 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA4O: All Trigger for One sample
Jan 13, 2025Backdoor attacks have become a critical threat to deep neural networks (DNNs), drawing many research interests. However, most of the studied attacks employ a single type of trigger. Consequently, proposed backdoor defenders often rely on the assumption that triggers would appear in a unified way. In this paper, we show that this naive assumption can create a loophole, allowing more sophisticated backdoor attacks to bypass. We design a novel backdoor attack mechanism that incorporates multiple types of backdoor triggers, focusing on stealthiness and effectiveness. Our journey begins with the intriguing observation that the performance of a backdoor attack in deep learning models, as well as its detectability and removability, are all proportional to the magnitude of the trigger. Based on this correlation, we propose reducing the magnitude of each trigger type and combining them to achieve a strong backdoor relying on the combined trigger while still staying safely under the radar of defenders. Extensive experiments on three standard datasets demonstrate that our method can achieve high attack success rates (ASRs) while consistently bypassing state-of-the-art defenses.
LiftRefine: Progressively Refined View Synthesis from 3D Lifting with Volume-Triplane Representations
Dec 19, 2024

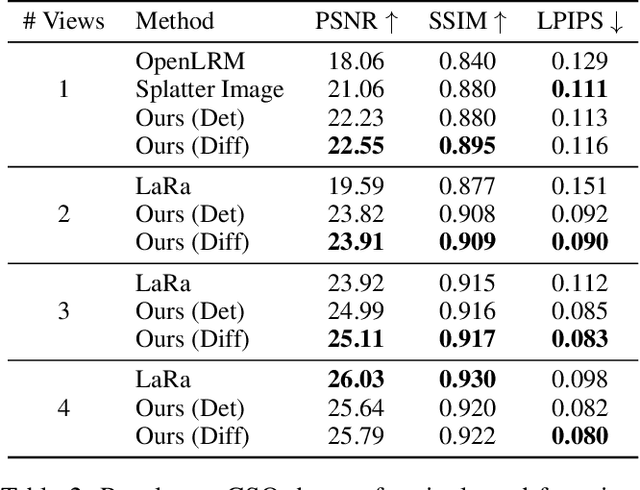

We propose a new view synthesis method via synthesizing a 3D neural field from both single or few-view input images. To address the ill-posed nature of the image-to-3D generation problem, we devise a two-stage method that involves a reconstruction model and a diffusion model for view synthesis. Our reconstruction model first lifts one or more input images to the 3D space from a volume as the coarse-scale 3D representation followed by a tri-plane as the fine-scale 3D representation. To mitigate the ambiguity in occluded regions, our diffusion model then hallucinates missing details in the rendered images from tri-planes. We then introduce a new progressive refinement technique that iteratively applies the reconstruction and diffusion model to gradually synthesize novel views, boosting the overall quality of the 3D representations and their rendering. Empirical evaluation demonstrates the superiority of our method over state-of-the-art methods on the synthetic SRN-Car dataset, the in-the-wild CO3D dataset, and large-scale Objaverse dataset while achieving both sampling efficacy and multi-view consistency.
VOODOO XP: Expressive One-Shot Head Reenactment for VR Telepresence
May 28, 2024We introduce VOODOO XP: a 3D-aware one-shot head reenactment method that can generate highly expressive facial expressions from any input driver video and a single 2D portrait. Our solution is real-time, view-consistent, and can be instantly used without calibration or fine-tuning. We demonstrate our solution on a monocular video setting and an end-to-end VR telepresence system for two-way communication. Compared to 2D head reenactment methods, 3D-aware approaches aim to preserve the identity of the subject and ensure view-consistent facial geometry for novel camera poses, which makes them suitable for immersive applications. While various facial disentanglement techniques have been introduced, cutting-edge 3D-aware neural reenactment techniques still lack expressiveness and fail to reproduce complex and fine-scale facial expressions. We present a novel cross-reenactment architecture that directly transfers the driver's facial expressions to transformer blocks of the input source's 3D lifting module. We show that highly effective disentanglement is possible using an innovative multi-stage self-supervision approach, which is based on a coarse-to-fine strategy, combined with an explicit face neutralization and 3D lifted frontalization during its initial training stage. We further integrate our novel head reenactment solution into an accessible high-fidelity VR telepresence system, where any person can instantly build a personalized neural head avatar from any photo and bring it to life using the headset. We demonstrate state-of-the-art performance in terms of expressiveness and likeness preservation on a large set of diverse subjects and capture conditions.
VOODOO 3D: Volumetric Portrait Disentanglement for One-Shot 3D Head Reenactment
Dec 07, 2023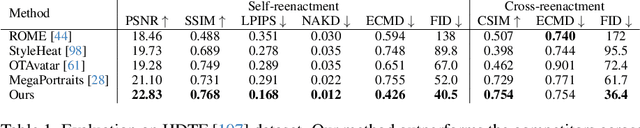
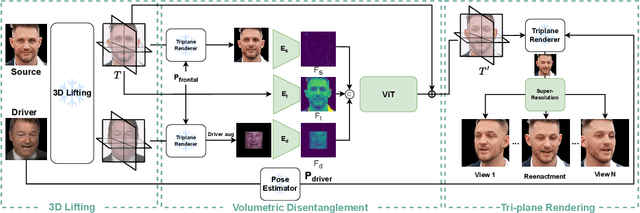
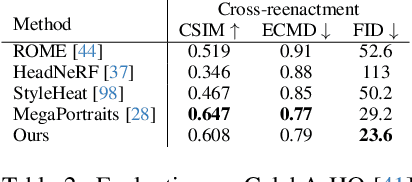

We present a 3D-aware one-shot head reenactment method based on a fully volumetric neural disentanglement framework for source appearance and driver expressions. Our method is real-time and produces high-fidelity and view-consistent output, suitable for 3D teleconferencing systems based on holographic displays. Existing cutting-edge 3D-aware reenactment methods often use neural radiance fields or 3D meshes to produce view-consistent appearance encoding, but, at the same time, they rely on linear face models, such as 3DMM, to achieve its disentanglement with facial expressions. As a result, their reenactment results often exhibit identity leakage from the driver or have unnatural expressions. To address these problems, we propose a neural self-supervised disentanglement approach that lifts both the source image and driver video frame into a shared 3D volumetric representation based on tri-planes. This representation can then be freely manipulated with expression tri-planes extracted from the driving images and rendered from an arbitrary view using neural radiance fields. We achieve this disentanglement via self-supervised learning on a large in-the-wild video dataset. We further introduce a highly effective fine-tuning approach to improve the generalizability of the 3D lifting using the same real-world data. We demonstrate state-of-the-art performance on a wide range of datasets, and also showcase high-quality 3D-aware head reenactment on highly challenging and diverse subjects, including non-frontal head poses and complex expressions for both source and driver.
QC-StyleGAN -- Quality Controllable Image Generation and Manipulation
Dec 07, 2022



The introduction of high-quality image generation models, particularly the StyleGAN family, provides a powerful tool to synthesize and manipulate images. However, existing models are built upon high-quality (HQ) data as desired outputs, making them unfit for in-the-wild low-quality (LQ) images, which are common inputs for manipulation. In this work, we bridge this gap by proposing a novel GAN structure that allows for generating images with controllable quality. The network can synthesize various image degradation and restore the sharp image via a quality control code. Our proposed QC-StyleGAN can directly edit LQ images without altering their quality by applying GAN inversion and manipulation techniques. It also provides for free an image restoration solution that can handle various degradations, including noise, blur, compression artifacts, and their mixtures. Finally, we demonstrate numerous other applications such as image degradation synthesis, transfer, and interpolation. The code is available at https://github.com/VinAIResearch/QC-StyleGAN.
Self-Supervised Learning with Multi-View Rendering for 3D Point Cloud Analysis
Oct 28, 2022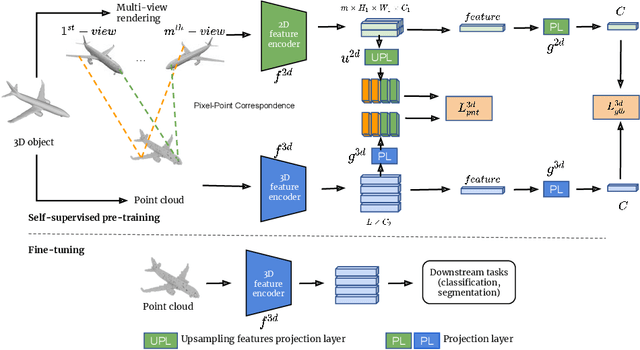
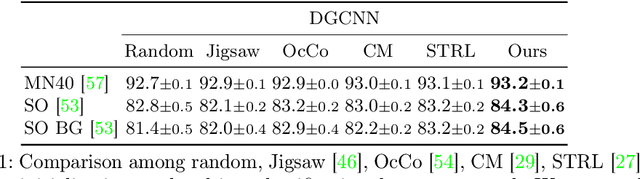
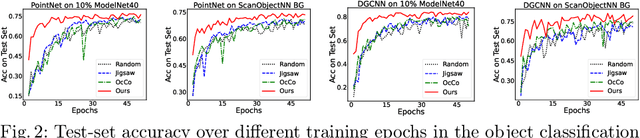
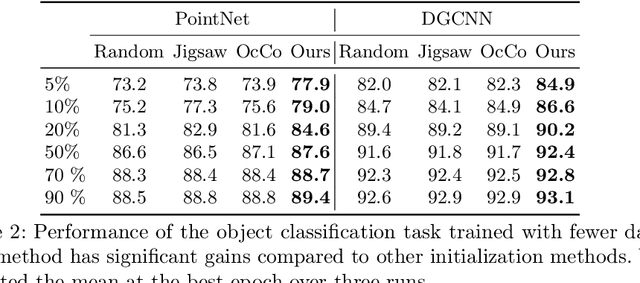
Recently, great progress has been made in 3D deep learning with the emergence of deep neural networks specifically designed for 3D point clouds. These networks are often trained from scratch or from pre-trained models learned purely from point cloud data. Inspired by the success of deep learning in the image domain, we devise a novel pre-training technique for better model initialization by utilizing the multi-view rendering of the 3D data. Our pre-training is self-supervised by a local pixel/point level correspondence loss computed from perspective projection and a global image/point cloud level loss based on knowledge distillation, thus effectively improving upon popular point cloud networks, including PointNet, DGCNN and SR-UNet. These improved models outperform existing state-of-the-art methods on various datasets and downstream tasks. We also analyze the benefits of synthetic and real data for pre-training, and observe that pre-training on synthetic data is also useful for high-level downstream tasks. Code and pre-trained models are available at https://github.com/VinAIResearch/selfsup_pcd.
Knowledge Augmented Machine Learning with Applications in Autonomous Driving: A Survey
May 10, 2022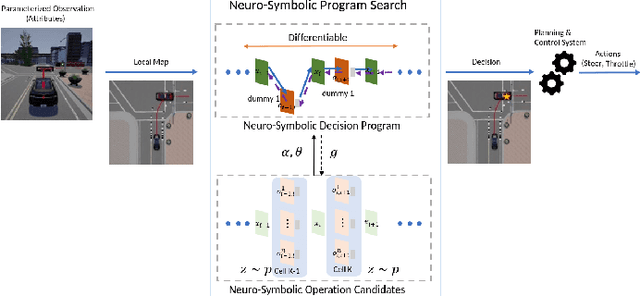
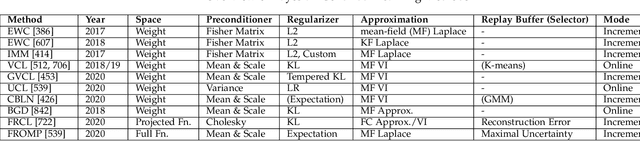
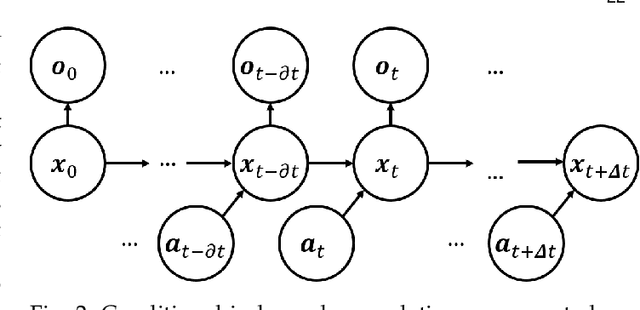
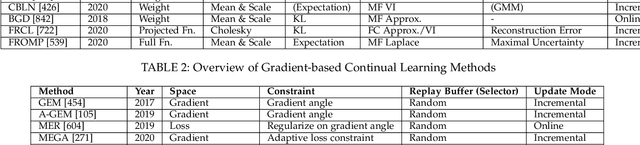
The existence of representative datasets is a prerequisite of many successful artificial intelligence and machine learning models. However, the subsequent application of these models often involves scenarios that are inadequately represented in the data used for training. The reasons for this are manifold and range from time and cost constraints to ethical considerations. As a consequence, the reliable use of these models, especially in safety-critical applications, is a huge challenge. Leveraging additional, already existing sources of knowledge is key to overcome the limitations of purely data-driven approaches, and eventually to increase the generalization capability of these models. Furthermore, predictions that conform with knowledge are crucial for making trustworthy and safe decisions even in underrepresented scenarios. This work provides an overview of existing techniques and methods in the literature that combine data-based models with existing knowledge. The identified approaches are structured according to the categories integration, extraction and conformity. Special attention is given to applications in the field of autonomous driving.
HyperInverter: Improving StyleGAN Inversion via Hypernetwork
Dec 01, 2021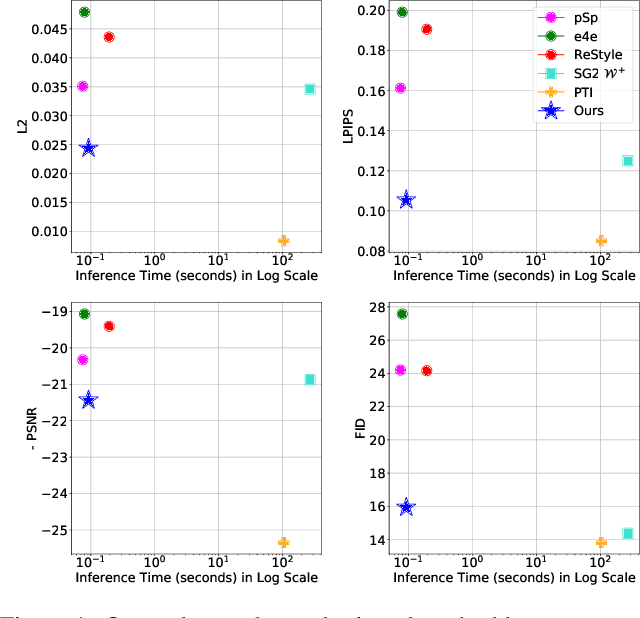
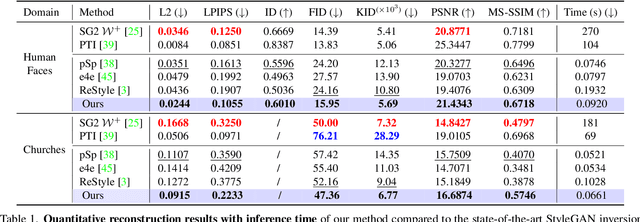
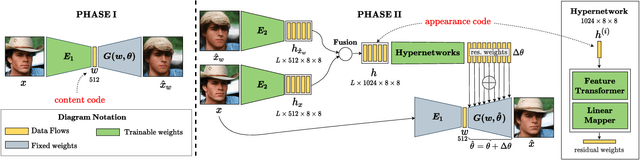
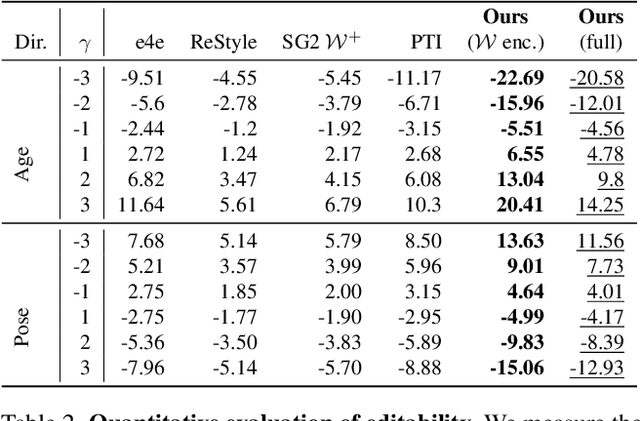
Real-world image manipulation has achieved fantastic progress in recent years as a result of the exploration and utilization of GAN latent spaces. GAN inversion is the first step in this pipeline, which aims to map the real image to the latent code faithfully. Unfortunately, the majority of existing GAN inversion methods fail to meet at least one of the three requirements listed below: high reconstruction quality, editability, and fast inference. We present a novel two-phase strategy in this research that fits all requirements at the same time. In the first phase, we train an encoder to map the input image to StyleGAN2 $\mathcal{W}$-space, which was proven to have excellent editability but lower reconstruction quality. In the second phase, we supplement the reconstruction ability in the initial phase by leveraging a series of hypernetworks to recover the missing information during inversion. These two steps complement each other to yield high reconstruction quality thanks to the hypernetwork branch and excellent editability due to the inversion done in the $\mathcal{W}$-space. Our method is entirely encoder-based, resulting in extremely fast inference. Extensive experiments on two challenging datasets demonstrate the superiority of our method.
Exploiting Domain-Specific Features to Enhance Domain Generalization
Oct 18, 2021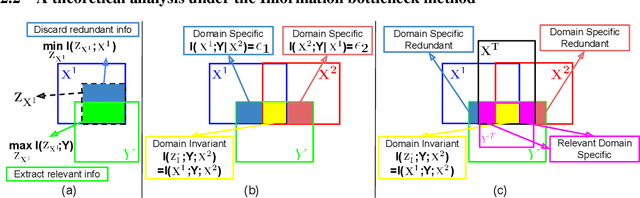


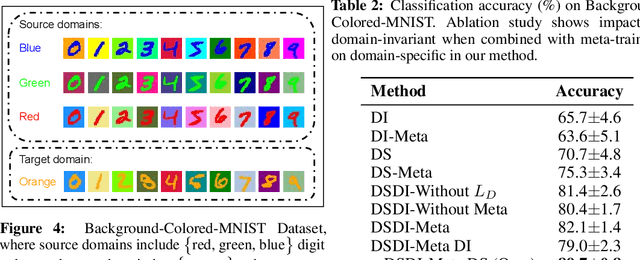
Domain Generalization (DG) aims to train a model, from multiple observed source domains, in order to perform well on unseen target domains. To obtain the generalization capability, prior DG approaches have focused on extracting domain-invariant information across sources to generalize on target domains, while useful domain-specific information which strongly correlates with labels in individual domains and the generalization to target domains is usually ignored. In this paper, we propose meta-Domain Specific-Domain Invariant (mDSDI) - a novel theoretically sound framework that extends beyond the invariance view to further capture the usefulness of domain-specific information. Our key insight is to disentangle features in the latent space while jointly learning both domain-invariant and domain-specific features in a unified framework. The domain-specific representation is optimized through the meta-learning framework to adapt from source domains, targeting a robust generalization on unseen domains. We empirically show that mDSDI provides competitive results with state-of-the-art techniques in DG. A further ablation study with our generated dataset, Background-Colored-MNIST, confirms the hypothesis that domain-specific is essential, leading to better results when compared with only using domain-invariant.
Toward Realistic Single-View 3D Object Reconstruction with Unsupervised Learning from Multiple Images
Sep 07, 2021
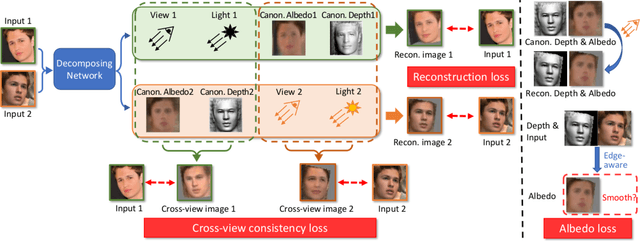
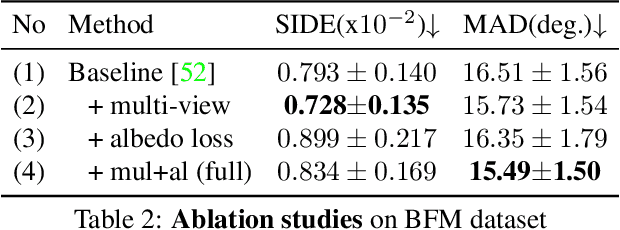

Recovering the 3D structure of an object from a single image is a challenging task due to its ill-posed nature. One approach is to utilize the plentiful photos of the same object category to learn a strong 3D shape prior for the object. This approach has successfully been demonstrated by a recent work of Wu et al. (2020), which obtained impressive 3D reconstruction networks with unsupervised learning. However, their algorithm is only applicable to symmetric objects. In this paper, we eliminate the symmetry requirement with a novel unsupervised algorithm that can learn a 3D reconstruction network from a multi-image dataset. Our algorithm is more general and covers the symmetry-required scenario as a special case. Besides, we employ a novel albedo loss that improves the reconstructed details and realisticity. Our method surpasses the previous work in both quality and robustness, as shown in experiments on datasets of various structures, including single-view, multi-view, image-collection, and video sets.