 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecLoR: Spectral Lookahead Rectification for Motion-Coherent Text-to-Video Generation
Jun 10, 2026Flow Matching has enabled robust text-to-video generation via latent ODE sampling. However, velocity approximation and numerical discretization errors inevitably accumulate, causing sampling trajectories to drift. Consequently, generated videos often suffer from severe spatiotemporal inconsistencies. Nevertheless, directly correcting these drifted, noisy latents is challenging: (i) timestep-dependent noise obscures reliable structural cues; (ii) spatial interventions risk disrupting intricate local geometry while incurring heavy computational costs. To address this, we propose Spectral Lookahead Rectification (SpecLoR), a plug-and-play inference method that bypasses noise via lookahead prediction, and circumvents spatiotemporal entanglement by shifting corrections to the frequency domain, where universal statistical priors of natural videos are readily available. First, during early sampling stages, SpecLoR looks ahead to estimate the clean latent $z_{t,0}$ and computes its 3D spatiotemporal spectrum. Next, SpecLoR rectifies the amplitude spectrum to match the prior, leaving the phase intact. Finally, the corrected state is re-noised to resume ODE integration. Experiments on Wan2.2 demonstrate that SpecLoR significantly reduces physical artifacts and enhances motion coherence across multiple benchmarks with minimal computational overhead (4 additional NFEs).
Learning De-Biased Representations for Remote-Sensing Imagery
Oct 06, 2024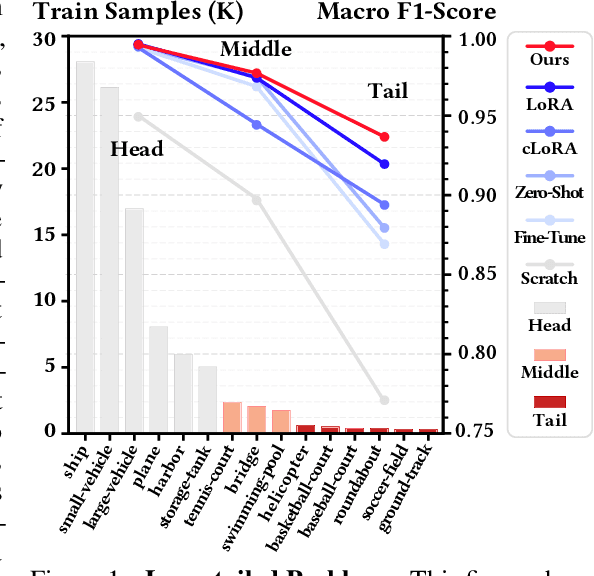
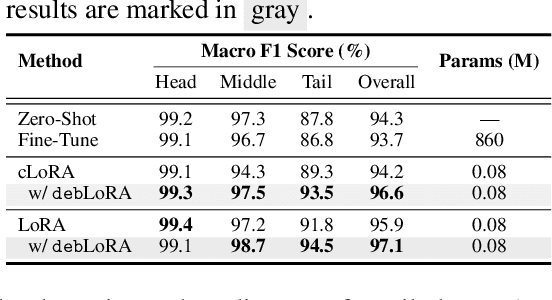
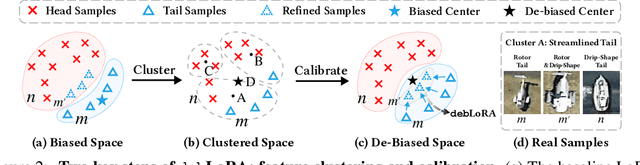
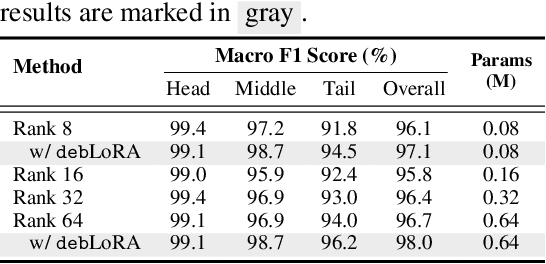
Remote sensing (RS) imagery, requiring specialized satellites to collect and being difficult to annotate, suffers from data scarcity and class imbalance in certain spectrums. Due to data scarcity, training any large-scale RS models from scratch is unrealistic, and the alternative is to transfer pre-trained models by fine-tuning or a more data-efficient method LoRA. Due to class imbalance, transferred models exhibit strong bias, where features of the major class dominate over those of the minor class. In this paper, we propose debLoRA, a generic training approach that works with any LoRA variants to yield debiased features. It is an unsupervised learning approach that can diversify minor class features based on the shared attributes with major classes, where the attributes are obtained by a simple step of clustering. To evaluate it, we conduct extensive experiments in two transfer learning scenarios in the RS domain: from natural to optical RS images, and from optical RS to multi-spectrum RS images. We perform object classification and oriented object detection tasks on the optical RS dataset DOTA and the SAR dataset FUSRS. Results show that our debLoRA consistently surpasses prior arts across these RS adaptation settings, yielding up to 3.3 and 4.7 percentage points gains on the tail classes for natural to optical RS and optical RS to multi-spectrum RS adaptations, respectively, while preserving the performance on head classes, substantiating its efficacy and adaptability.
Non-Visible Light Data Synthesis and Application: A Case Study for Synthetic Aperture Radar Imagery
Nov 29, 2023We explore the "hidden" ability of large-scale pre-trained image generation models, such as Stable Diffusion and Imagen, in non-visible light domains, taking Synthetic Aperture Radar (SAR) data for a case study. Due to the inherent challenges in capturing satellite data, acquiring ample SAR training samples is infeasible. For instance, for a particular category of ship in the open sea, we can collect only few-shot SAR images which are too limited to derive effective ship recognition models. If large-scale models pre-trained with regular images can be adapted to generating novel SAR images, the problem is solved. In preliminary study, we found that fine-tuning these models with few-shot SAR images is not working, as the models can not capture the two primary differences between SAR and regular images: structure and modality. To address this, we propose a 2-stage low-rank adaptation method, and we call it 2LoRA. In the first stage, the model is adapted using aerial-view regular image data (whose structure matches SAR), followed by the second stage where the base model from the first stage is further adapted using SAR modality data. Particularly in the second stage, we introduce a novel prototype LoRA (pLoRA), as an improved version of 2LoRA, to resolve the class imbalance problem in SAR datasets. For evaluation, we employ the resulting generation model to synthesize additional SAR data. This augmentation, when integrated into the training process of SAR classification as well as segmentation models, yields notably improved performance for minor classes
Weakly-Supervised Semantic Segmentation with Image-Level Labels: from Traditional Models to Foundation Models
Oct 19, 2023



The rapid development of deep learning has driven significant progress in the field of image semantic segmentation - a fundamental task in computer vision. Semantic segmentation algorithms often depend on the availability of pixel-level labels (i.e., masks of objects), which are expensive, time-consuming, and labor-intensive. Weakly-supervised semantic segmentation (WSSS) is an effective solution to avoid such labeling. It utilizes only partial or incomplete annotations and provides a cost-effective alternative to fully-supervised semantic segmentation. In this paper, we focus on the WSSS with image-level labels, which is the most challenging form of WSSS. Our work has two parts. First, we conduct a comprehensive survey on traditional methods, primarily focusing on those presented at premier research conferences. We categorize them into four groups based on where their methods operate: pixel-wise, image-wise, cross-image, and external data. Second, we investigate the applicability of visual foundation models, such as the Segment Anything Model (SAM), in the context of WSSS. We scrutinize SAM in two intriguing scenarios: text prompting and zero-shot learning. We provide insights into the potential and challenges associated with deploying visual foundational models for WSSS, facilitating future developments in this exciting research area.
Extracting Class Activation Maps from Non-Discriminative Features as well
Mar 18, 2023



Extracting class activation maps (CAM) from a classification model often results in poor coverage on foreground objects, i.e., only the discriminative region (e.g., the "head" of "sheep") is recognized and the rest (e.g., the "leg" of "sheep") mistakenly as background. The crux behind is that the weight of the classifier (used to compute CAM) captures only the discriminative features of objects. We tackle this by introducing a new computation method for CAM that explicitly captures non-discriminative features as well, thereby expanding CAM to cover whole objects. Specifically, we omit the last pooling layer of the classification model, and perform clustering on all local features of an object class, where "local" means "at a spatial pixel position". We call the resultant K cluster centers local prototypes - represent local semantics like the "head", "leg", and "body" of "sheep". Given a new image of the class, we compare its unpooled features to every prototype, derive K similarity matrices, and then aggregate them into a heatmap (i.e., our CAM). Our CAM thus captures all local features of the class without discrimination. We evaluate it in the challenging tasks of weakly-supervised semantic segmentation (WSSS), and plug it in multiple state-of-the-art WSSS methods, such as MCTformer and AMN, by simply replacing their original CAM with ours. Our extensive experiments on standard WSSS benchmarks (PASCAL VOC and MS COCO) show the superiority of our method: consistent improvements with little computational overhead.
Class Re-Activation Maps for Weakly-Supervised Semantic Segmentation
Mar 02, 2022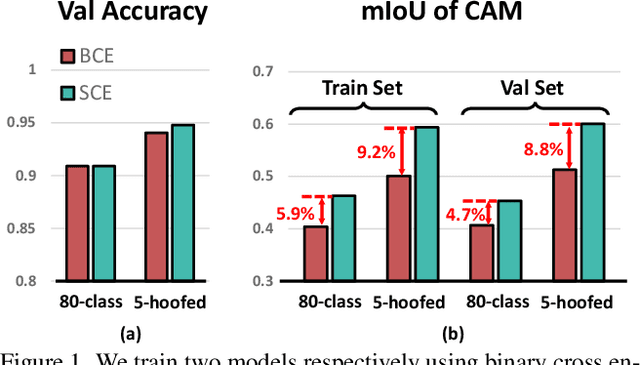
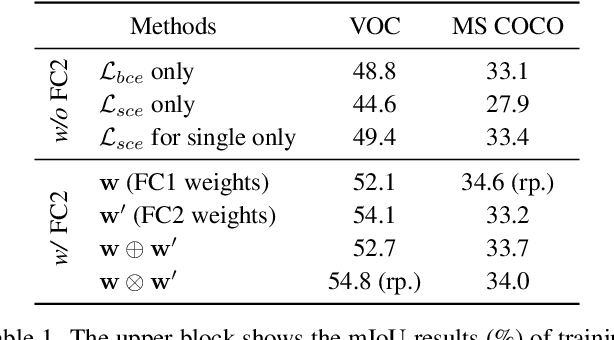
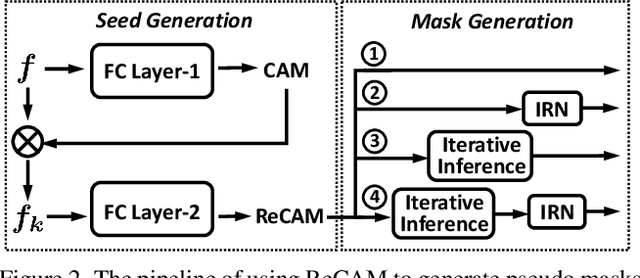
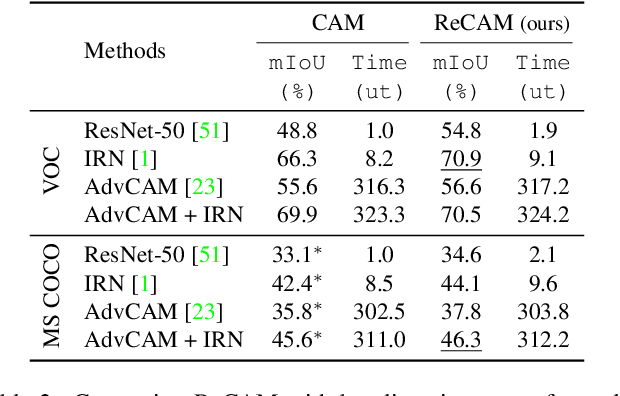
Extracting class activation maps (CAM) is arguably the most standard step of generating pseudo masks for weakly-supervised semantic segmentation (WSSS). Yet, we find that the crux of the unsatisfactory pseudo masks is the binary cross-entropy loss (BCE) widely used in CAM. Specifically, due to the sum-over-class pooling nature of BCE, each pixel in CAM may be responsive to multiple classes co-occurring in the same receptive field. As a result, given a class, its hot CAM pixels may wrongly invade the area belonging to other classes, or the non-hot ones may be actually a part of the class. To this end, we introduce an embarrassingly simple yet surprisingly effective method: Reactivating the converged CAM with BCE by using softmax cross-entropy loss (SCE), dubbed \textbf{ReCAM}. Given an image, we use CAM to extract the feature pixels of each single class, and use them with the class label to learn another fully-connected layer (after the backbone) with SCE. Once converged, we extract ReCAM in the same way as in CAM. Thanks to the contrastive nature of SCE, the pixel response is disentangled into different classes and hence less mask ambiguity is expected. The evaluation on both PASCAL VOC and MS~COCO shows that ReCAM not only generates high-quality masks, but also supports plug-and-play in any CAM variant with little overhead.
Meta-Transfer Learning through Hard Tasks
Oct 07, 2019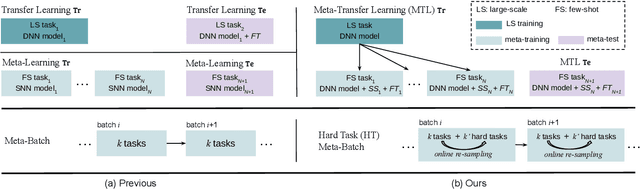
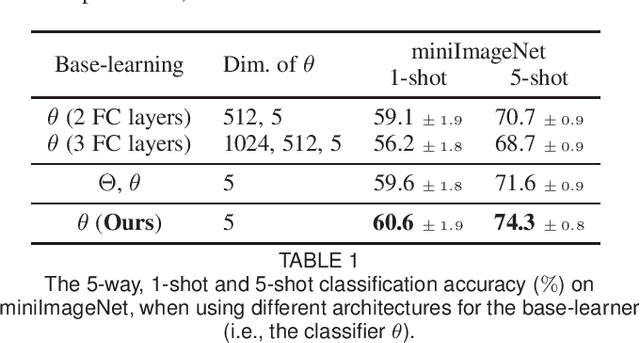

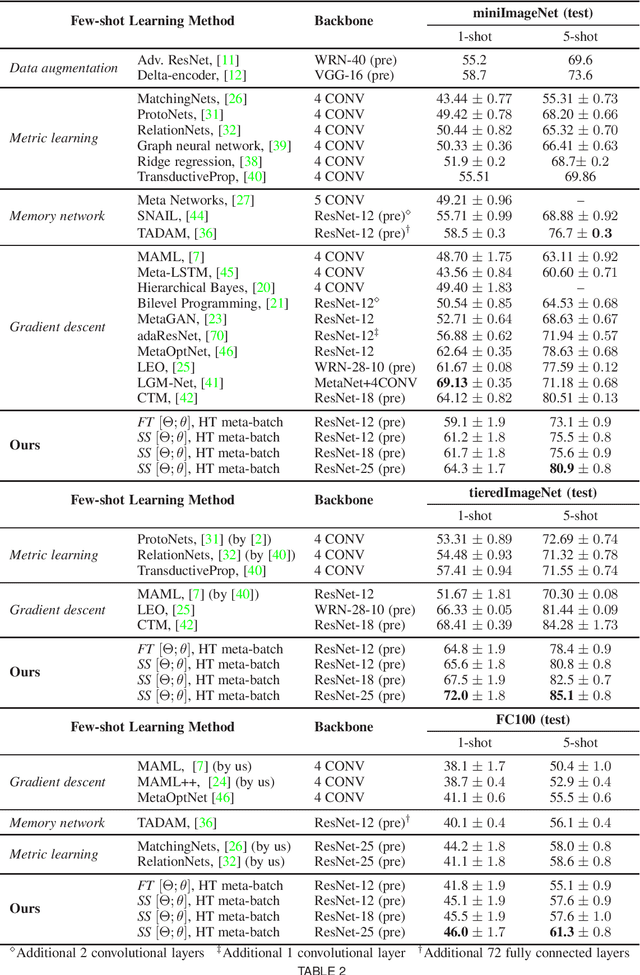
Meta-learning has been proposed as a framework to address the challenging few-shot learning setting. The key idea is to leverage a large number of similar few-shot tasks in order to learn how to adapt a base-learner to a new task for which only a few labeled samples are available. As deep neural networks (DNNs) tend to overfit using a few samples only, typical meta-learning models use shallow neural networks, thus limiting its effectiveness. In order to achieve top performance, some recent works tried to use the DNNs pre-trained on large-scale datasets but mostly in straight-forward manners, e.g., (1) taking their weights as a warm start of meta-training, and (2) freezing their convolutional layers as the feature extractor of base-learners. In this paper, we propose a novel approach called meta-transfer learning (MTL) which learns to transfer the weights of a deep NN for few-shot learning tasks. Specifically, meta refers to training multiple tasks, and transfer is achieved by learning scaling and shifting functions of DNN weights for each task. In addition, we introduce the hard task (HT) meta-batch scheme as an effective learning curriculum that further boosts the learning efficiency of MTL. We conduct few-shot learning experiments and report top performance for five-class few-shot recognition tasks on three challenging benchmarks: miniImageNet, tieredImageNet and Fewshot-CIFAR100 (FC100). Extensive comparisons to related works validate that our MTL approach trained with the proposed HT meta-batch scheme achieves top performance. An ablation study also shows that both components contribute to fast convergence and high accuracy.