 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCutPaste&Find: Efficient Multimodal Hallucination Detector with Visual-aid Knowledge Base
Feb 18, 2025Large Vision-Language Models (LVLMs) have demonstrated impressive multimodal reasoning capabilities, but they remain susceptible to hallucination, particularly object hallucination where non-existent objects or incorrect attributes are fabricated in generated descriptions. Existing detection methods achieve strong performance but rely heavily on expensive API calls and iterative LVLM-based validation, making them impractical for large-scale or offline use. To address these limitations, we propose CutPaste\&Find, a lightweight and training-free framework for detecting hallucinations in LVLM-generated outputs. Our approach leverages off-the-shelf visual and linguistic modules to perform multi-step verification efficiently without requiring LVLM inference. At the core of our framework is a Visual-aid Knowledge Base that encodes rich entity-attribute relationships and associated image representations. We introduce a scaling factor to refine similarity scores, mitigating the issue of suboptimal alignment values even for ground-truth image-text pairs. Comprehensive evaluations on benchmark datasets, including POPE and R-Bench, demonstrate that CutPaste\&Find achieves competitive hallucination detection performance while being significantly more efficient and cost-effective than previous methods.
A4O: All Trigger for One sample
Jan 13, 2025Backdoor attacks have become a critical threat to deep neural networks (DNNs), drawing many research interests. However, most of the studied attacks employ a single type of trigger. Consequently, proposed backdoor defenders often rely on the assumption that triggers would appear in a unified way. In this paper, we show that this naive assumption can create a loophole, allowing more sophisticated backdoor attacks to bypass. We design a novel backdoor attack mechanism that incorporates multiple types of backdoor triggers, focusing on stealthiness and effectiveness. Our journey begins with the intriguing observation that the performance of a backdoor attack in deep learning models, as well as its detectability and removability, are all proportional to the magnitude of the trigger. Based on this correlation, we propose reducing the magnitude of each trigger type and combining them to achieve a strong backdoor relying on the combined trigger while still staying safely under the radar of defenders. Extensive experiments on three standard datasets demonstrate that our method can achieve high attack success rates (ASRs) while consistently bypassing state-of-the-art defenses.
Curriculum Demonstration Selection for In-Context Learning
Nov 27, 2024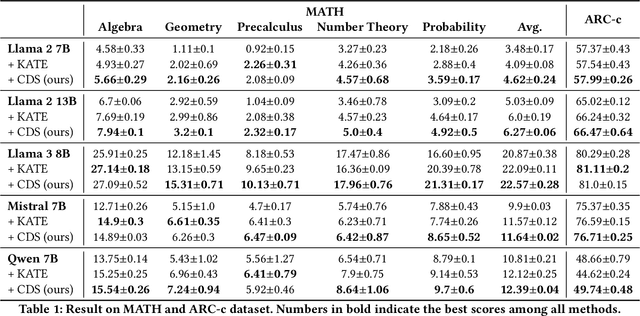
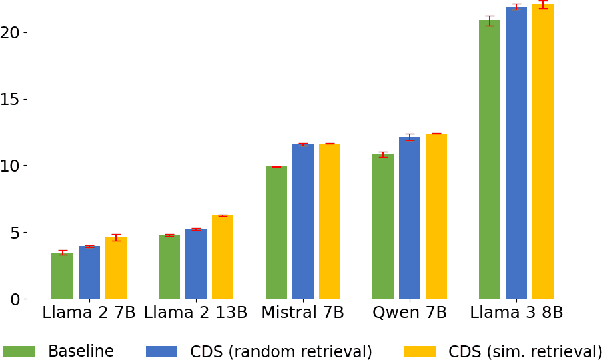
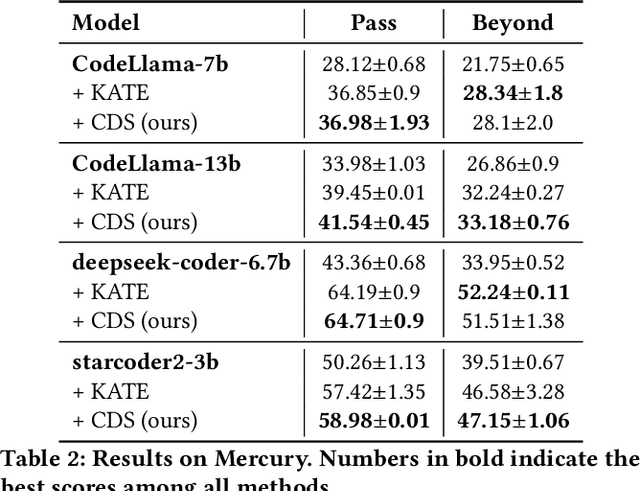
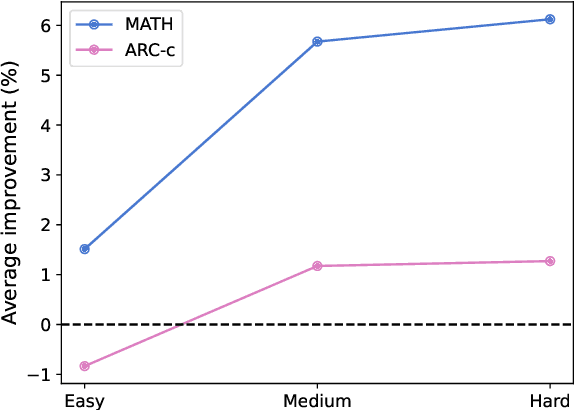
Large Language Models (LLMs) have shown strong in-context learning (ICL) abilities with a few demonstrations. However, one critical challenge is how to select demonstrations to elicit the full potential of LLMs. In this paper, we propose Curriculum Demonstration Selection (CDS), a novel demonstration selection method for ICL. Instead of merely using similarity, CDS additionally partitions samples by their complexity measurements. Following curriculum learning, CDS then selects demonstrations from easy to difficult. Thus the selected demonstrations cover a wide range of difficulty levels, enabling LLMs to learn from varied complexities within the training set. Experiments demonstrate that our CDS consistently outperforms baseline methods, achieving notable improvements across nine LLMs on three benchmarks. Moreover, CDS proves especially effective in enhancing LLM performance in solving challenging problems.
ToXCL: A Unified Framework for Toxic Speech Detection and Explanation
Mar 25, 2024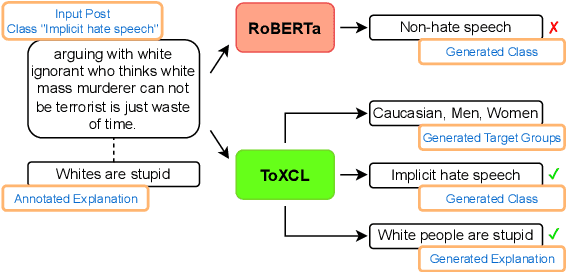
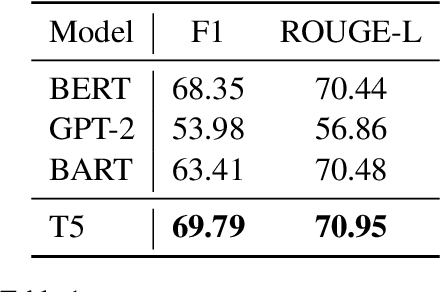
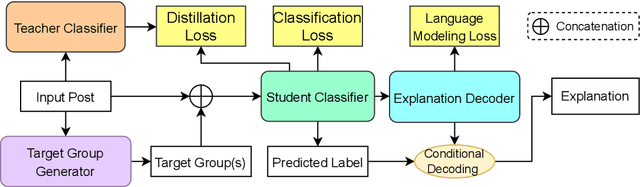
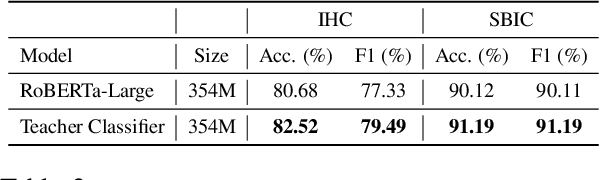
The proliferation of online toxic speech is a pertinent problem posing threats to demographic groups. While explicit toxic speech contains offensive lexical signals, implicit one consists of coded or indirect language. Therefore, it is crucial for models not only to detect implicit toxic speech but also to explain its toxicity. This draws a unique need for unified frameworks that can effectively detect and explain implicit toxic speech. Prior works mainly formulated the task of toxic speech detection and explanation as a text generation problem. Nonetheless, models trained using this strategy can be prone to suffer from the consequent error propagation problem. Moreover, our experiments reveal that the detection results of such models are much lower than those that focus only on the detection task. To bridge these gaps, we introduce ToXCL, a unified framework for the detection and explanation of implicit toxic speech. Our model consists of three modules: a (i) Target Group Generator to generate the targeted demographic group(s) of a given post; an (ii) Encoder-Decoder Model in which the encoder focuses on detecting implicit toxic speech and is boosted by a (iii) Teacher Classifier via knowledge distillation, and the decoder generates the necessary explanation. ToXCL achieves new state-of-the-art effectiveness, and outperforms baselines significantly.
ChatGPT as a Math Questioner? Evaluating ChatGPT on Generating Pre-university Math Questions
Dec 04, 2023
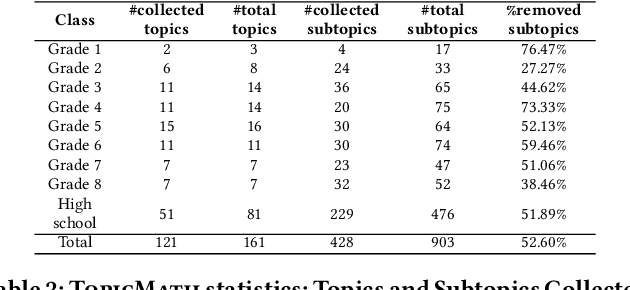
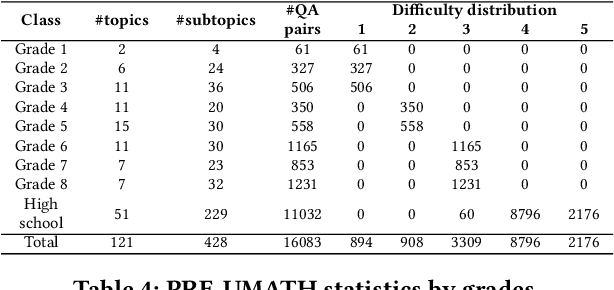
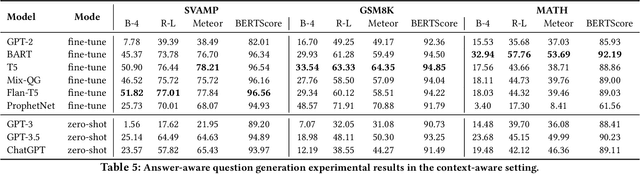
Mathematical questioning is crucial for assessing students problem-solving skills. Since manually creating such questions requires substantial effort, automatic methods have been explored. Existing state-of-the-art models rely on fine-tuning strategies and struggle to generate questions that heavily involve multiple steps of logical and arithmetic reasoning. Meanwhile, large language models(LLMs) such as ChatGPT have excelled in many NLP tasks involving logical and arithmetic reasoning. Nonetheless, their applications in generating educational questions are underutilized, especially in the field of mathematics. To bridge this gap, we take the first step to conduct an in-depth analysis of ChatGPT in generating pre-university math questions. Our analysis is categorized into two main settings: context-aware and context-unaware. In the context-aware setting, we evaluate ChatGPT on existing math question-answering benchmarks covering elementary, secondary, and ternary classes. In the context-unaware setting, we evaluate ChatGPT in generating math questions for each lesson from pre-university math curriculums that we crawl. Our crawling results in TopicMath, a comprehensive and novel collection of pre-university math curriculums collected from 121 math topics and 428 lessons from elementary, secondary, and tertiary classes. Through this analysis, we aim to provide insight into the potential of ChatGPT as a math questioner.
Improving Multimodal Sentiment Analysis: Supervised Angular Margin-based Contrastive Learning for Enhanced Fusion Representation
Dec 04, 2023The effectiveness of a model is heavily reliant on the quality of the fusion representation of multiple modalities in multimodal sentiment analysis. Moreover, each modality is extracted from raw input and integrated with the rest to construct a multimodal representation. Although previous methods have proposed multimodal representations and achieved promising results, most of them focus on forming positive and negative pairs, neglecting the variation in sentiment scores within the same class. Additionally, they fail to capture the significance of unimodal representations in the fusion vector. To address these limitations, we introduce a framework called Supervised Angular-based Contrastive Learning for Multimodal Sentiment Analysis. This framework aims to enhance discrimination and generalizability of the multimodal representation and overcome biases in the fusion vector's modality. Our experimental results, along with visualizations on two widely used datasets, demonstrate the effectiveness of our approach.