 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToXCL: A Unified Framework for Toxic Speech Detection and Explanation
Mar 25, 2024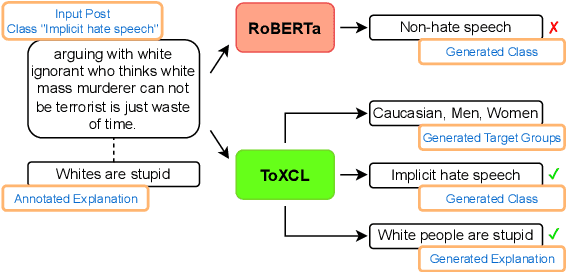
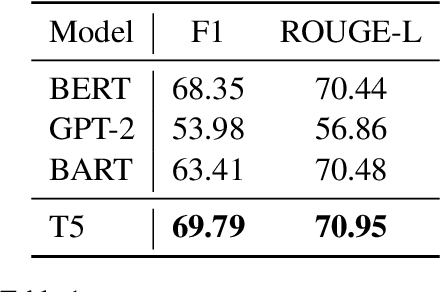
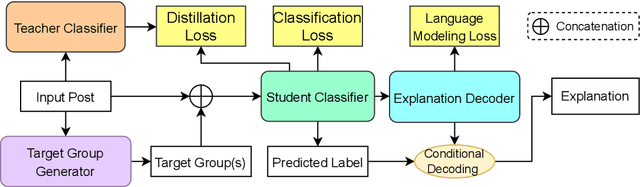
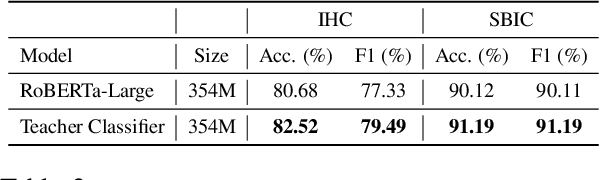
The proliferation of online toxic speech is a pertinent problem posing threats to demographic groups. While explicit toxic speech contains offensive lexical signals, implicit one consists of coded or indirect language. Therefore, it is crucial for models not only to detect implicit toxic speech but also to explain its toxicity. This draws a unique need for unified frameworks that can effectively detect and explain implicit toxic speech. Prior works mainly formulated the task of toxic speech detection and explanation as a text generation problem. Nonetheless, models trained using this strategy can be prone to suffer from the consequent error propagation problem. Moreover, our experiments reveal that the detection results of such models are much lower than those that focus only on the detection task. To bridge these gaps, we introduce ToXCL, a unified framework for the detection and explanation of implicit toxic speech. Our model consists of three modules: a (i) Target Group Generator to generate the targeted demographic group(s) of a given post; an (ii) Encoder-Decoder Model in which the encoder focuses on detecting implicit toxic speech and is boosted by a (iii) Teacher Classifier via knowledge distillation, and the decoder generates the necessary explanation. ToXCL achieves new state-of-the-art effectiveness, and outperforms baselines significantly.
Accelerating Greedy Coordinate Gradient via Probe Sampling
Mar 02, 2024



Safety of Large Language Models (LLMs) has become a central issue given their rapid progress and wide applications. Greedy Coordinate Gradient (GCG) is shown to be effective in constructing prompts containing adversarial suffixes to break the presumingly safe LLMs, but the optimization of GCG is time-consuming and limits its practicality. To reduce the time cost of GCG and enable more comprehensive studies of LLM safety, in this work, we study a new algorithm called $\texttt{Probe sampling}$ to accelerate the GCG algorithm. At the core of the algorithm is a mechanism that dynamically determines how similar a smaller draft model's predictions are to the target model's predictions for prompt candidates. When the target model is similar to the draft model, we rely heavily on the draft model to filter out a large number of potential prompt candidates to reduce the computation time. Probe sampling achieves up to $5.6$ times speedup using Llama2-7b and leads to equal or improved attack success rate (ASR) on the AdvBench.
Do LLMs Work on Charts? Designing Few-Shot Prompts for Chart Question Answering and Summarization
Dec 17, 2023A number of tasks have been proposed recently to facilitate easy access to charts such as chart QA and summarization. The dominant paradigm to solve these tasks has been to fine-tune a pretrained model on the task data. However, this approach is not only expensive but also not generalizable to unseen tasks. On the other hand, large language models (LLMs) have shown impressive generalization capabilities to unseen tasks with zero- or few-shot prompting. However, their application to chart-related tasks is not trivial as these tasks typically involve considering not only the underlying data but also the visual features in the chart image. We propose PromptChart, a multimodal few-shot prompting framework with LLMs for chart-related applications. By analyzing the tasks carefully, we have come up with a set of prompting guidelines for each task to elicit the best few-shot performance from LLMs. We further propose a strategy to inject visual information into the prompts. Our experiments on three different chart-related information consumption tasks show that with properly designed prompts LLMs can excel on the benchmarks, achieving state-of-the-art.
Prompt Optimization via Adversarial In-Context Learning
Dec 05, 2023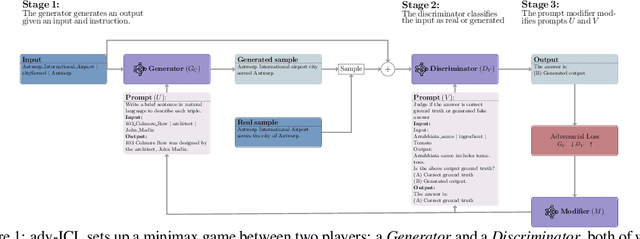
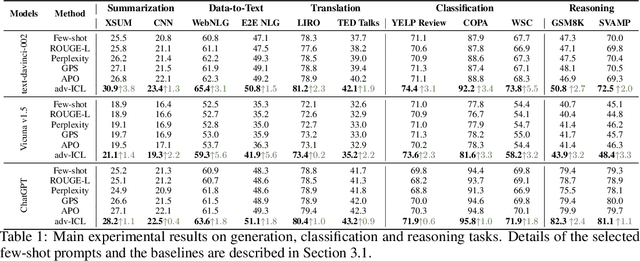

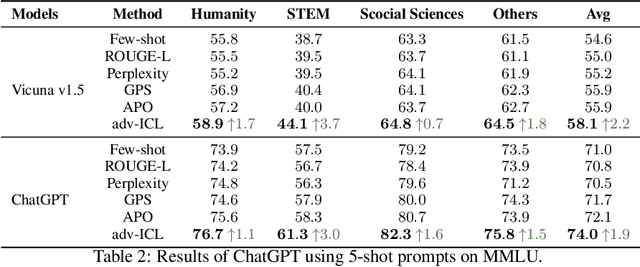
We propose a new method, Adversarial In-Context Learning (adv-ICL), to optimize prompt for in-context learning (ICL) by employing one LLM as a generator, another as a discriminator, and a third as a prompt modifier. As in traditional adversarial learning, adv-ICL is implemented as a two-player game between the generator and discriminator, where the generator tries to generate realistic enough output to fool the discriminator. In each round, given an input prefixed by task instructions and several exemplars, the generator produces an output. The discriminator is then tasked with classifying the generator input-output pair as model-generated or real data. Based on the discriminator loss, the prompt modifier proposes possible edits to the generator and discriminator prompts, and the edits that most improve the adversarial loss are selected. We show that adv-ICL results in significant improvements over state-of-the-art prompt optimization techniques for both open and closed-source models on 11 generation and classification tasks including summarization, arithmetic reasoning, machine translation, data-to-text generation, and the MMLU and big-bench hard benchmarks. In addition, because our method uses pre-trained models and updates only prompts rather than model parameters, it is computationally efficient, easy to extend to any LLM and task, and effective in low-resource settings.
ChatGPT as a Math Questioner? Evaluating ChatGPT on Generating Pre-university Math Questions
Dec 04, 2023
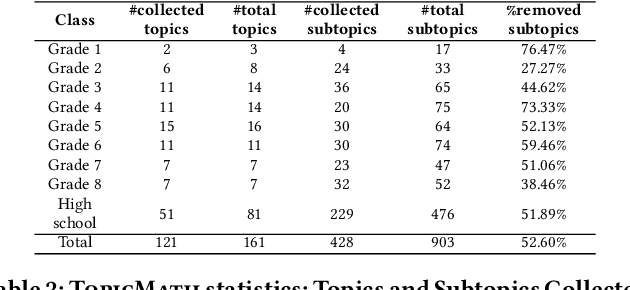
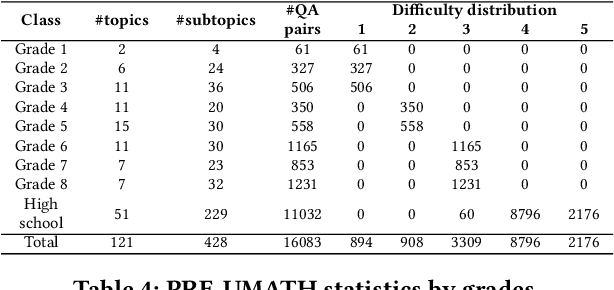
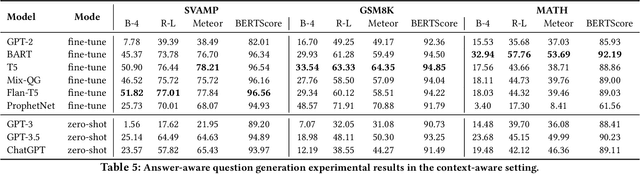
Mathematical questioning is crucial for assessing students problem-solving skills. Since manually creating such questions requires substantial effort, automatic methods have been explored. Existing state-of-the-art models rely on fine-tuning strategies and struggle to generate questions that heavily involve multiple steps of logical and arithmetic reasoning. Meanwhile, large language models(LLMs) such as ChatGPT have excelled in many NLP tasks involving logical and arithmetic reasoning. Nonetheless, their applications in generating educational questions are underutilized, especially in the field of mathematics. To bridge this gap, we take the first step to conduct an in-depth analysis of ChatGPT in generating pre-university math questions. Our analysis is categorized into two main settings: context-aware and context-unaware. In the context-aware setting, we evaluate ChatGPT on existing math question-answering benchmarks covering elementary, secondary, and ternary classes. In the context-unaware setting, we evaluate ChatGPT in generating math questions for each lesson from pre-university math curriculums that we crawl. Our crawling results in TopicMath, a comprehensive and novel collection of pre-university math curriculums collected from 121 math topics and 428 lessons from elementary, secondary, and tertiary classes. Through this analysis, we aim to provide insight into the potential of ChatGPT as a math questioner.
ChOiRe: Characterizing and Predicting Human Opinions with Chain of Opinion Reasoning
Nov 15, 2023



Aligning language models (LMs) with human opinion is challenging yet vital to enhance their grasp of human values, preferences, and beliefs. We present ChOiRe, a four-step solution framework to predict human opinion that differentiates between the user explicit personae (i.e. demographic or ideological attributes) that are manually declared and implicit personae inferred from user historical opinions. Specifically, it consists of (i) an LM analyzing the user explicit personae to filter out irrelevant attributes; (ii) the LM ranking the implicit persona opinions into a preferential list; (iii) Chain-of-Opinion (CoO) reasoning, where the LM sequentially analyzes the explicit personae and the most relevant implicit personae to perform opinion prediction; (iv) and where ChOiRe executes Step (iii) CoO multiple times with increasingly larger lists of implicit personae to overcome insufficient personae information to infer a final result. ChOiRe achieves new state-of-the-art effectiveness with limited inference calls, improving previous LLM-based techniques significantly by 3.22%.
UniChart: A Universal Vision-language Pretrained Model for Chart Comprehension and Reasoning
May 24, 2023
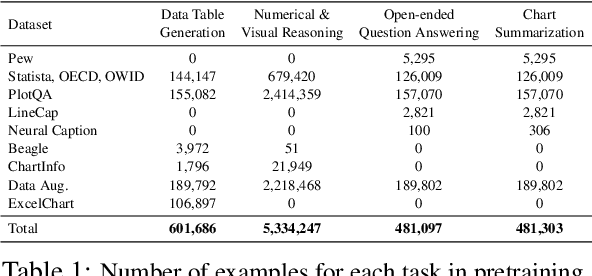


Charts are very popular for analyzing data, visualizing key insights and answering complex reasoning questions about data. To facilitate chart-based data analysis using natural language, several downstream tasks have been introduced recently such as chart question answering and chart summarization. However, most of the methods that solve these tasks use pretraining on language or vision-language tasks that do not attempt to explicitly model the structure of the charts (e.g., how data is visually encoded and how chart elements are related to each other). To address this, we first build a large corpus of charts covering a wide variety of topics and visual styles. We then present UniChart, a pretrained model for chart comprehension and reasoning. UniChart encodes the relevant text, data, and visual elements of charts and then uses a chart-grounded text decoder to generate the expected output in natural language. We propose several chart-specific pretraining tasks that include: (i) low-level tasks to extract the visual elements (e.g., bars, lines) and data from charts, and (ii) high-level tasks to acquire chart understanding and reasoning skills. We find that pretraining the model on a large corpus with chart-specific low- and high-level tasks followed by finetuning on three down-streaming tasks results in state-of-the-art performance on three downstream tasks.
Modeling What-to-ask and How-to-ask for Answer-unaware Conversational Question Generation
May 04, 2023Conversational Question Generation (CQG) is a critical task for machines to assist humans in fulfilling their information needs through conversations. The task is generally cast into two different settings: answer-aware and answer-unaware. While the former facilitates the models by exposing the expected answer, the latter is more realistic and receiving growing attentions recently. What-to-ask and how-to-ask are the two main challenges in the answer-unaware setting. To address the first challenge, existing methods mainly select sequential sentences in context as the rationales. We argue that the conversation generated using such naive heuristics may not be natural enough as in reality, the interlocutors often talk about the relevant contents that are not necessarily sequential in context. Additionally, previous methods decide the type of question to be generated (boolean/span-based) implicitly. Modeling the question type explicitly is crucial as the answer, which hints the models to generate a boolean or span-based question, is unavailable. To this end, we present SG-CQG, a two-stage CQG framework. For the what-to-ask stage, a sentence is selected as the rationale from a semantic graph that we construct, and extract the answer span from it. For the how-to-ask stage, a classifier determines the target answer type of the question via two explicit control signals before generating and filtering. In addition, we propose Conv-Distinct, a novel evaluation metric for CQG, to evaluate the diversity of the generated conversation from a context. Compared with the existing answer-unaware CQG models, the proposed SG-CQG achieves state-of-the-art performance.
Retrieving Multimodal Information for Augmented Generation: A Survey
Mar 20, 2023

In this survey, we review methods that retrieve multimodal knowledge to assist and augment generative models. This group of works focuses on retrieving grounding contexts from external sources, including images, codes, tables, graphs, and audio. As multimodal learning and generative AI have become more and more impactful, such retrieval augmentation offers a promising solution to important concerns such as factuality, reasoning, interpretability, and robustness. We provide an in-depth review of retrieval-augmented generation in different modalities and discuss potential future directions. As this is an emerging field, we continue to add new papers and methods.
xCodeEval: A Large Scale Multilingual Multitask Benchmark for Code Understanding, Generation, Translation and Retrieval
Mar 06, 2023



The ability to solve problems is a hallmark of intelligence and has been an enduring goal in AI. AI systems that can create programs as solutions to problems or assist developers in writing programs can increase productivity and make programming more accessible. Recently, pre-trained large language models have shown impressive abilities in generating new codes from natural language descriptions, repairing buggy codes, translating codes between languages, and retrieving relevant code segments. However, the evaluation of these models has often been performed in a scattered way on only one or two specific tasks, in a few languages, at a partial granularity (e.g., function) level and in many cases without proper training data. Even more concerning is that in most cases the evaluation of generated codes has been done in terms of mere lexical overlap rather than actual execution whereas semantic similarity (or equivalence) of two code segments depends only on their ``execution similarity'', i.e., being able to get the same output for a given input.