 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiftRefine: Progressively Refined View Synthesis from 3D Lifting with Volume-Triplane Representations
Dec 19, 2024

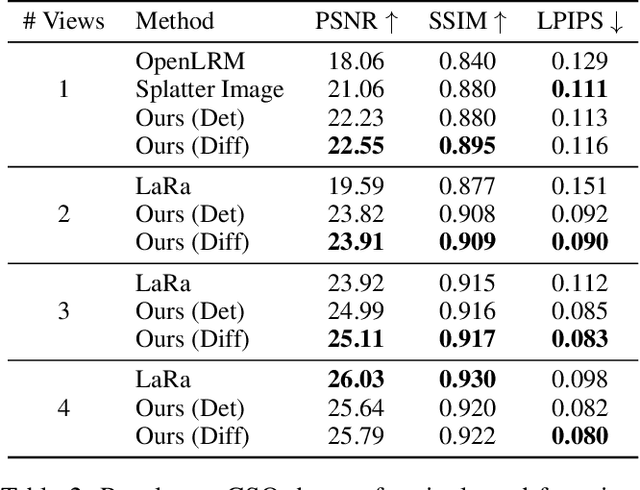

We propose a new view synthesis method via synthesizing a 3D neural field from both single or few-view input images. To address the ill-posed nature of the image-to-3D generation problem, we devise a two-stage method that involves a reconstruction model and a diffusion model for view synthesis. Our reconstruction model first lifts one or more input images to the 3D space from a volume as the coarse-scale 3D representation followed by a tri-plane as the fine-scale 3D representation. To mitigate the ambiguity in occluded regions, our diffusion model then hallucinates missing details in the rendered images from tri-planes. We then introduce a new progressive refinement technique that iteratively applies the reconstruction and diffusion model to gradually synthesize novel views, boosting the overall quality of the 3D representations and their rendering. Empirical evaluation demonstrates the superiority of our method over state-of-the-art methods on the synthetic SRN-Car dataset, the in-the-wild CO3D dataset, and large-scale Objaverse dataset while achieving both sampling efficacy and multi-view consistency.
SwiftTry: Fast and Consistent Video Virtual Try-On with Diffusion Models
Dec 13, 2024



Given an input video of a person and a new garment, the objective of this paper is to synthesize a new video where the person is wearing the specified garment while maintaining spatiotemporal consistency. While significant advances have been made in image-based virtual try-ons, extending these successes to video often results in frame-to-frame inconsistencies. Some approaches have attempted to address this by increasing the overlap of frames across multiple video chunks, but this comes at a steep computational cost due to the repeated processing of the same frames, especially for long video sequence. To address these challenges, we reconceptualize video virtual try-on as a conditional video inpainting task, with garments serving as input conditions. Specifically, our approach enhances image diffusion models by incorporating temporal attention layers to improve temporal coherence. To reduce computational overhead, we introduce ShiftCaching, a novel technique that maintains temporal consistency while minimizing redundant computations. Furthermore, we introduce the \dataname~dataset, a new video try-on dataset featuring more complex backgrounds, challenging movements, and higher resolution compared to existing public datasets. Extensive experiments show that our approach outperforms current baselines, particularly in terms of video consistency and inference speed. Data and code are available at https://github.com/VinAIResearch/swift-try
SharpDepth: Sharpening Metric Depth Predictions Using Diffusion Distillation
Nov 27, 2024

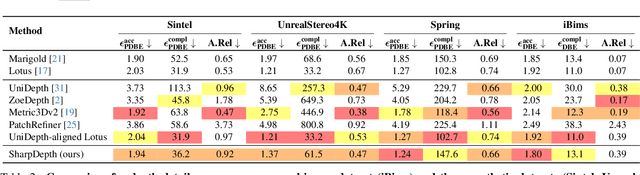

We propose SharpDepth, a novel approach to monocular metric depth estimation that combines the metric accuracy of discriminative depth estimation methods (e.g., Metric3D, UniDepth) with the fine-grained boundary sharpness typically achieved by generative methods (e.g., Marigold, Lotus). Traditional discriminative models trained on real-world data with sparse ground-truth depth can accurately predict metric depth but often produce over-smoothed or low-detail depth maps. Generative models, in contrast, are trained on synthetic data with dense ground truth, generating depth maps with sharp boundaries yet only providing relative depth with low accuracy. Our approach bridges these limitations by integrating metric accuracy with detailed boundary preservation, resulting in depth predictions that are both metrically precise and visually sharp. Our extensive zero-shot evaluations on standard depth estimation benchmarks confirm SharpDepth effectiveness, showing its ability to achieve both high depth accuracy and detailed representation, making it well-suited for applications requiring high-quality depth perception across diverse, real-world environments.
Semi-supervised 3D Semantic Scene Completion with 2D Vision Foundation Model Guidance
Aug 21, 2024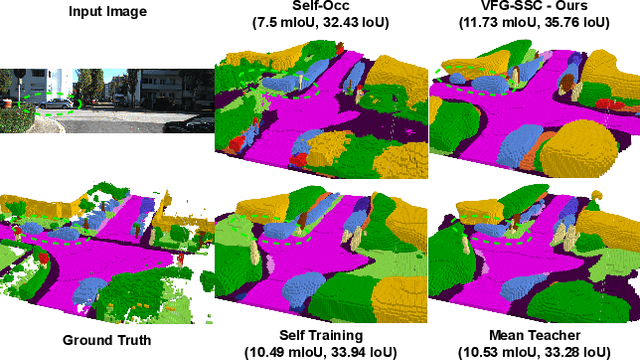
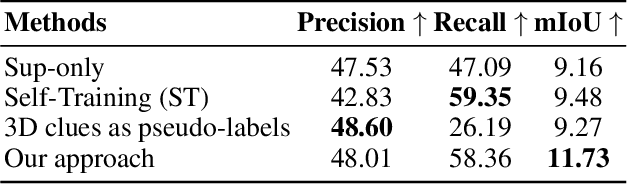
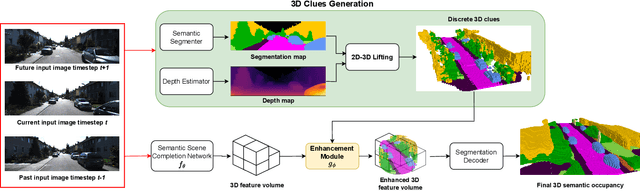
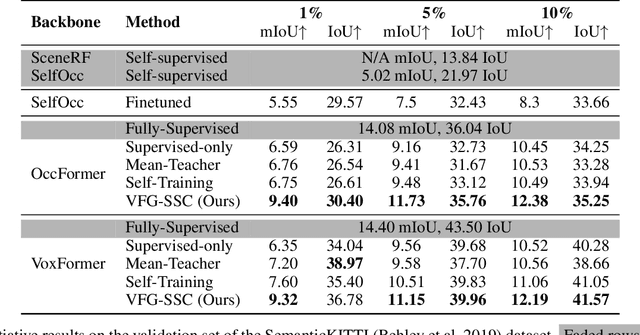
Accurate prediction of 3D semantic occupancy from 2D visual images is vital in enabling autonomous agents to comprehend their surroundings for planning and navigation. State-of-the-art methods typically employ fully supervised approaches, necessitating a huge labeled dataset acquired through expensive LiDAR sensors and meticulous voxel-wise labeling by human annotators. The resource-intensive nature of this annotating process significantly hampers the application and scalability of these methods. We introduce a novel semi-supervised framework to alleviate the dependency on densely annotated data. Our approach leverages 2D foundation models to generate essential 3D scene geometric and semantic cues, facilitating a more efficient training process. Our framework exhibits notable properties: (1) Generalizability, applicable to various 3D semantic scene completion approaches, including 2D-3D lifting and 3D-2D transformer methods. (2) Effectiveness, as demonstrated through experiments on SemanticKITTI and NYUv2, wherein our method achieves up to 85% of the fully-supervised performance using only 10% labeled data. This approach not only reduces the cost and labor associated with data annotation but also demonstrates the potential for broader adoption in camera-based systems for 3D semantic occupancy prediction.
Blur2Blur: Blur Conversion for Unsupervised Image Deblurring on Unknown Domains
Mar 24, 2024

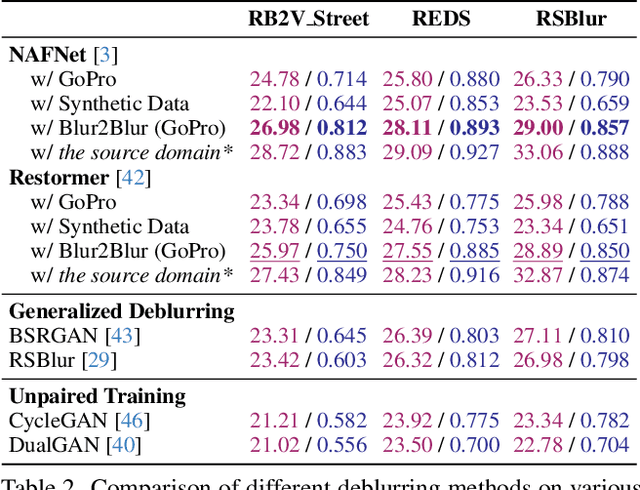

This paper presents an innovative framework designed to train an image deblurring algorithm tailored to a specific camera device. This algorithm works by transforming a blurry input image, which is challenging to deblur, into another blurry image that is more amenable to deblurring. The transformation process, from one blurry state to another, leverages unpaired data consisting of sharp and blurry images captured by the target camera device. Learning this blur-to-blur transformation is inherently simpler than direct blur-to-sharp conversion, as it primarily involves modifying blur patterns rather than the intricate task of reconstructing fine image details. The efficacy of the proposed approach has been demonstrated through comprehensive experiments on various benchmarks, where it significantly outperforms state-of-the-art methods both quantitatively and qualitatively. Our code and data are available at https://zero1778.github.io/blur2blur/
HyperCUT: Video Sequence from a Single Blurry Image using Unsupervised Ordering
Apr 05, 2023
We consider the challenging task of training models for image-to-video deblurring, which aims to recover a sequence of sharp images corresponding to a given blurry image input. A critical issue disturbing the training of an image-to-video model is the ambiguity of the frame ordering since both the forward and backward sequences are plausible solutions. This paper proposes an effective self-supervised ordering scheme that allows training high-quality image-to-video deblurring models. Unlike previous methods that rely on order-invariant losses, we assign an explicit order for each video sequence, thus avoiding the order-ambiguity issue. Specifically, we map each video sequence to a vector in a latent high-dimensional space so that there exists a hyperplane such that for every video sequence, the vectors extracted from it and its reversed sequence are on different sides of the hyperplane. The side of the vectors will be used to define the order of the corresponding sequence. Last but not least, we propose a real-image dataset for the image-to-video deblurring problem that covers a variety of popular domains, including face, hand, and street. Extensive experimental results confirm the effectiveness of our method. Code and data are available at https://github.com/VinAIResearch/HyperCUT.git
Single-Image HDR Reconstruction by Multi-Exposure Generation
Oct 28, 2022High dynamic range (HDR) imaging is an indispensable technique in modern photography. Traditional methods focus on HDR reconstruction from multiple images, solving the core problems of image alignment, fusion, and tone mapping, yet having a perfect solution due to ghosting and other visual artifacts in the reconstruction. Recent attempts at single-image HDR reconstruction show a promising alternative: by learning to map pixel values to their irradiance using a neural network, one can bypass the align-and-merge pipeline completely yet still obtain a high-quality HDR image. In this work, we propose a weakly supervised learning method that inverts the physical image formation process for HDR reconstruction via learning to generate multiple exposures from a single image. Our neural network can invert the camera response to reconstruct pixel irradiance before synthesizing multiple exposures and hallucinating details in under- and over-exposed regions from a single input image. To train the network, we propose a representation loss, a reconstruction loss, and a perceptual loss applied on pairs of under- and over-exposure images and thus do not require HDR images for training. Our experiments show that our proposed model can effectively reconstruct HDR images. Our qualitative and quantitative results show that our method achieves state-of-the-art performance on the DrTMO dataset. Our code is available at https://github.com/VinAIResearch/single_image_hdr.
PSENet: Progressive Self-Enhancement Network for Unsupervised Extreme-Light Image Enhancement
Oct 03, 2022
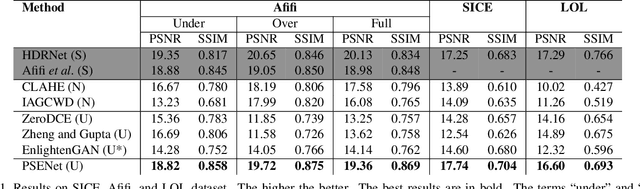


The extremes of lighting (e.g. too much or too little light) usually cause many troubles for machine and human vision. Many recent works have mainly focused on under-exposure cases where images are often captured in low-light conditions (e.g. nighttime) and achieved promising results for enhancing the quality of images. However, they are inferior to handling images under over-exposure. To mitigate this limitation, we propose a novel unsupervised enhancement framework which is robust against various lighting conditions while does not require any well-exposed images to serve as the ground-truths. Our main concept is to construct pseudo-ground-truth images synthesized from multiple source images that simulate all potential exposure scenarios to train the enhancement network. Our extensive experiments show that the proposed approach consistently outperforms the current state-of-the-art unsupervised counterparts in several public datasets in terms of both quantitative metrics and qualitative results. Our code is available at https://github.com/VinAIResearch/PSENet-Image-Enhancement.
Inductive and Transductive Few-Shot Video Classification via Appearance and Temporal Alignments
Jul 21, 2022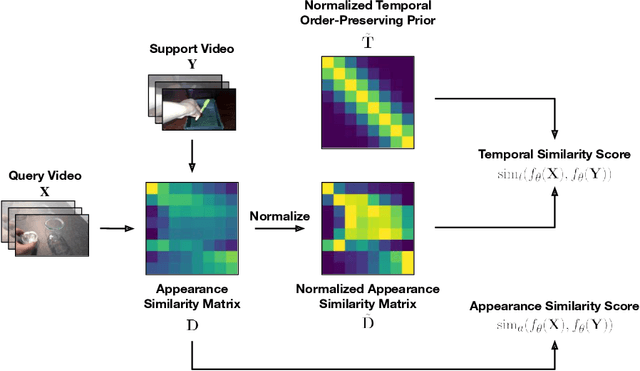



We present a novel method for few-shot video classification, which performs appearance and temporal alignments. In particular, given a pair of query and support videos, we conduct appearance alignment via frame-level feature matching to achieve the appearance similarity score between the videos, while utilizing temporal order-preserving priors for obtaining the temporal similarity score between the videos. Moreover, we introduce a few-shot video classification framework that leverages the above appearance and temporal similarity scores across multiple steps, namely prototype-based training and testing as well as inductive and transductive prototype refinement. To the best of our knowledge, our work is the first to explore transductive few-shot video classification. Extensive experiments on both Kinetics and Something-Something V2 datasets show that both appearance and temporal alignments are crucial for datasets with temporal order sensitivity such as Something-Something V2. Our approach achieves similar or better results than previous methods on both datasets. Our code is available at https://github.com/VinAIResearch/fsvc-ata.
POODLE: Improving Few-shot Learning via Penalizing Out-of-Distribution Samples
Jun 08, 2022


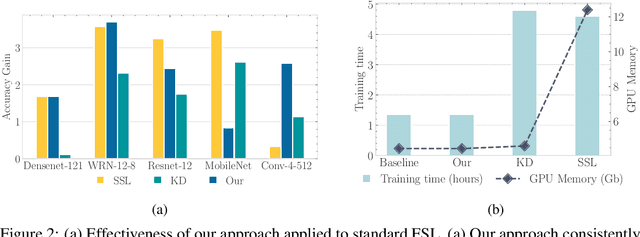
In this work, we propose to use out-of-distribution samples, i.e., unlabeled samples coming from outside the target classes, to improve few-shot learning. Specifically, we exploit the easily available out-of-distribution samples to drive the classifier to avoid irrelevant features by maximizing the distance from prototypes to out-of-distribution samples while minimizing that of in-distribution samples (i.e., support, query data). Our approach is simple to implement, agnostic to feature extractors, lightweight without any additional cost for pre-training, and applicable to both inductive and transductive settings. Extensive experiments on various standard benchmarks demonstrate that the proposed method consistently improves the performance of pretrained networks with different architectures.