 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised 3D Semantic Scene Completion with 2D Vision Foundation Model Guidance
Aug 21, 2024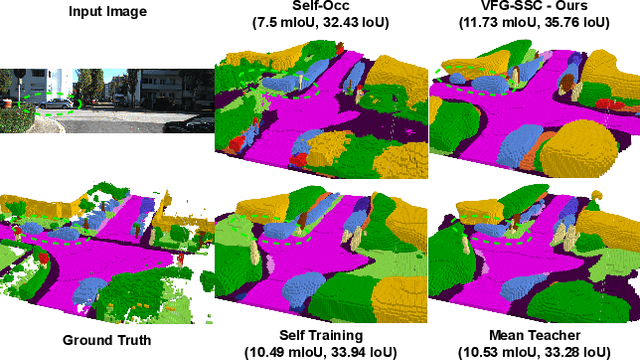
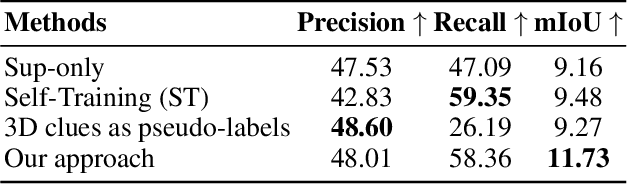
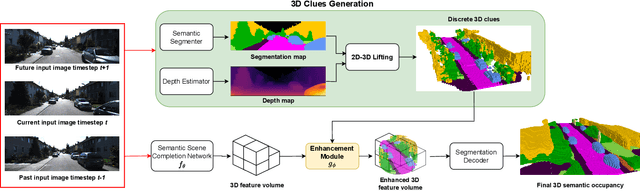
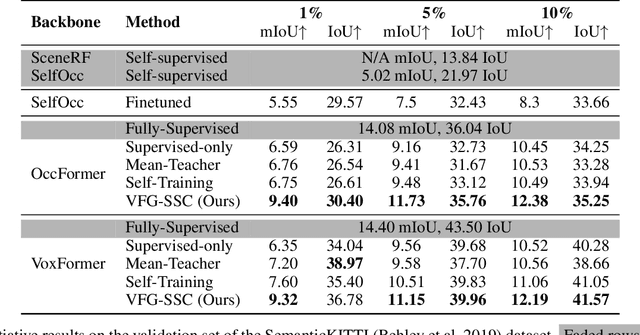
Accurate prediction of 3D semantic occupancy from 2D visual images is vital in enabling autonomous agents to comprehend their surroundings for planning and navigation. State-of-the-art methods typically employ fully supervised approaches, necessitating a huge labeled dataset acquired through expensive LiDAR sensors and meticulous voxel-wise labeling by human annotators. The resource-intensive nature of this annotating process significantly hampers the application and scalability of these methods. We introduce a novel semi-supervised framework to alleviate the dependency on densely annotated data. Our approach leverages 2D foundation models to generate essential 3D scene geometric and semantic cues, facilitating a more efficient training process. Our framework exhibits notable properties: (1) Generalizability, applicable to various 3D semantic scene completion approaches, including 2D-3D lifting and 3D-2D transformer methods. (2) Effectiveness, as demonstrated through experiments on SemanticKITTI and NYUv2, wherein our method achieves up to 85% of the fully-supervised performance using only 10% labeled data. This approach not only reduces the cost and labor associated with data annotation but also demonstrates the potential for broader adoption in camera-based systems for 3D semantic occupancy prediction.
Video Dialog as Conversation about Objects Living in Space-Time
Jul 08, 2022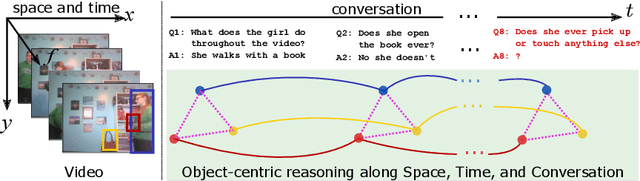

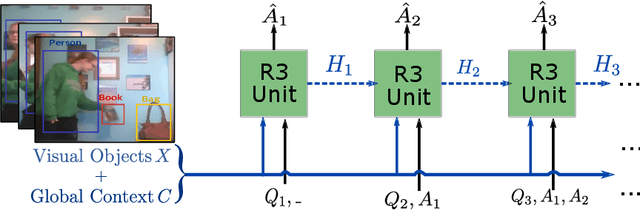
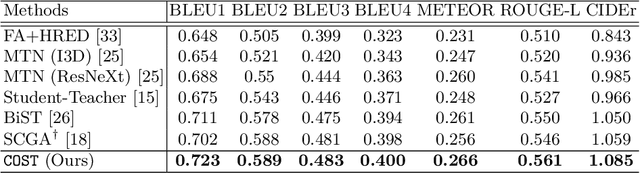
It would be a technological feat to be able to create a system that can hold a meaningful conversation with humans about what they watch. A setup toward that goal is presented as a video dialog task, where the system is asked to generate natural utterances in response to a question in an ongoing dialog. The task poses great visual, linguistic, and reasoning challenges that cannot be easily overcome without an appropriate representation scheme over video and dialog that supports high-level reasoning. To tackle these challenges we present a new object-centric framework for video dialog that supports neural reasoning dubbed COST - which stands for Conversation about Objects in Space-Time. Here dynamic space-time visual content in videos is first parsed into object trajectories. Given this video abstraction, COST maintains and tracks object-associated dialog states, which are updated upon receiving new questions. Object interactions are dynamically and conditionally inferred for each question, and these serve as the basis for relational reasoning among them. COST also maintains a history of previous answers, and this allows retrieval of relevant object-centric information to enrich the answer forming process. Language production then proceeds in a step-wise manner, taking into the context of the current utterance, the existing dialog, the current question. We evaluate COST on the DSTC7 and DSTC8 benchmarks, demonstrating its competitiveness against state-of-the-arts.