 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Learning Hyperparameters for Parameter Efficient Fine-Tuning
Mar 02, 2026Training large foundation models from scratch for domain-specific applications is almost impossible due to data limits and long-tailed distributions -- taking remote sensing (RS) as an example. Fine-tuning natural image pre-trained models on RS images is a straightforward solution. To reduce computational costs and improve performance on tail classes, existing methods apply parameter-efficient fine-tuning (PEFT) techniques, such as LoRA and AdaptFormer. However, we observe that fixed hyperparameters -- such as intra-layer positions, layer depth, and scaling factors, can considerably hinder PEFT performance, as fine-tuning on RS images proves highly sensitive to these settings. To address this, we propose MetaPEFT, a method incorporating adaptive scalers that dynamically adjust module influence during fine-tuning. MetaPEFT dynamically adjusts three key factors of PEFT on RS images: module insertion, layer selection, and module-wise learning rates, which collectively control the influence of PEFT modules across the network. We conduct extensive experiments on three transfer-learning scenarios and five datasets in both RS and natural image domains. The results show that MetaPEFT achieves state-of-the-art performance in cross-spectral adaptation, requiring only a small amount of trainable parameters and improving tail-class accuracy significantly.
* Accepted by CVPR 2025 (Highlight). Code is available at: https://github.com/doem97/metalora
Scalable Multi-Task Low-Rank Model Adaptation
Mar 02, 2026Scaling multi-task low-rank adaptation (LoRA) to a large number of tasks induces catastrophic performance degradation, such as an accuracy drop from 88.2% to 2.0% on DOTA when scaling from 5 to 15 tasks. This failure is due to parameter and representation misalignment. We find that existing solutions, like regularization and dynamic routing, fail at scale because they are constrained by a fundamental trade-off: strengthening regularization to reduce inter-task conflict inadvertently suppresses the essential feature discrimination required for effective routing. In this work, we identify two root causes for this trade-off. First, uniform regularization disrupts inter-task knowledge sharing: shared underlying knowledge concentrates in high-SV components (89% alignment on Flanv2->BBH). Uniform regularization forces high-SV components to update in orthogonal directions, directly disrupting the shared knowledge. Second, Conflict Amplification: Applying LoRA at the component-level (e.g., W_q, W_v) amplifies gradient conflicts; we show block-level adaptation reduces this conflict by 76% with only 50% parameters. Based on these insights, we propose mtLoRA, a scalable solution with three novel designs: 1) Spectral-Aware Regularization to selectively orthogonalize low-SV components while preserving high-SV shared knowledge, 2) Block-Level Adaptation to mitigate conflict amplification and largely improve parameter efficiency, and 3) Fine-Grained Routing using dimension-specific weights for superior expressive power. On four large-scale (15-25 tasks) vision (DOTA and iNat2018) and NLP (Dolly-15k and BBH) benchmarks, mtLoRA achieves 91.7%, 81.5%, 44.5% and 38.5% accuracy on DOTA, iNat2018, Dolly-15k and BBH respectively, outperforming the state-of-the-art by 2.3% on average while using 47% fewer parameters and 24% less training time.
* Published as a conference paper at ICLR 2026. 21 pages, 4 figures, 11 tables. Code is available
CoVe: Training Interactive Tool-Use Agents via Constraint-Guided Verification
Mar 02, 2026Developing multi-turn interactive tool-use agents is challenging because real-world user needs are often complex and ambiguous, yet agents must execute deterministic actions to satisfy them. To address this gap, we introduce \textbf{CoVe} (\textbf{Co}nstraint-\textbf{Ve}rification), a post-training data synthesis framework designed for training interactive tool-use agents while ensuring both data complexity and correctness. CoVe begins by defining explicit task constraints, which serve a dual role: they guide the generation of complex trajectories and act as deterministic verifiers for assessing trajectory quality. This enables the creation of high-quality training trajectories for supervised fine-tuning (SFT) and the derivation of accurate reward signals for reinforcement learning (RL). Our evaluation on the challenging $τ^2$-bench benchmark demonstrates the effectiveness of the framework. Notably, our compact \textbf{CoVe-4B} model achieves success rates of 43.0\% and 59.4\% in the Airline and Retail domains, respectively; its overall performance significantly outperforms strong baselines of similar scale and remains competitive with models up to $17\times$ its size. These results indicate that CoVe provides an effective and efficient pathway for synthesizing training data for state-of-the-art interactive tool-use agents. To support future research, we open-source our code, trained model, and the full set of 12K high-quality trajectories used for training.
Learning De-Biased Representations for Remote-Sensing Imagery
Oct 06, 2024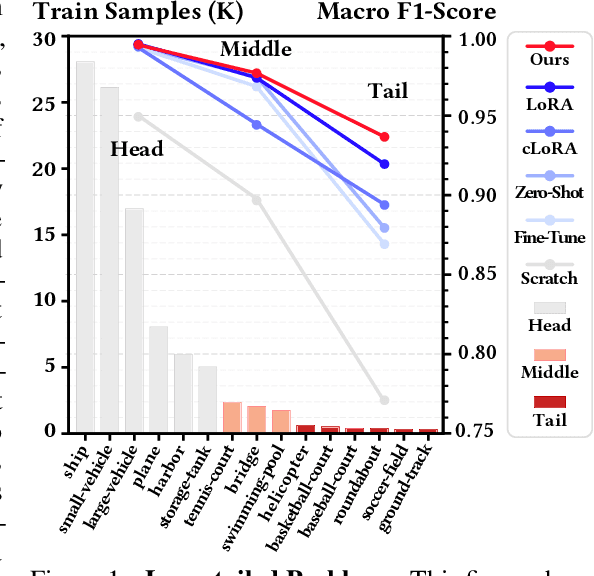
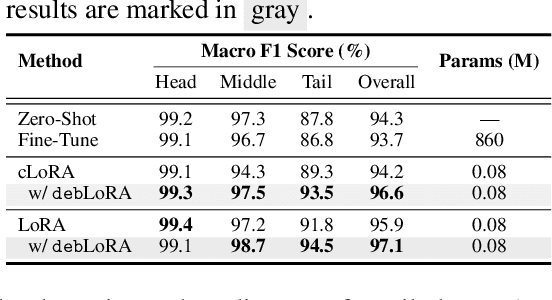
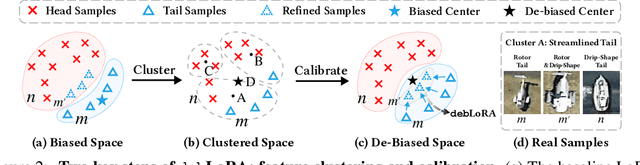
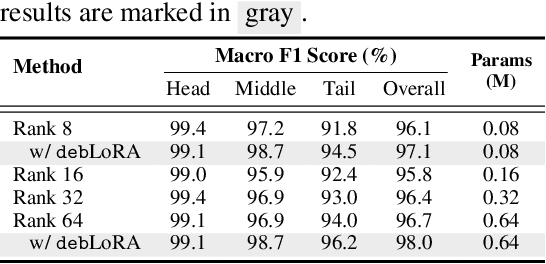
Remote sensing (RS) imagery, requiring specialized satellites to collect and being difficult to annotate, suffers from data scarcity and class imbalance in certain spectrums. Due to data scarcity, training any large-scale RS models from scratch is unrealistic, and the alternative is to transfer pre-trained models by fine-tuning or a more data-efficient method LoRA. Due to class imbalance, transferred models exhibit strong bias, where features of the major class dominate over those of the minor class. In this paper, we propose debLoRA, a generic training approach that works with any LoRA variants to yield debiased features. It is an unsupervised learning approach that can diversify minor class features based on the shared attributes with major classes, where the attributes are obtained by a simple step of clustering. To evaluate it, we conduct extensive experiments in two transfer learning scenarios in the RS domain: from natural to optical RS images, and from optical RS to multi-spectrum RS images. We perform object classification and oriented object detection tasks on the optical RS dataset DOTA and the SAR dataset FUSRS. Results show that our debLoRA consistently surpasses prior arts across these RS adaptation settings, yielding up to 3.3 and 4.7 percentage points gains on the tail classes for natural to optical RS and optical RS to multi-spectrum RS adaptations, respectively, while preserving the performance on head classes, substantiating its efficacy and adaptability.
Non-Visible Light Data Synthesis and Application: A Case Study for Synthetic Aperture Radar Imagery
Nov 29, 2023We explore the "hidden" ability of large-scale pre-trained image generation models, such as Stable Diffusion and Imagen, in non-visible light domains, taking Synthetic Aperture Radar (SAR) data for a case study. Due to the inherent challenges in capturing satellite data, acquiring ample SAR training samples is infeasible. For instance, for a particular category of ship in the open sea, we can collect only few-shot SAR images which are too limited to derive effective ship recognition models. If large-scale models pre-trained with regular images can be adapted to generating novel SAR images, the problem is solved. In preliminary study, we found that fine-tuning these models with few-shot SAR images is not working, as the models can not capture the two primary differences between SAR and regular images: structure and modality. To address this, we propose a 2-stage low-rank adaptation method, and we call it 2LoRA. In the first stage, the model is adapted using aerial-view regular image data (whose structure matches SAR), followed by the second stage where the base model from the first stage is further adapted using SAR modality data. Particularly in the second stage, we introduce a novel prototype LoRA (pLoRA), as an improved version of 2LoRA, to resolve the class imbalance problem in SAR datasets. For evaluation, we employ the resulting generation model to synthesize additional SAR data. This augmentation, when integrated into the training process of SAR classification as well as segmentation models, yields notably improved performance for minor classes
Domain Adaptive Scene Text Detection via Subcategorization
Dec 01, 2022Most existing scene text detectors require large-scale training data which cannot scale well due to two major factors: 1) scene text images often have domain-specific distributions; 2) collecting large-scale annotated scene text images is laborious. We study domain adaptive scene text detection, a largely neglected yet very meaningful task that aims for optimal transfer of labelled scene text images while handling unlabelled images in various new domains. Specifically, we design SCAST, a subcategory-aware self-training technique that mitigates the network overfitting and noisy pseudo labels in domain adaptive scene text detection effectively. SCAST consists of two novel designs. For labelled source data, it introduces pseudo subcategories for both foreground texts and background stuff which helps train more generalizable source models with multi-class detection objectives. For unlabelled target data, it mitigates the network overfitting by co-regularizing the binary and subcategory classifiers trained in the source domain. Extensive experiments show that SCAST achieves superior detection performance consistently across multiple public benchmarks, and it also generalizes well to other domain adaptive detection tasks such as vehicle detection.
Towards Efficient Use of Multi-Scale Features in Transformer-Based Object Detectors
Aug 24, 2022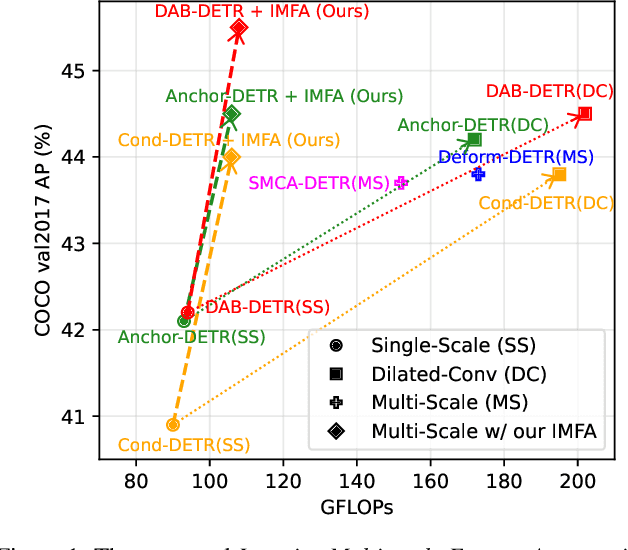
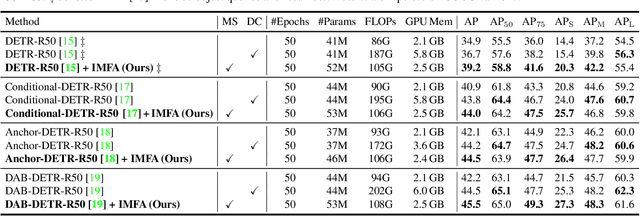
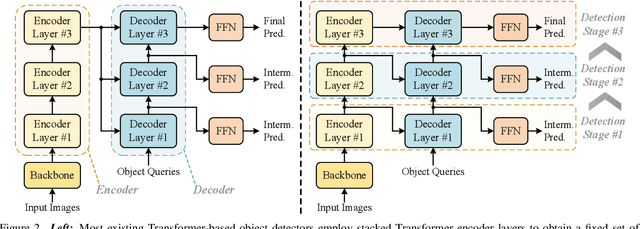
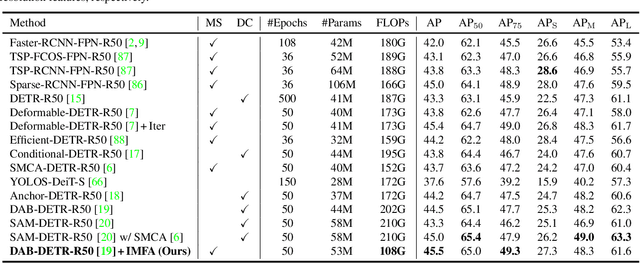
Multi-scale features have been proven highly effective for object detection, and most ConvNet-based object detectors adopt Feature Pyramid Network (FPN) as a basic component for exploiting multi-scale features. However, for the recently proposed Transformer-based object detectors, directly incorporating multi-scale features leads to prohibitive computational overhead due to the high complexity of the attention mechanism for processing high-resolution features. This paper presents Iterative Multi-scale Feature Aggregation (IMFA) -- a generic paradigm that enables the efficient use of multi-scale features in Transformer-based object detectors. The core idea is to exploit sparse multi-scale features from just a few crucial locations, and it is achieved with two novel designs. First, IMFA rearranges the Transformer encoder-decoder pipeline so that the encoded features can be iteratively updated based on the detection predictions. Second, IMFA sparsely samples scale-adaptive features for refined detection from just a few keypoint locations under the guidance of prior detection predictions. As a result, the sampled multi-scale features are sparse yet still highly beneficial for object detection. Extensive experiments show that the proposed IMFA boosts the performance of multiple Transformer-based object detectors significantly yet with slight computational overhead. Project page: https://github.com/ZhangGongjie/IMFA.
Fourier Document Restoration for Robust Document Dewarping and Recognition
Mar 18, 2022
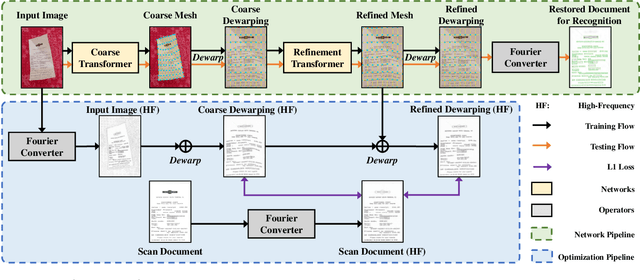
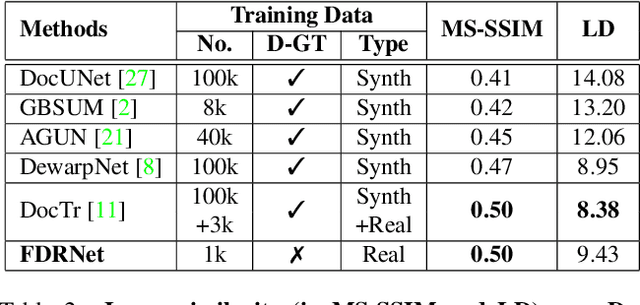
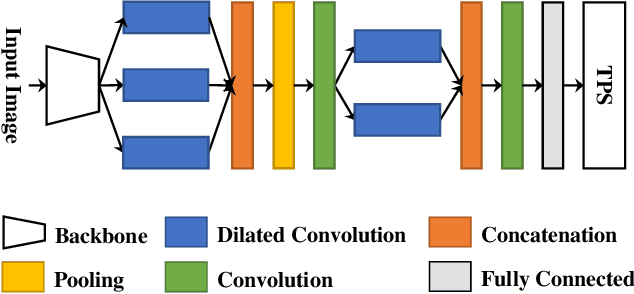
State-of-the-art document dewarping techniques learn to predict 3-dimensional information of documents which are prone to errors while dealing with documents with irregular distortions or large variations in depth. This paper presents FDRNet, a Fourier Document Restoration Network that can restore documents with different distortions and improve document recognition in a reliable and simpler manner. FDRNet focuses on high-frequency components in the Fourier space that capture most structural information but are largely free of degradation in appearance. It dewarps documents by a flexible Thin-Plate Spline transformation which can handle various deformations effectively without requiring deformation annotations in training. These features allow FDRNet to learn from a small amount of simply labeled training images, and the learned model can dewarp documents with complex geometric distortion and recognize the restored texts accurately. To facilitate document restoration research, we create a benchmark dataset consisting of over one thousand camera documents with different types of geometric and photometric distortion. Extensive experiments show that FDRNet outperforms the state-of-the-art by large margins on both dewarping and text recognition tasks. In addition, FDRNet requires a small amount of simply labeled training data and is easy to deploy.