 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffPortrait360: Consistent Portrait Diffusion for 360 View Synthesis
Mar 19, 2025



Generating high-quality 360-degree views of human heads from single-view images is essential for enabling accessible immersive telepresence applications and scalable personalized content creation. While cutting-edge methods for full head generation are limited to modeling realistic human heads, the latest diffusion-based approaches for style-omniscient head synthesis can produce only frontal views and struggle with view consistency, preventing their conversion into true 3D models for rendering from arbitrary angles. We introduce a novel approach that generates fully consistent 360-degree head views, accommodating human, stylized, and anthropomorphic forms, including accessories like glasses and hats. Our method builds on the DiffPortrait3D framework, incorporating a custom ControlNet for back-of-head detail generation and a dual appearance module to ensure global front-back consistency. By training on continuous view sequences and integrating a back reference image, our approach achieves robust, locally continuous view synthesis. Our model can be used to produce high-quality neural radiance fields (NeRFs) for real-time, free-viewpoint rendering, outperforming state-of-the-art methods in object synthesis and 360-degree head generation for very challenging input portraits.
VOODOO XP: Expressive One-Shot Head Reenactment for VR Telepresence
May 28, 2024We introduce VOODOO XP: a 3D-aware one-shot head reenactment method that can generate highly expressive facial expressions from any input driver video and a single 2D portrait. Our solution is real-time, view-consistent, and can be instantly used without calibration or fine-tuning. We demonstrate our solution on a monocular video setting and an end-to-end VR telepresence system for two-way communication. Compared to 2D head reenactment methods, 3D-aware approaches aim to preserve the identity of the subject and ensure view-consistent facial geometry for novel camera poses, which makes them suitable for immersive applications. While various facial disentanglement techniques have been introduced, cutting-edge 3D-aware neural reenactment techniques still lack expressiveness and fail to reproduce complex and fine-scale facial expressions. We present a novel cross-reenactment architecture that directly transfers the driver's facial expressions to transformer blocks of the input source's 3D lifting module. We show that highly effective disentanglement is possible using an innovative multi-stage self-supervision approach, which is based on a coarse-to-fine strategy, combined with an explicit face neutralization and 3D lifted frontalization during its initial training stage. We further integrate our novel head reenactment solution into an accessible high-fidelity VR telepresence system, where any person can instantly build a personalized neural head avatar from any photo and bring it to life using the headset. We demonstrate state-of-the-art performance in terms of expressiveness and likeness preservation on a large set of diverse subjects and capture conditions.
Blur2Blur: Blur Conversion for Unsupervised Image Deblurring on Unknown Domains
Mar 24, 2024

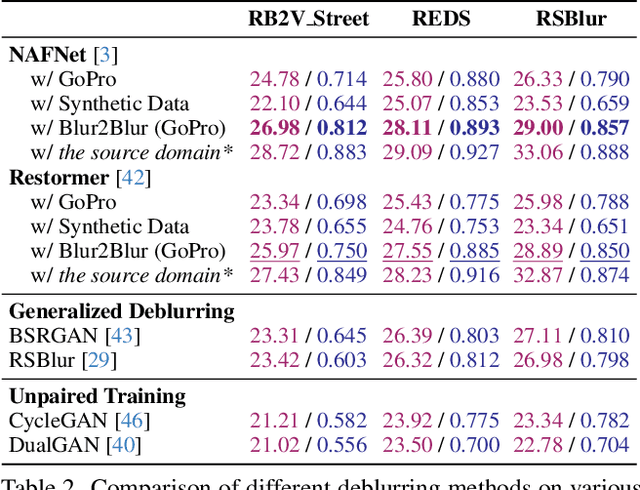

This paper presents an innovative framework designed to train an image deblurring algorithm tailored to a specific camera device. This algorithm works by transforming a blurry input image, which is challenging to deblur, into another blurry image that is more amenable to deblurring. The transformation process, from one blurry state to another, leverages unpaired data consisting of sharp and blurry images captured by the target camera device. Learning this blur-to-blur transformation is inherently simpler than direct blur-to-sharp conversion, as it primarily involves modifying blur patterns rather than the intricate task of reconstructing fine image details. The efficacy of the proposed approach has been demonstrated through comprehensive experiments on various benchmarks, where it significantly outperforms state-of-the-art methods both quantitatively and qualitatively. Our code and data are available at https://zero1778.github.io/blur2blur/
VOODOO 3D: Volumetric Portrait Disentanglement for One-Shot 3D Head Reenactment
Dec 07, 2023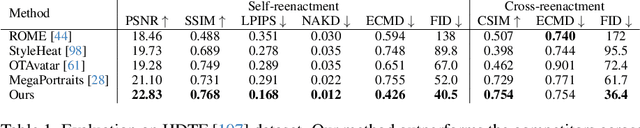
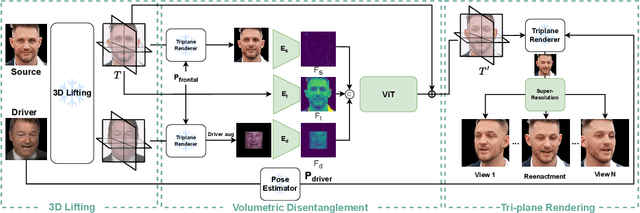
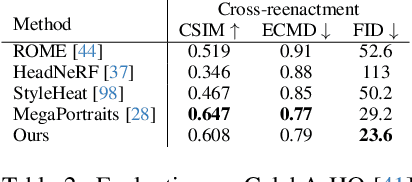

We present a 3D-aware one-shot head reenactment method based on a fully volumetric neural disentanglement framework for source appearance and driver expressions. Our method is real-time and produces high-fidelity and view-consistent output, suitable for 3D teleconferencing systems based on holographic displays. Existing cutting-edge 3D-aware reenactment methods often use neural radiance fields or 3D meshes to produce view-consistent appearance encoding, but, at the same time, they rely on linear face models, such as 3DMM, to achieve its disentanglement with facial expressions. As a result, their reenactment results often exhibit identity leakage from the driver or have unnatural expressions. To address these problems, we propose a neural self-supervised disentanglement approach that lifts both the source image and driver video frame into a shared 3D volumetric representation based on tri-planes. This representation can then be freely manipulated with expression tri-planes extracted from the driving images and rendered from an arbitrary view using neural radiance fields. We achieve this disentanglement via self-supervised learning on a large in-the-wild video dataset. We further introduce a highly effective fine-tuning approach to improve the generalizability of the 3D lifting using the same real-world data. We demonstrate state-of-the-art performance on a wide range of datasets, and also showcase high-quality 3D-aware head reenactment on highly challenging and diverse subjects, including non-frontal head poses and complex expressions for both source and driver.
Simple Transferability Estimation for Regression Tasks
Dec 04, 2023
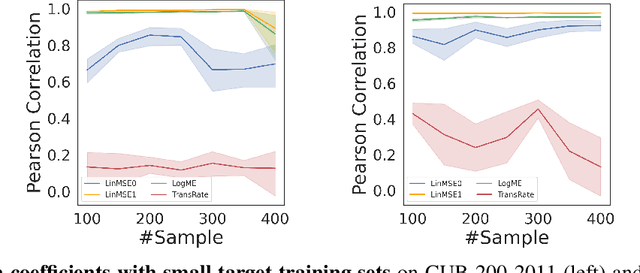
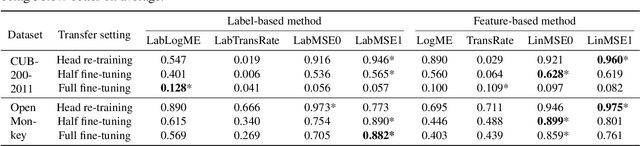
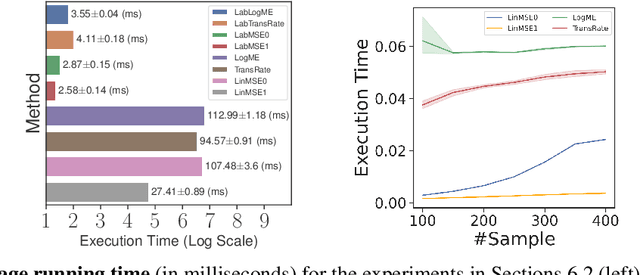
We consider transferability estimation, the problem of estimating how well deep learning models transfer from a source to a target task. We focus on regression tasks, which received little previous attention, and propose two simple and computationally efficient approaches that estimate transferability based on the negative regularized mean squared error of a linear regression model. We prove novel theoretical results connecting our approaches to the actual transferability of the optimal target models obtained from the transfer learning process. Despite their simplicity, our approaches significantly outperform existing state-of-the-art regression transferability estimators in both accuracy and efficiency. On two large-scale keypoint regression benchmarks, our approaches yield 12% to 36% better results on average while being at least 27% faster than previous state-of-the-art methods.
HyperCUT: Video Sequence from a Single Blurry Image using Unsupervised Ordering
Apr 05, 2023
We consider the challenging task of training models for image-to-video deblurring, which aims to recover a sequence of sharp images corresponding to a given blurry image input. A critical issue disturbing the training of an image-to-video model is the ambiguity of the frame ordering since both the forward and backward sequences are plausible solutions. This paper proposes an effective self-supervised ordering scheme that allows training high-quality image-to-video deblurring models. Unlike previous methods that rely on order-invariant losses, we assign an explicit order for each video sequence, thus avoiding the order-ambiguity issue. Specifically, we map each video sequence to a vector in a latent high-dimensional space so that there exists a hyperplane such that for every video sequence, the vectors extracted from it and its reversed sequence are on different sides of the hyperplane. The side of the vectors will be used to define the order of the corresponding sequence. Last but not least, we propose a real-image dataset for the image-to-video deblurring problem that covers a variety of popular domains, including face, hand, and street. Extensive experimental results confirm the effectiveness of our method. Code and data are available at https://github.com/VinAIResearch/HyperCUT.git
Explore Image Deblurring via Blur Kernel Space
Apr 03, 2021

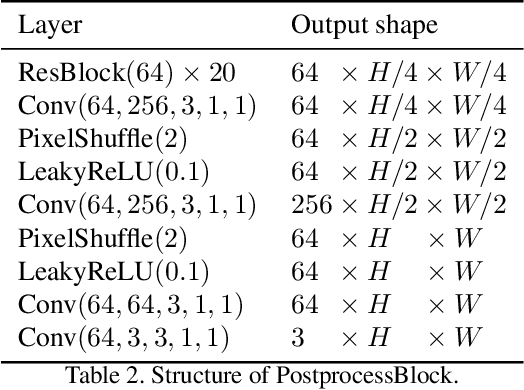

This paper introduces a method to encode the blur operators of an arbitrary dataset of sharp-blur image pairs into a blur kernel space. Assuming the encoded kernel space is close enough to in-the-wild blur operators, we propose an alternating optimization algorithm for blind image deblurring. It approximates an unseen blur operator by a kernel in the encoded space and searches for the corresponding sharp image. Unlike recent deep-learning-based methods, our system can handle unseen blur kernel, while avoiding using complicated handcrafted priors on the blur operator often found in classical methods. Due to the method's design, the encoded kernel space is fully differentiable, thus can be easily adopted in deep neural network models. Moreover, our method can be used for blur synthesis by transferring existing blur operators from a given dataset into a new domain. Finally, we provide experimental results to confirm the effectiveness of the proposed method.
FineNet: Frame Interpolation and Enhancement for Face Video Deblurring
Mar 01, 2021
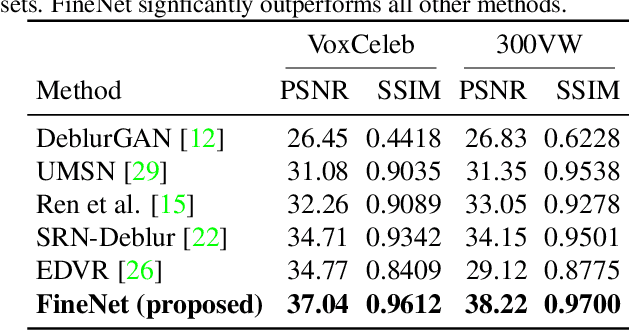


The objective of this work is to deblur face videos. We propose a method that tackles this problem from two directions: (1) enhancing the blurry frames, and (2) treating the blurry frames as missing values and estimate them by interpolation. These approaches are complementary to each other, and their combination outperforms individual ones. We also introduce a novel module that leverages the structure of faces for finding positional offsets between video frames. This module can be integrated into the processing pipelines of both approaches, improving the quality of the final outcome. Experiments on three real and synthetically generated blurry video datasets show that our method outperforms the previous state-of-the-art methods by a large margin in terms of both quantitative and qualitative results.