep 24, 2022



Visual perception and language understanding are - fundamental components of human intelligence, enabling them to understand and reason about objects and their interactions. It is crucial for machines to have this capacity to reason using these two modalities to invent new robot-human collaborative systems. Recent advances in deep learning have built separate sophisticated representations of both visual scenes and languages. However, understanding the associations between the two modalities in a shared context for multimodal reasoning remains a challenge. Focusing on language and vision modalities, this thesis advances the understanding of how to exploit and use pivotal aspects of vision-and-language tasks with neural networks to support reasoning. We derive these understandings from a series of works, making a two-fold contribution: (i) effective mechanisms for content selection and construction of temporal relations from dynamic visual scenes in response to a linguistic query and preparing adequate knowledge for the reasoning process (ii) new frameworks to perform reasoning with neural networks by exploiting visual-linguistic associations, deduced either directly from data or guided by external priors.
Video Dialog as Conversation about Objects Living in Space-Time
Jul 08, 2022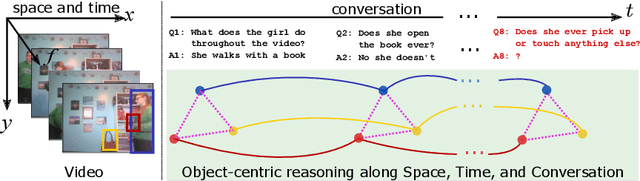

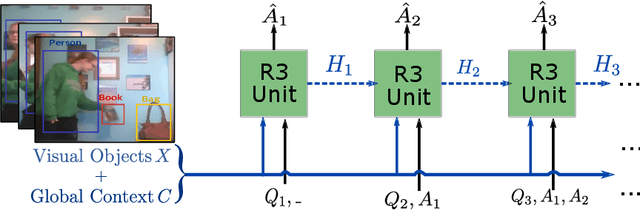
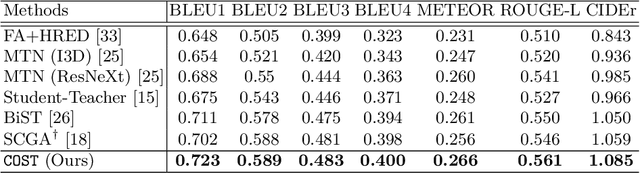
It would be a technological feat to be able to create a system that can hold a meaningful conversation with humans about what they watch. A setup toward that goal is presented as a video dialog task, where the system is asked to generate natural utterances in response to a question in an ongoing dialog. The task poses great visual, linguistic, and reasoning challenges that cannot be easily overcome without an appropriate representation scheme over video and dialog that supports high-level reasoning. To tackle these challenges we present a new object-centric framework for video dialog that supports neural reasoning dubbed COST - which stands for Conversation about Objects in Space-Time. Here dynamic space-time visual content in videos is first parsed into object trajectories. Given this video abstraction, COST maintains and tracks object-associated dialog states, which are updated upon receiving new questions. Object interactions are dynamically and conditionally inferred for each question, and these serve as the basis for relational reasoning among them. COST also maintains a history of previous answers, and this allows retrieval of relevant object-centric information to enrich the answer forming process. Language production then proceeds in a step-wise manner, taking into the context of the current utterance, the existing dialog, the current question. We evaluate COST on the DSTC7 and DSTC8 benchmarks, demonstrating its competitiveness against state-of-the-arts.
Guiding Visual Question Answering with Attention Priors
May 25, 2022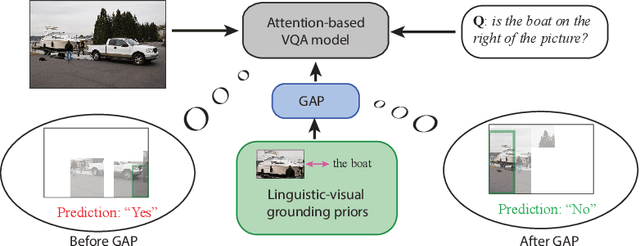
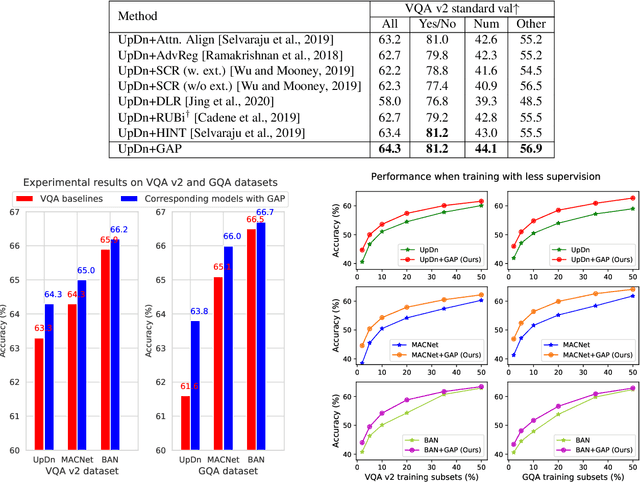
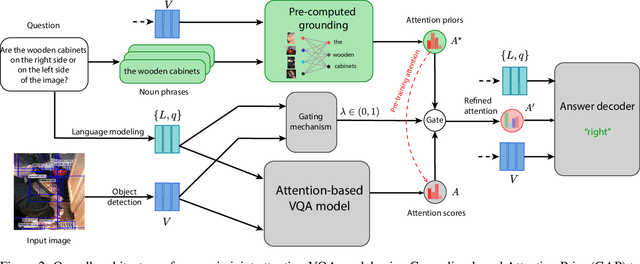

The current success of modern visual reasoning systems is arguably attributed to cross-modality attention mechanisms. However, in deliberative reasoning such as in VQA, attention is unconstrained at each step, and thus may serve as a statistical pooling mechanism rather than a semantic operation intended to select information relevant to inference. This is because at training time, attention is only guided by a very sparse signal (i.e. the answer label) at the end of the inference chain. This causes the cross-modality attention weights to deviate from the desired visual-language bindings. To rectify this deviation, we propose to guide the attention mechanism using explicit linguistic-visual grounding. This grounding is derived by connecting structured linguistic concepts in the query to their referents among the visual objects. Here we learn the grounding from the pairing of questions and images alone, without the need for answer annotation or external grounding supervision. This grounding guides the attention mechanism inside VQA models through a duality of mechanisms: pre-training attention weight calculation and directly guiding the weights at inference time on a case-by-case basis. The resultant algorithm is capable of probing attention-based reasoning models, injecting relevant associative knowledge, and regulating the core reasoning process. This scalable enhancement improves the performance of VQA models, fortifies their robustness to limited access to supervised data, and increases interpretability.
Hierarchical Object-oriented Spatio-Temporal Reasoning for Video Question Answering
Jun 25, 2021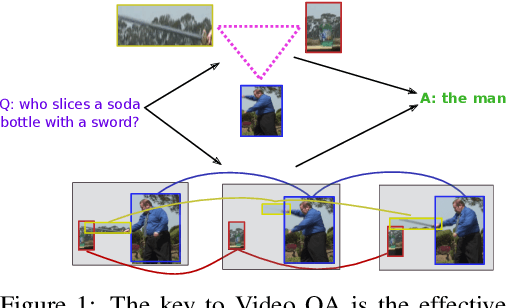
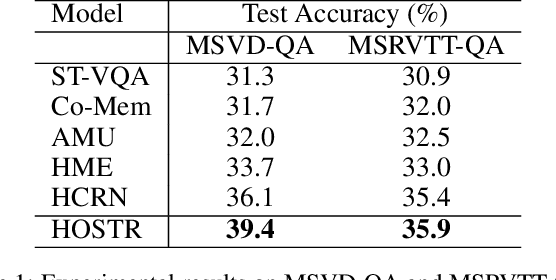

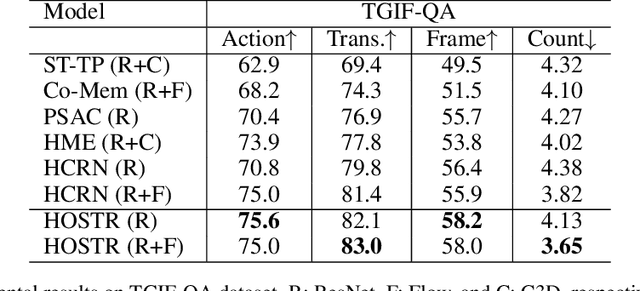
Video Question Answering (Video QA) is a powerful testbed to develop new AI capabilities. This task necessitates learning to reason about objects, relations, and events across visual and linguistic domains in space-time. High-level reasoning demands lifting from associative visual pattern recognition to symbol-like manipulation over objects, their behavior and interactions. Toward reaching this goal we propose an object-oriented reasoning approach in that video is abstracted as a dynamic stream of interacting objects. At each stage of the video event flow, these objects interact with each other, and their interactions are reasoned about with respect to the query and under the overall context of a video. This mechanism is materialized into a family of general-purpose neural units and their multi-level architecture called Hierarchical Object-oriented Spatio-Temporal Reasoning (HOSTR) networks. This neural model maintains the objects' consistent lifelines in the form of a hierarchically nested spatio-temporal graph. Within this graph, the dynamic interactive object-oriented representations are built up along the video sequence, hierarchically abstracted in a bottom-up manner, and converge toward the key information for the correct answer. The method is evaluated on multiple major Video QA datasets and establishes new state-of-the-arts in these tasks. Analysis into the model's behavior indicates that object-oriented reasoning is a reliable, interpretable and efficient approach to Video QA.