 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHTMformer: Hybrid Time and Multivariate Transformer for Time Series Forecasting
Oct 08, 2025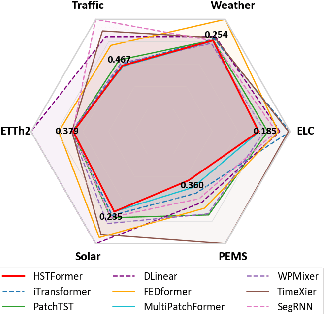



Transformer-based methods have achieved impressive results in time series forecasting. However, existing Transformers still exhibit limitations in sequence modeling as they tend to overemphasize temporal dependencies. This incurs additional computational overhead without yielding corresponding performance gains. We find that the performance of Transformers is highly dependent on the embedding method used to learn effective representations. To address this issue, we extract multivariate features to augment the effective information captured in the embedding layer, yielding multidimensional embeddings that convey richer and more meaningful sequence representations. These representations enable Transformer-based forecasters to better understand the series. Specifically, we introduce Hybrid Temporal and Multivariate Embeddings (HTME). The HTME extractor integrates a lightweight temporal feature extraction module with a carefully designed multivariate feature extraction module to provide complementary features, thereby achieving a balance between model complexity and performance. By combining HTME with the Transformer architecture, we present HTMformer, leveraging the enhanced feature extraction capability of the HTME extractor to build a lightweight forecaster. Experiments conducted on eight real-world datasets demonstrate that our approach outperforms existing baselines in both accuracy and efficiency.
Unified Text-to-Image Generation and Retrieval
Jun 09, 2024



How humans can efficiently and effectively acquire images has always been a perennial question. A typical solution is text-to-image retrieval from an existing database given the text query; however, the limited database typically lacks creativity. By contrast, recent breakthroughs in text-to-image generation have made it possible to produce fancy and diverse visual content, but it faces challenges in synthesizing knowledge-intensive images. In this work, we rethink the relationship between text-to-image generation and retrieval and propose a unified framework in the context of Multimodal Large Language Models (MLLMs). Specifically, we first explore the intrinsic discriminative abilities of MLLMs and introduce a generative retrieval method to perform retrieval in a training-free manner. Subsequently, we unify generation and retrieval in an autoregressive generation way and propose an autonomous decision module to choose the best-matched one between generated and retrieved images as the response to the text query. Additionally, we construct a benchmark called TIGeR-Bench, including creative and knowledge-intensive domains, to standardize the evaluation of unified text-to-image generation and retrieval. Extensive experimental results on TIGeR-Bench and two retrieval benchmarks, i.e., Flickr30K and MS-COCO, demonstrate the superiority and effectiveness of our proposed method.
Relevant or Random: Can LLMs Truly Perform Analogical Reasoning?
Apr 19, 2024
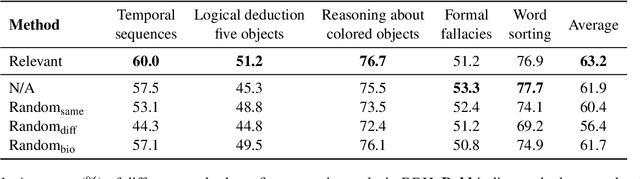
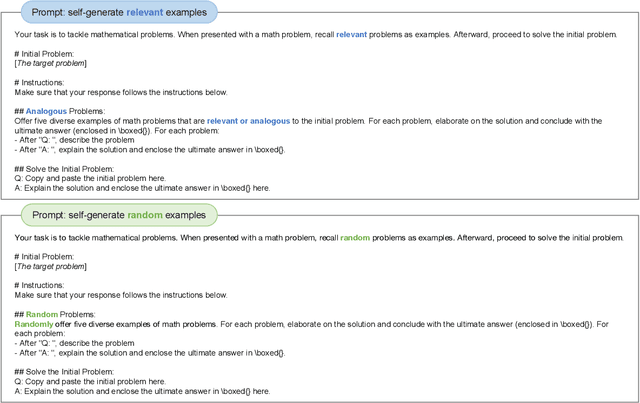
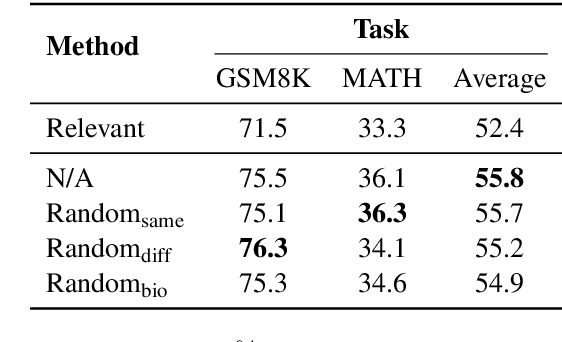
Analogical reasoning is a unique ability of humans to address unfamiliar challenges by transferring strategies from relevant past experiences. One key finding in psychology is that compared with irrelevant past experiences, recalling relevant ones can help humans better handle new tasks. Coincidentally, the NLP community has also recently found that self-generating relevant examples in the context can help large language models (LLMs) better solve a given problem than hand-crafted prompts. However, it is yet not clear whether relevance is the key factor eliciting such capability, i.e., can LLMs benefit more from self-generated relevant examples than irrelevant ones? In this work, we systematically explore whether LLMs can truly perform analogical reasoning on a diverse set of reasoning tasks. With extensive experiments and analysis, we show that self-generated random examples can surprisingly achieve comparable or even better performance, e.g., 4% performance boost on GSM8K with random biological examples. We find that the accuracy of self-generated examples is the key factor and subsequently design two improved methods with significantly reduced inference costs. Overall, we aim to advance a deeper understanding of LLM analogical reasoning and hope this work stimulates further research in the design of self-generated contexts.
Enhance Image Classification via Inter-Class Image Mixup with Diffusion Model
Mar 28, 2024



Text-to-image (T2I) generative models have recently emerged as a powerful tool, enabling the creation of photo-realistic images and giving rise to a multitude of applications. However, the effective integration of T2I models into fundamental image classification tasks remains an open question. A prevalent strategy to bolster image classification performance is through augmenting the training set with synthetic images generated by T2I models. In this study, we scrutinize the shortcomings of both current generative and conventional data augmentation techniques. Our analysis reveals that these methods struggle to produce images that are both faithful (in terms of foreground objects) and diverse (in terms of background contexts) for domain-specific concepts. To tackle this challenge, we introduce an innovative inter-class data augmentation method known as Diff-Mix (https://github.com/Zhicaiwww/Diff-Mix), which enriches the dataset by performing image translations between classes. Our empirical results demonstrate that Diff-Mix achieves a better balance between faithfulness and diversity, leading to a marked improvement in performance across diverse image classification scenarios, including few-shot, conventional, and long-tail classifications for domain-specific datasets.
DisCo: Disentangled Control for Referring Human Dance Generation in Real World
Jun 30, 2023Generative AI has made significant strides in computer vision, particularly in image/video synthesis conditioned on text descriptions. Despite the advancements, it remains challenging especially in the generation of human-centric content such as dance synthesis. Existing dance synthesis methods struggle with the gap between synthesized content and real-world dance scenarios. In this paper, we define a new problem setting: Referring Human Dance Generation, which focuses on real-world dance scenarios with three important properties: (i) Faithfulness: the synthesis should retain the appearance of both human subject foreground and background from the reference image, and precisely follow the target pose; (ii) Generalizability: the model should generalize to unseen human subjects, backgrounds, and poses; (iii) Compositionality: it should allow for composition of seen/unseen subjects, backgrounds, and poses from different sources. To address these challenges, we introduce a novel approach, DISCO, which includes a novel model architecture with disentangled control to improve the faithfulness and compositionality of dance synthesis, and an effective human attribute pre-training for better generalizability to unseen humans. Extensive qualitative and quantitative results demonstrate that DISCO can generate high-quality human dance images and videos with diverse appearances and flexible motions. Code, demo, video and visualization are available at: https://disco-dance.github.io/.
Explaining Language Models' Predictions with High-Impact Concepts
May 03, 2023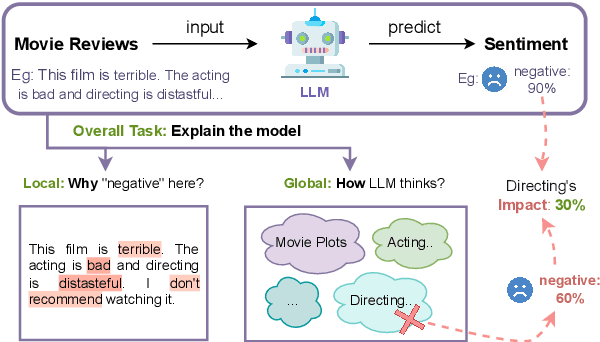
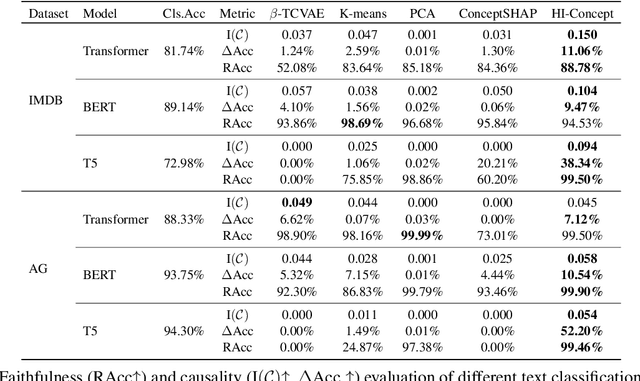
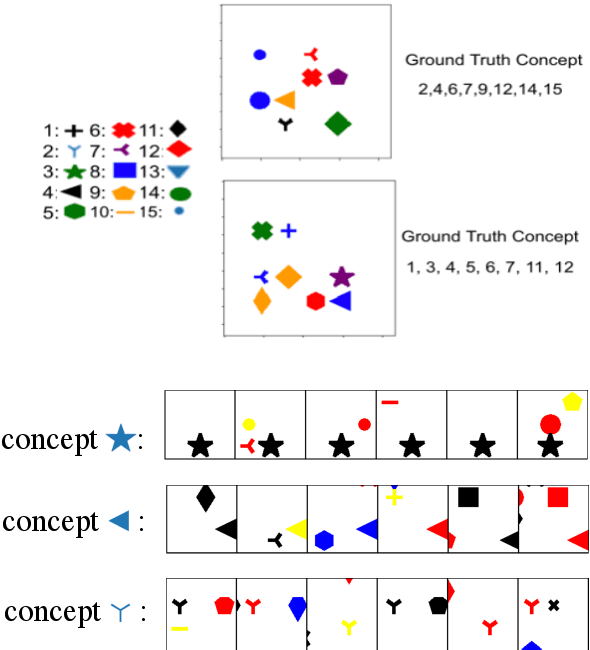
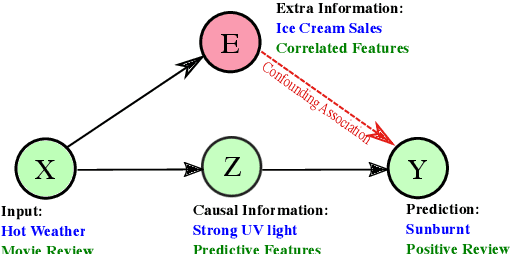
The emergence of large-scale pretrained language models has posed unprecedented challenges in deriving explanations of why the model has made some predictions. Stemmed from the compositional nature of languages, spurious correlations have further undermined the trustworthiness of NLP systems, leading to unreliable model explanations that are merely correlated with the output predictions. To encourage fairness and transparency, there exists an urgent demand for reliable explanations that allow users to consistently understand the model's behavior. In this work, we propose a complete framework for extending concept-based interpretability methods to NLP. Specifically, we propose a post-hoc interpretability method for extracting predictive high-level features (concepts) from the pretrained model's hidden layer activations. We optimize for features whose existence causes the output predictions to change substantially, \ie generates a high impact. Moreover, we devise several evaluation metrics that can be universally applied. Extensive experiments on real and synthetic tasks demonstrate that our method achieves superior results on {predictive impact}, usability, and faithfulness compared to the baselines.
Equivariant Similarity for Vision-Language Foundation Models
Mar 25, 2023This study explores the concept of equivariance in vision-language foundation models (VLMs), focusing specifically on the multimodal similarity function that is not only the major training objective but also the core delivery to support downstream tasks. Unlike the existing image-text similarity objective which only categorizes matched pairs as similar and unmatched pairs as dissimilar, equivariance also requires similarity to vary faithfully according to the semantic changes. This allows VLMs to generalize better to nuanced and unseen multimodal compositions. However, modeling equivariance is challenging as the ground truth of semantic change is difficult to collect. For example, given an image-text pair about a dog, it is unclear to what extent the similarity changes when the pixel is changed from dog to cat? To this end, we propose EqSim, a regularization loss that can be efficiently calculated from any two matched training pairs and easily pluggable into existing image-text retrieval fine-tuning. Meanwhile, to further diagnose the equivariance of VLMs, we present a new challenging benchmark EqBen. Compared to the existing evaluation sets, EqBen is the first to focus on "visual-minimal change". Extensive experiments show the lack of equivariance in current VLMs and validate the effectiveness of EqSim. Code is available at \url{https://github.com/Wangt-CN/EqBen}.
Equivariance and Invariance Inductive Bias for Learning from Insufficient Data
Jul 25, 2022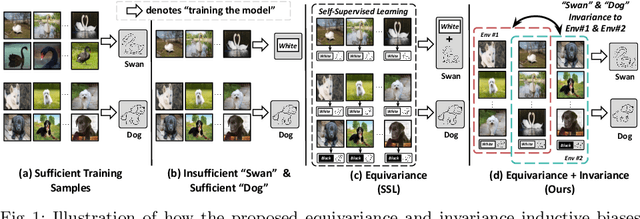
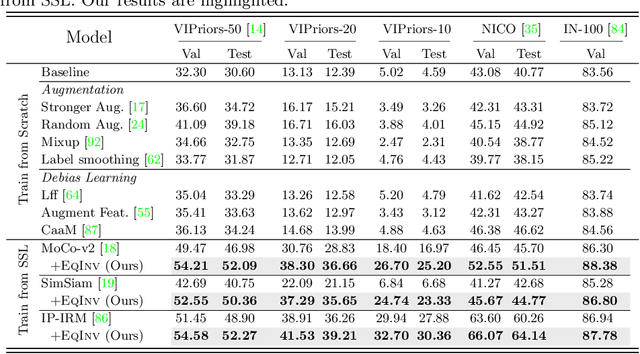


We are interested in learning robust models from insufficient data, without the need for any externally pre-trained checkpoints. First, compared to sufficient data, we show why insufficient data renders the model more easily biased to the limited training environments that are usually different from testing. For example, if all the training swan samples are "white", the model may wrongly use the "white" environment to represent the intrinsic class swan. Then, we justify that equivariance inductive bias can retain the class feature while invariance inductive bias can remove the environmental feature, leaving the class feature that generalizes to any environmental changes in testing. To impose them on learning, for equivariance, we demonstrate that any off-the-shelf contrastive-based self-supervised feature learning method can be deployed; for invariance, we propose a class-wise invariant risk minimization (IRM) that efficiently tackles the challenge of missing environmental annotation in conventional IRM. State-of-the-art experimental results on real-world benchmarks (VIPriors, ImageNet100 and NICO) validate the great potential of equivariance and invariance in data-efficient learning. The code is available at https://github.com/Wangt-CN/EqInv
ClothFormer:Taming Video Virtual Try-on in All Module
Apr 26, 2022
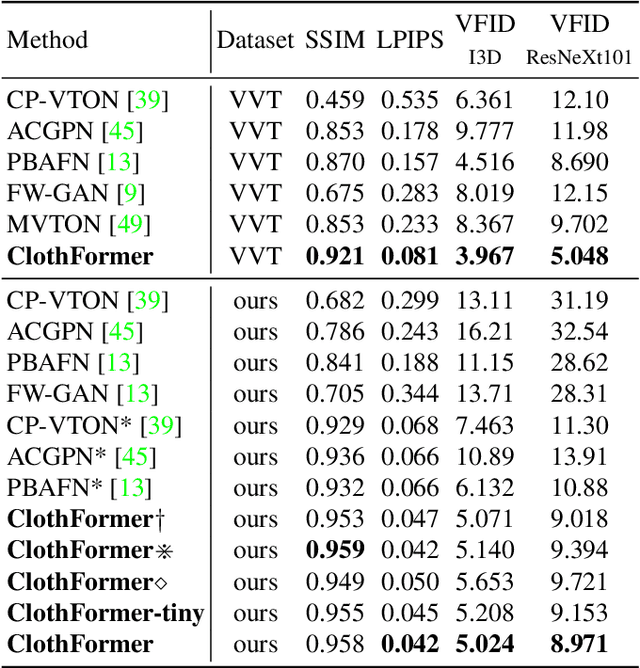
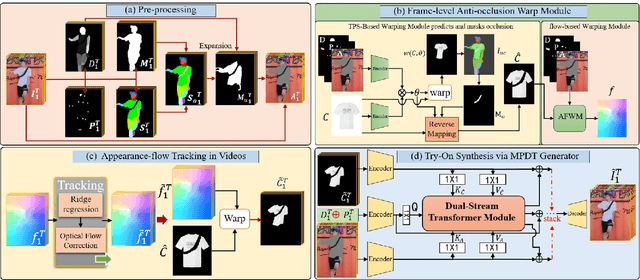
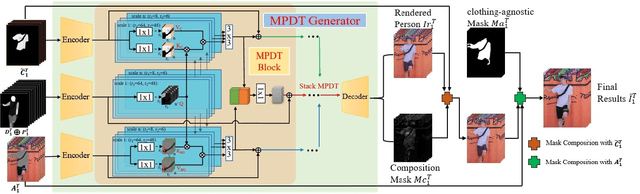
The task of video virtual try-on aims to fit the target clothes to a person in the video with spatio-temporal consistency. Despite tremendous progress of image virtual try-on, they lead to inconsistency between frames when applied to videos. Limited work also explored the task of video-based virtual try-on but failed to produce visually pleasing and temporally coherent results. Moreover, there are two other key challenges: 1) how to generate accurate warping when occlusions appear in the clothing region; 2) how to generate clothes and non-target body parts (e.g. arms, neck) in harmony with the complicated background; To address them, we propose a novel video virtual try-on framework, ClothFormer, which successfully synthesizes realistic, harmonious, and spatio-temporal consistent results in complicated environment. In particular, ClothFormer involves three major modules. First, a two-stage anti-occlusion warping module that predicts an accurate dense flow mapping between the body regions and the clothing regions. Second, an appearance-flow tracking module utilizes ridge regression and optical flow correction to smooth the dense flow sequence and generate a temporally smooth warped clothing sequence. Third, a dual-stream transformer extracts and fuses clothing textures, person features, and environment information to generate realistic try-on videos. Through rigorous experiments, we demonstrate that our method highly surpasses the baselines in terms of synthesized video quality both qualitatively and quantitatively.
Class Re-Activation Maps for Weakly-Supervised Semantic Segmentation
Mar 02, 2022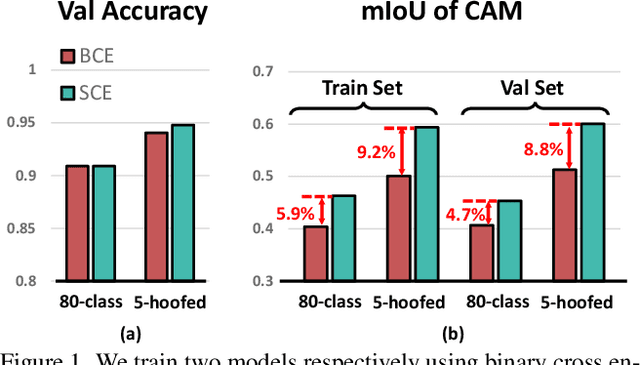
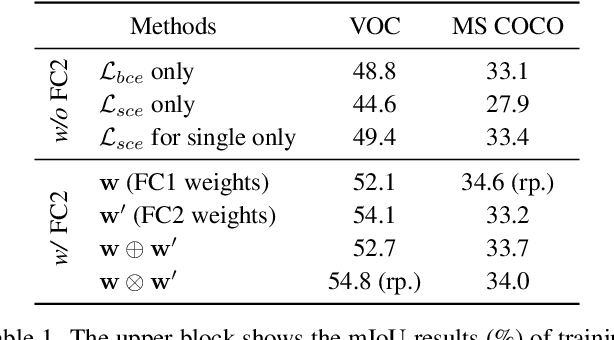
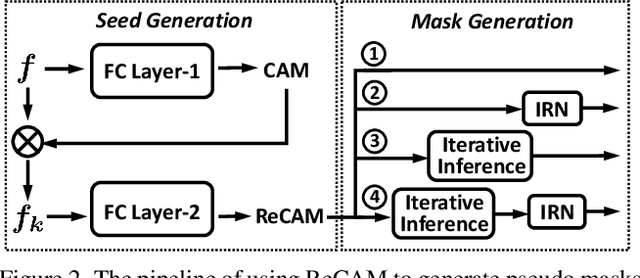
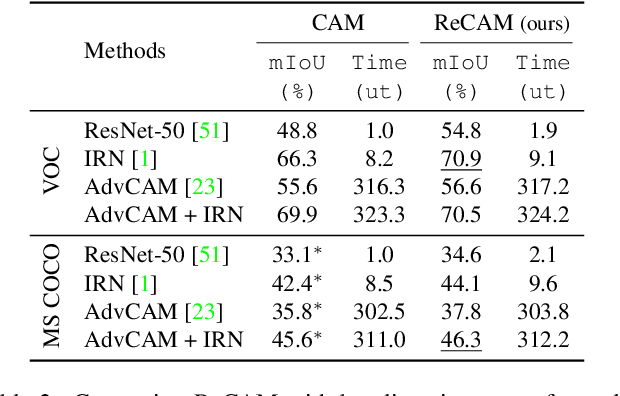
Extracting class activation maps (CAM) is arguably the most standard step of generating pseudo masks for weakly-supervised semantic segmentation (WSSS). Yet, we find that the crux of the unsatisfactory pseudo masks is the binary cross-entropy loss (BCE) widely used in CAM. Specifically, due to the sum-over-class pooling nature of BCE, each pixel in CAM may be responsive to multiple classes co-occurring in the same receptive field. As a result, given a class, its hot CAM pixels may wrongly invade the area belonging to other classes, or the non-hot ones may be actually a part of the class. To this end, we introduce an embarrassingly simple yet surprisingly effective method: Reactivating the converged CAM with BCE by using softmax cross-entropy loss (SCE), dubbed \textbf{ReCAM}. Given an image, we use CAM to extract the feature pixels of each single class, and use them with the class label to learn another fully-connected layer (after the backbone) with SCE. Once converged, we extract ReCAM in the same way as in CAM. Thanks to the contrastive nature of SCE, the pixel response is disentangled into different classes and hence less mask ambiguity is expected. The evaluation on both PASCAL VOC and MS~COCO shows that ReCAM not only generates high-quality masks, but also supports plug-and-play in any CAM variant with little overhead.