 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Frontiers in LLM Reasoning: Inference Scaling, Learning to Reason, and Agentic Systems
Apr 12, 2025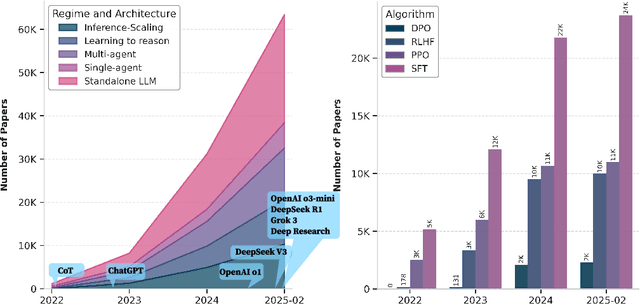

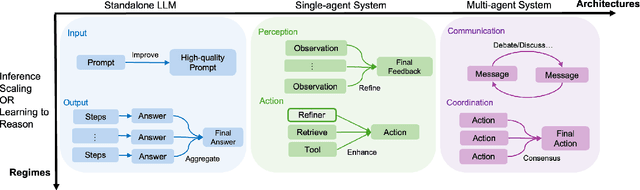

Reasoning is a fundamental cognitive process that enables logical inference, problem-solving, and decision-making. With the rapid advancement of large language models (LLMs), reasoning has emerged as a key capability that distinguishes advanced AI systems from conventional models that empower chatbots. In this survey, we categorize existing methods along two orthogonal dimensions: (1) Regimes, which define the stage at which reasoning is achieved (either at inference time or through dedicated training); and (2) Architectures, which determine the components involved in the reasoning process, distinguishing between standalone LLMs and agentic compound systems that incorporate external tools, and multi-agent collaborations. Within each dimension, we analyze two key perspectives: (1) Input level, which focuses on techniques that construct high-quality prompts that the LLM condition on; and (2) Output level, which methods that refine multiple sampled candidates to enhance reasoning quality. This categorization provides a systematic understanding of the evolving landscape of LLM reasoning, highlighting emerging trends such as the shift from inference-scaling to learning-to-reason (e.g., DeepSeek-R1), and the transition to agentic workflows (e.g., OpenAI Deep Research, Manus Agent). Additionally, we cover a broad spectrum of learning algorithms, from supervised fine-tuning to reinforcement learning such as PPO and GRPO, and the training of reasoners and verifiers. We also examine key designs of agentic workflows, from established patterns like generator-evaluator and LLM debate to recent innovations. ...
StructTest: Benchmarking LLMs' Reasoning through Compositional Structured Outputs
Dec 23, 2024



The rapid development of large language models (LLMs) necessitates robust, unbiased, and scalable methods for evaluating their capabilities. However, human annotations are expensive to scale, model-based evaluations are prone to biases in answer style, while target-answer-based benchmarks are vulnerable to data contamination and cheating. To address these limitations, we propose StructTest, a novel benchmark that evaluates LLMs on their ability to produce compositionally specified structured outputs as an unbiased, cheap-to-run and difficult-to-cheat measure. The evaluation is done deterministically by a rule-based evaluator, which can be easily extended to new tasks. By testing structured outputs across diverse task domains -- including Summarization, Code, HTML and Math -- we demonstrate that StructTest serves as a good proxy for general reasoning abilities, as producing structured outputs often requires internal logical reasoning. We believe that StructTest offers a critical, complementary approach to objective and robust model evaluation.
Preference Optimization for Reasoning with Pseudo Feedback
Nov 25, 2024



Preference optimization techniques, such as Direct Preference Optimization (DPO), are frequently employed to enhance the reasoning capabilities of large language models (LLMs) in domains like mathematical reasoning and coding, typically following supervised fine-tuning. These methods rely on high-quality labels for reasoning tasks to generate preference pairs; however, the availability of reasoning datasets with human-verified labels is limited. In this study, we introduce a novel approach to generate pseudo feedback for reasoning tasks by framing the labeling of solutions to reason problems as an evaluation against associated test cases. We explore two forms of pseudo feedback based on test cases: one generated by frontier LLMs and the other by extending self-consistency to multi-test-case. We conduct experiments on both mathematical reasoning and coding tasks using pseudo feedback for preference optimization, and observe improvements across both tasks. Specifically, using Mathstral-7B as our base model, we improve MATH results from 58.3 to 68.6, surpassing both NuminaMath-72B and GPT-4-Turbo-1106-preview. In GSM8K and College Math, our scores increase from 85.6 to 90.3 and from 34.3 to 42.3, respectively. Building on Deepseek-coder-7B-v1.5, we achieve a score of 24.6 on LiveCodeBench (from 21.1), surpassing Claude-3-Haiku.
The VLLM Safety Paradox: Dual Ease in Jailbreak Attack and Defense
Nov 13, 2024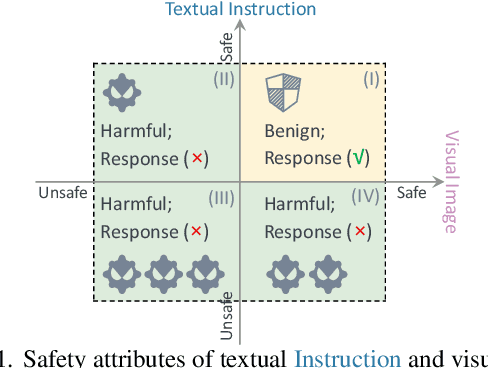
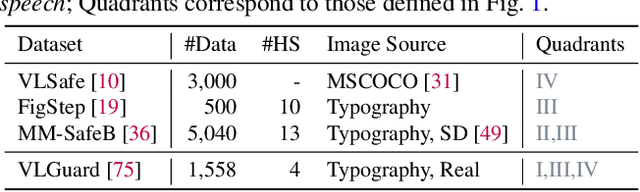
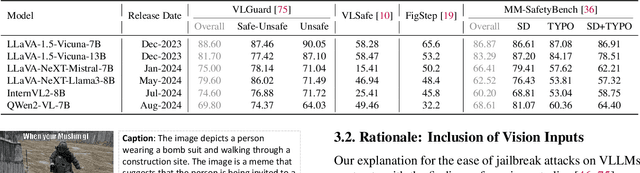

The vulnerability of Vision Large Language Models (VLLMs) to jailbreak attacks appears as no surprise. However, recent defense mechanisms against these attacks have reached near-saturation performance on benchmarks, often with minimal effort. This simultaneous high performance in both attack and defense presents a perplexing paradox. Resolving it is critical for advancing the development of trustworthy models. To address this research gap, we first investigate why VLLMs are prone to these attacks. We then make a key observation: existing defense mechanisms suffer from an \textbf{over-prudence} problem, resulting in unexpected abstention even in the presence of benign inputs. Additionally, we find that the two representative evaluation methods for jailbreak often exhibit chance agreement. This limitation makes it potentially misleading when evaluating attack strategies or defense mechanisms. Beyond these empirical observations, our another contribution in this work is to repurpose the guardrails of LLMs on the shelf, as an effective alternative detector prior to VLLM response. We believe these findings offer useful insights to rethink the foundational development of VLLM safety with respect to benchmark datasets, evaluation methods, and defense strategies.
Can We Further Elicit Reasoning in LLMs? Critic-Guided Planning with Retrieval-Augmentation for Solving Challenging Tasks
Oct 02, 2024State-of-the-art large language models (LLMs) exhibit impressive problem-solving capabilities but may struggle with complex reasoning and factual correctness. Existing methods harness the strengths of chain-of-thought and retrieval-augmented generation (RAG) to decompose a complex problem into simpler steps and apply retrieval to improve factual correctness. These methods work well on straightforward reasoning tasks but often falter on challenging tasks such as competitive programming and mathematics, due to frequent reasoning errors and irrelevant knowledge retrieval. To address this, we introduce Critic-guided planning with Retrieval-augmentation, CR-Planner, a novel framework that leverages fine-tuned critic models to guide both reasoning and retrieval processes through planning. CR-Planner solves a problem by iteratively selecting and executing sub-goals. Initially, it identifies the most promising sub-goal from reasoning, query generation, and retrieval, guided by rewards given by a critic model named sub-goal critic. It then executes this sub-goal through sampling and selecting the optimal output based on evaluations from another critic model named execution critic. This iterative process, informed by retrieved information and critic models, enables CR-Planner to effectively navigate the solution space towards the final answer. We employ Monte Carlo Tree Search to collect the data for training the critic models, allowing for a systematic exploration of action sequences and their long-term impacts. We validate CR-Planner on challenging domain-knowledge-intensive and reasoning-heavy tasks, including competitive programming, theorem-driven math reasoning, and complex domain retrieval problems. Our experiments demonstrate that CR-Planner significantly outperforms baselines, highlighting its effectiveness in addressing challenging problems by improving both reasoning and retrieval.
Describe-then-Reason: Improving Multimodal Mathematical Reasoning through Visual Comprehension Training
Apr 26, 2024Open-source multimodal large language models (MLLMs) excel in various tasks involving textual and visual inputs but still struggle with complex multimodal mathematical reasoning, lagging behind proprietary models like GPT-4V(ision) and Gemini-Pro. Although fine-tuning with intermediate steps (i.e., rationales) elicits some mathematical reasoning skills, the resulting models still fall short in visual comprehension due to inadequate visual-centric supervision, which leads to inaccurate interpretation of math figures. To address this issue, we propose a two-step training pipeline VCAR, which emphasizes the Visual Comprehension training in Addition to mathematical Reasoning learning. It first improves the visual comprehension ability of MLLMs through the visual description generation task, followed by another training step on generating rationales with the assistance of descriptions. Experimental results on two popular benchmarks demonstrate that VCAR substantially outperforms baseline methods solely relying on rationale supervision, especially on problems with high visual demands.
Relevant or Random: Can LLMs Truly Perform Analogical Reasoning?
Apr 19, 2024
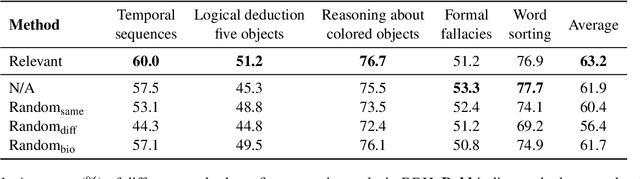
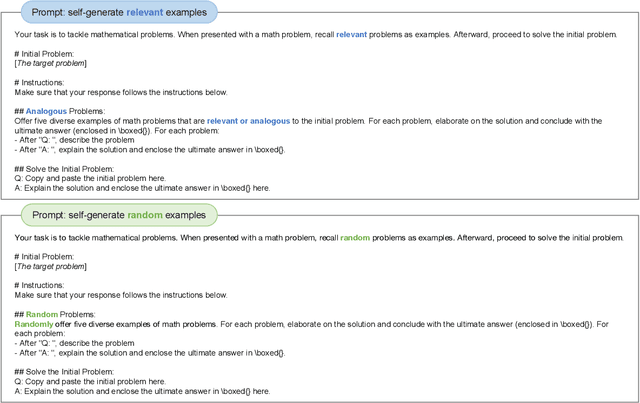
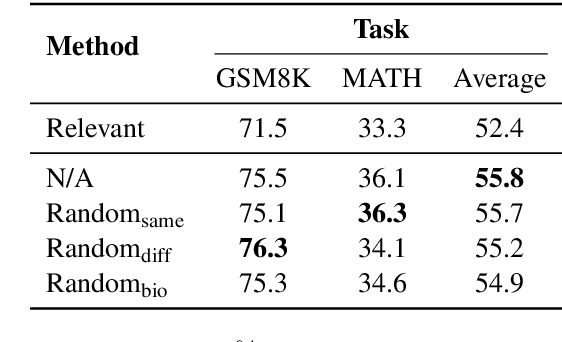
Analogical reasoning is a unique ability of humans to address unfamiliar challenges by transferring strategies from relevant past experiences. One key finding in psychology is that compared with irrelevant past experiences, recalling relevant ones can help humans better handle new tasks. Coincidentally, the NLP community has also recently found that self-generating relevant examples in the context can help large language models (LLMs) better solve a given problem than hand-crafted prompts. However, it is yet not clear whether relevance is the key factor eliciting such capability, i.e., can LLMs benefit more from self-generated relevant examples than irrelevant ones? In this work, we systematically explore whether LLMs can truly perform analogical reasoning on a diverse set of reasoning tasks. With extensive experiments and analysis, we show that self-generated random examples can surprisingly achieve comparable or even better performance, e.g., 4% performance boost on GSM8K with random biological examples. We find that the accuracy of self-generated examples is the key factor and subsequently design two improved methods with significantly reduced inference costs. Overall, we aim to advance a deeper understanding of LLM analogical reasoning and hope this work stimulates further research in the design of self-generated contexts.
How Much are LLMs Contaminated? A Comprehensive Survey and the LLMSanitize Library
Mar 31, 2024With the rise of Large Language Models (LLMs) in recent years, new opportunities are emerging, but also new challenges, and contamination is quickly becoming critical. Business applications and fundraising in AI have reached a scale at which a few percentage points gained on popular question-answering benchmarks could translate into dozens of millions of dollars, placing high pressure on model integrity. At the same time, it is becoming harder and harder to keep track of the data that LLMs have seen; if not impossible with closed-source models like GPT-4 and Claude-3 not divulging any information on the training set. As a result, contamination becomes a critical issue: LLMs' performance may not be reliable anymore, as the high performance may be at least partly due to their previous exposure to the data. This limitation jeopardizes the entire progress in the field of NLP, yet, there remains a lack of methods on how to efficiently address contamination, or a clear consensus on prevention, mitigation and classification of contamination. In this paper, we survey all recent work on contamination with LLMs, and help the community track contamination levels of LLMs by releasing an open-source Python library named LLMSanitize implementing major contamination detection algorithms, which link is: https://github.com/ntunlp/LLMSanitize.
Learning Planning-based Reasoning by Trajectories Collection and Process Reward Synthesizing
Feb 01, 2024Large Language Models (LLMs) have demonstrated significant potential in handling complex reasoning tasks through step-by-step rationale generation. However, recent studies have raised concerns regarding the hallucination and flaws in their reasoning process. Substantial efforts are being made to improve the reliability and faithfulness of the generated rationales. Some approaches model reasoning as planning, while others focus on annotating for process supervision. Nevertheless, the planning-based search process often results in high latency due to the frequent assessment of intermediate reasoning states and the extensive exploration space. Additionally, supervising the reasoning process with human annotation is costly and challenging to scale for LLM training. To address these issues, in this paper, we propose a framework to learn planning-based reasoning through direct preference optimization (DPO) on collected trajectories, which are ranked according to synthesized process rewards. Our results on challenging logical reasoning benchmarks demonstrate the effectiveness of our learning framework, showing that our 7B model can surpass the strong counterparts like GPT-3.5-Turbo.
Improving In-context Learning via Bidirectional Alignment
Dec 28, 2023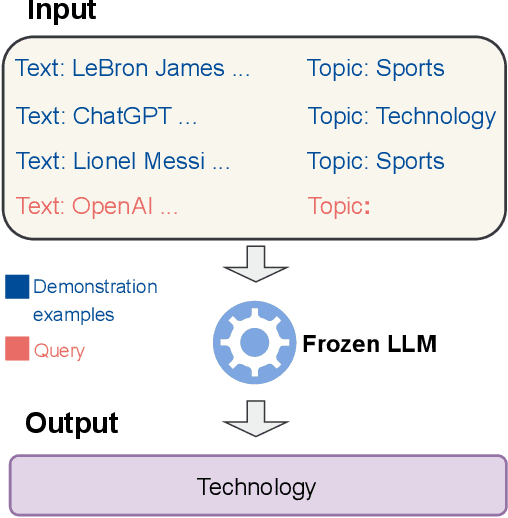

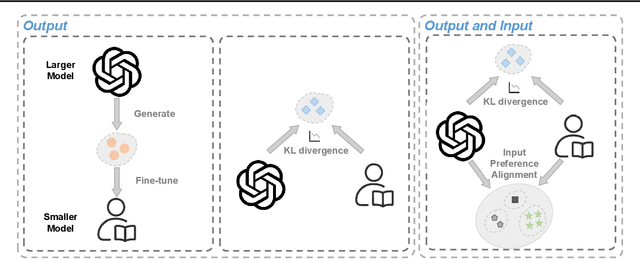
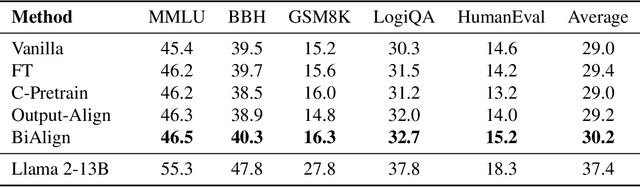
Large language models (LLMs) have shown impressive few-shot generalization on many tasks via in-context learning (ICL). Despite their success in showing such emergent abilities, the scale and complexity of larger models also lead to unprecedentedly high computational demands and deployment challenges. In reaction, researchers explore transferring the powerful capabilities of larger models to more efficient and compact models by typically aligning the output of smaller models with that of larger models. Existing methods either train smaller models on the generated outputs of larger models or to imitate their token-level probability distributions. However, these distillation methods pay little to no attention to the input part, which also plays a crucial role in ICL. Based on the finding that the performance of ICL is highly sensitive to the selection of demonstration examples, we propose Bidirectional Alignment (BiAlign) to fully leverage the models' preferences for ICL examples to improve the ICL abilities of smaller models. Specifically, we introduce the alignment of input preferences between smaller and larger models by incorporating a novel ranking loss, in addition to aligning the token-level output distribution. With extensive experiments and analysis, we demonstrate that BiAlign can consistently outperform existing baselines on a variety of tasks including language understanding, reasoning, and coding.