 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Multi-Task Low-Rank Model Adaptation
Mar 02, 2026Scaling multi-task low-rank adaptation (LoRA) to a large number of tasks induces catastrophic performance degradation, such as an accuracy drop from 88.2% to 2.0% on DOTA when scaling from 5 to 15 tasks. This failure is due to parameter and representation misalignment. We find that existing solutions, like regularization and dynamic routing, fail at scale because they are constrained by a fundamental trade-off: strengthening regularization to reduce inter-task conflict inadvertently suppresses the essential feature discrimination required for effective routing. In this work, we identify two root causes for this trade-off. First, uniform regularization disrupts inter-task knowledge sharing: shared underlying knowledge concentrates in high-SV components (89% alignment on Flanv2->BBH). Uniform regularization forces high-SV components to update in orthogonal directions, directly disrupting the shared knowledge. Second, Conflict Amplification: Applying LoRA at the component-level (e.g., W_q, W_v) amplifies gradient conflicts; we show block-level adaptation reduces this conflict by 76% with only 50% parameters. Based on these insights, we propose mtLoRA, a scalable solution with three novel designs: 1) Spectral-Aware Regularization to selectively orthogonalize low-SV components while preserving high-SV shared knowledge, 2) Block-Level Adaptation to mitigate conflict amplification and largely improve parameter efficiency, and 3) Fine-Grained Routing using dimension-specific weights for superior expressive power. On four large-scale (15-25 tasks) vision (DOTA and iNat2018) and NLP (Dolly-15k and BBH) benchmarks, mtLoRA achieves 91.7%, 81.5%, 44.5% and 38.5% accuracy on DOTA, iNat2018, Dolly-15k and BBH respectively, outperforming the state-of-the-art by 2.3% on average while using 47% fewer parameters and 24% less training time.
* Published as a conference paper at ICLR 2026. 21 pages, 4 figures, 11 tables. Code is available
Generalization Bounds for Semi-supervised Matrix Completion with Distributional Side Information
Nov 17, 2025We study a matrix completion problem where both the ground truth $R$ matrix and the unknown sampling distribution $P$ over observed entries are low-rank matrices, and \textit{share a common subspace}. We assume that a large amount $M$ of \textit{unlabeled} data drawn from the sampling distribution $P$ is available, together with a small amount $N$ of labeled data drawn from the same distribution and noisy estimates of the corresponding ground truth entries. This setting is inspired by recommender systems scenarios where the unlabeled data corresponds to `implicit feedback' (consisting in interactions such as purchase, click, etc. ) and the labeled data corresponds to the `explicit feedback', consisting of interactions where the user has given an explicit rating to the item. Leveraging powerful results from the theory of low-rank subspace recovery, together with classic generalization bounds for matrix completion models, we show error bounds consisting of a sum of two error terms scaling as $\widetilde{O}\left(\sqrt{\frac{nd}{M}}\right)$ and $\widetilde{O}\left(\sqrt{\frac{dr}{N}}\right)$ respectively, where $d$ is the rank of $P$ and $r$ is the rank of $M$. In synthetic experiments, we confirm that the true generalization error naturally splits into independent error terms corresponding to the estimations of $P$ and and the ground truth matrix $\ground$ respectively. In real-life experiments on Douban and MovieLens with most explicit ratings removed, we demonstrate that the method can outperform baselines relying only on the explicit ratings, demonstrating that our assumptions provide a valid toy theoretical setting to study the interaction between explicit and implicit feedbacks in recommender systems.
Conv4Rec: A 1-by-1 Convolutional AutoEncoder for User Profiling through Joint Analysis of Implicit and Explicit Feedbacks
Sep 09, 2025We introduce a new convolutional AutoEncoder architecture for user modelling and recommendation tasks with several improvements over the state of the art. Firstly, our model has the flexibility to learn a set of associations and combinations between different interaction types in a way that carries over to each user and item. Secondly, our model is able to learn jointly from both the explicit ratings and the implicit information in the sampling pattern (which we refer to as `implicit feedback'). It can also make separate predictions for the probability of consuming content and the likelihood of granting it a high rating if observed. This not only allows the model to make predictions for both the implicit and explicit feedback, but also increases the informativeness of the predictions: in particular, our model can identify items which users would not have been likely to consume naturally, but would be likely to enjoy if exposed to them. Finally, we provide several generalization bounds for our model, which to the best of our knowledge, are among the first generalization bounds for auto-encoders in a Recommender Systems setting; we also show that optimizing our loss function guarantees the recovery of the exact sampling distribution over interactions up to a small error in total variation. In experiments on several real-life datasets, we achieve state-of-the-art performance on both the implicit and explicit feedback prediction tasks despite relying on a single model for both, and benefiting from additional interpretability in the form of individual predictions for the probabilities of each possible rating.
Explainable Neural Networks with Guarantees: A Sparse Estimation Approach
Jan 02, 2025



Balancing predictive power and interpretability has long been a challenging research area, particularly in powerful yet complex models like neural networks, where nonlinearity obstructs direct interpretation. This paper introduces a novel approach to constructing an explainable neural network that harmonizes predictiveness and explainability. Our model, termed SparXnet, is designed as a linear combination of a sparse set of jointly learned features, each derived from a different trainable function applied to a single 1-dimensional input feature. Leveraging the ability to learn arbitrarily complex relationships, our neural network architecture enables automatic selection of a sparse set of important features, with the final prediction being a linear combination of rescaled versions of these features. We demonstrate the ability to select significant features while maintaining comparable predictive performance and direct interpretability through extensive experiments on synthetic and real-world datasets. We also provide theoretical analysis on the generalization bounds of our framework, which is favorably linear in the number of selected features and only logarithmic in the number of input features. We further lift any dependence of sample complexity on the number of parameters or the architectural details under very mild conditions. Our research paves the way for further research on sparse and explainable neural networks with guarantee.
Generalization Analysis for Deep Contrastive Representation Learning
Dec 16, 2024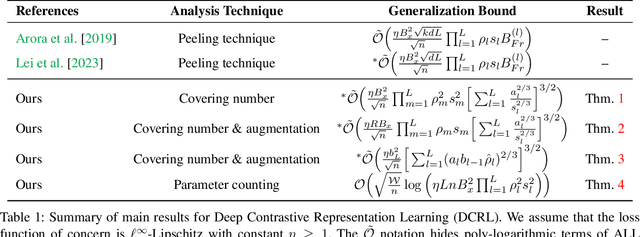
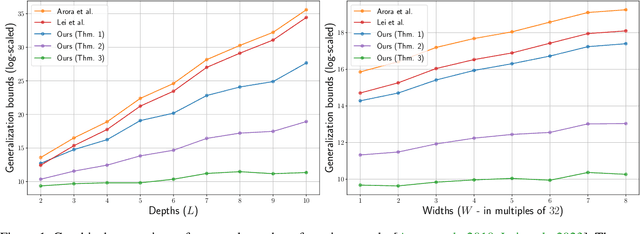


In this paper, we present generalization bounds for the unsupervised risk in the Deep Contrastive Representation Learning framework, which employs deep neural networks as representation functions. We approach this problem from two angles. On the one hand, we derive a parameter-counting bound that scales with the overall size of the neural networks. On the other hand, we provide a norm-based bound that scales with the norms of neural networks' weight matrices. Ignoring logarithmic factors, the bounds are independent of $k$, the size of the tuples provided for contrastive learning. To the best of our knowledge, this property is only shared by one other work, which employed a different proof strategy and suffers from very strong exponential dependence on the depth of the network which is due to a use of the peeling technique. Our results circumvent this by leveraging powerful results on covering numbers with respect to uniform norms over samples. In addition, we utilize loss augmentation techniques to further reduce the dependency on matrix norms and the implicit dependence on network depth. In fact, our techniques allow us to produce many bounds for the contrastive learning setting with similar architectural dependencies as in the study of the sample complexity of ordinary loss functions, thereby bridging the gap between the learning theories of contrastive learning and DNNs.
Interpretable Tensor Fusion
May 07, 2024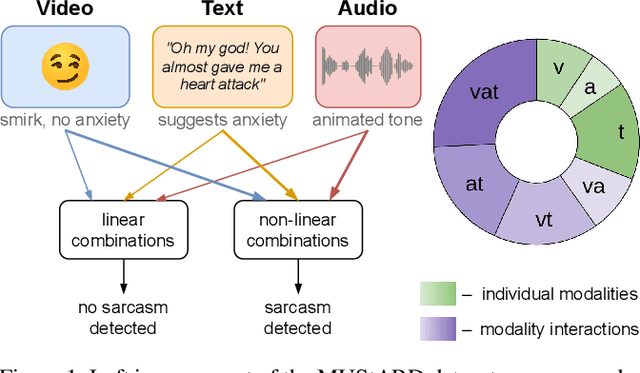
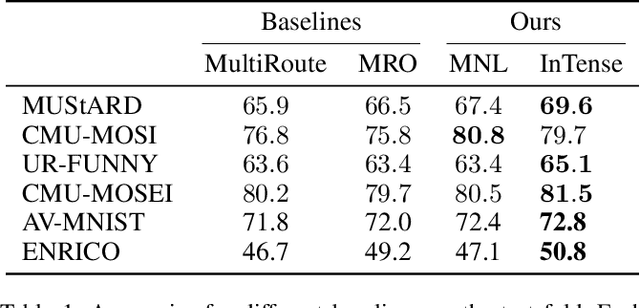
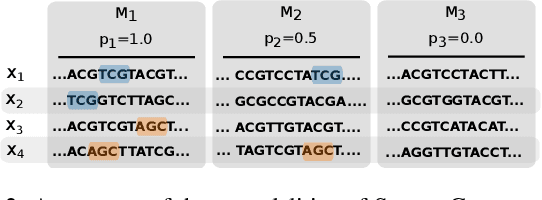
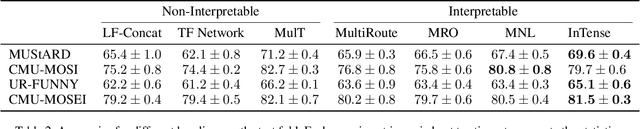
Conventional machine learning methods are predominantly designed to predict outcomes based on a single data type. However, practical applications may encompass data of diverse types, such as text, images, and audio. We introduce interpretable tensor fusion (InTense), a multimodal learning method for training neural networks to simultaneously learn multimodal data representations and their interpretable fusion. InTense can separately capture both linear combinations and multiplicative interactions of diverse data types, thereby disentangling higher-order interactions from the individual effects of each modality. InTense provides interpretability out of the box by assigning relevance scores to modalities and their associations. The approach is theoretically grounded and yields meaningful relevance scores on multiple synthetic and real-world datasets. Experiments on six real-world datasets show that InTense outperforms existing state-of-the-art multimodal interpretable approaches in terms of accuracy and interpretability.
Generalization Bounds for Inductive Matrix Completion in Low-noise Settings
Dec 16, 2022We study inductive matrix completion (matrix completion with side information) under an i.i.d. subgaussian noise assumption at a low noise regime, with uniform sampling of the entries. We obtain for the first time generalization bounds with the following three properties: (1) they scale like the standard deviation of the noise and in particular approach zero in the exact recovery case; (2) even in the presence of noise, they converge to zero when the sample size approaches infinity; and (3) for a fixed dimension of the side information, they only have a logarithmic dependence on the size of the matrix. Differently from many works in approximate recovery, we present results both for bounded Lipschitz losses and for the absolute loss, with the latter relying on Talagrand-type inequalities. The proofs create a bridge between two approaches to the theoretical analysis of matrix completion, since they consist in a combination of techniques from both the exact recovery literature and the approximate recovery literature.
* 30 Pages, 1 figure; Accepted for publication at AAAI 2023
Beyond Smoothness: Incorporating Low-Rank Analysis into Nonparametric Density Estimation
Apr 02, 2022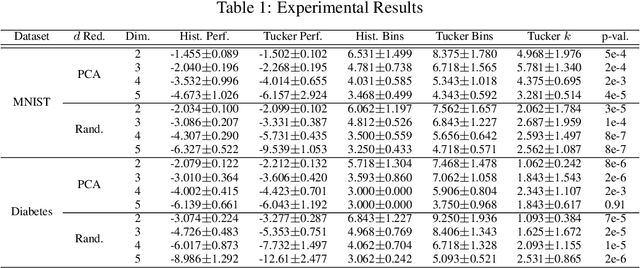
The construction and theoretical analysis of the most popular universally consistent nonparametric density estimators hinge on one functional property: smoothness. In this paper we investigate the theoretical implications of incorporating a multi-view latent variable model, a type of low-rank model, into nonparametric density estimation. To do this we perform extensive analysis on histogram-style estimators that integrate a multi-view model. Our analysis culminates in showing that there exists a universally consistent histogram-style estimator that converges to any multi-view model with a finite number of Lipschitz continuous components at a rate of $\widetilde{O}(1/\sqrt[3]{n})$ in $L^1$ error. In contrast, the standard histogram estimator can converge at a rate slower than $1/\sqrt[d]{n}$ on the same class of densities. We also introduce a new nonparametric latent variable model based on the Tucker decomposition. A rudimentary implementation of our estimators experimentally demonstrates a considerable performance improvement over the standard histogram estimator. We also provide a thorough analysis of the sample complexity of our Tucker decomposition-based model and a variety of other results. Thus, our paper provides solid theoretical foundations for extending low-rank techniques to the nonparametric setting
Learning Interpretable Concept Groups in CNNs
Sep 21, 2021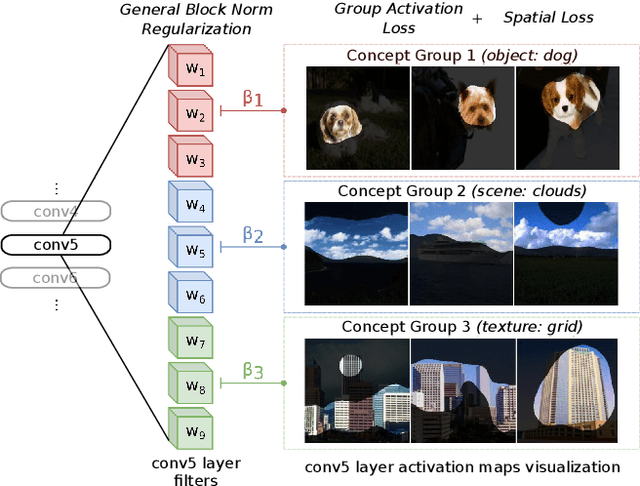
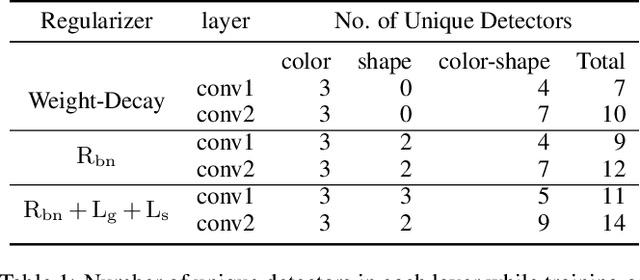
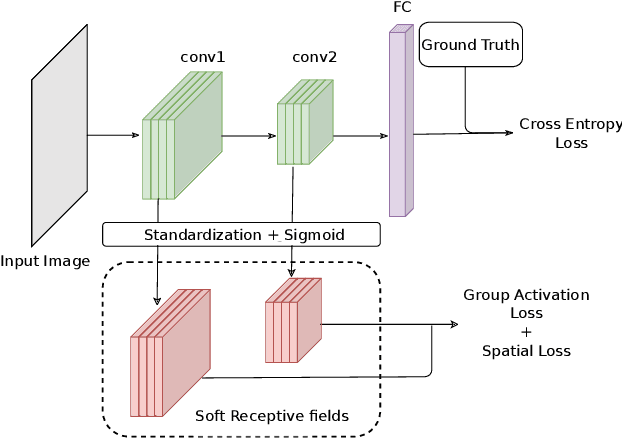
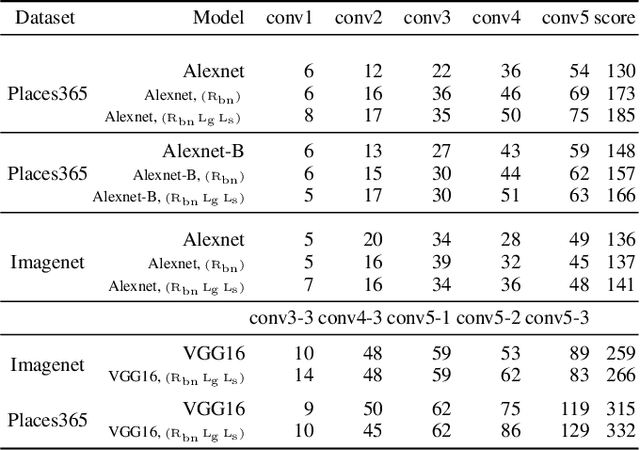
We propose a novel training methodology -- Concept Group Learning (CGL) -- that encourages training of interpretable CNN filters by partitioning filters in each layer into concept groups, each of which is trained to learn a single visual concept. We achieve this through a novel regularization strategy that forces filters in the same group to be active in similar image regions for a given layer. We additionally use a regularizer to encourage a sparse weighting of the concept groups in each layer so that a few concept groups can have greater importance than others. We quantitatively evaluate CGL's model interpretability using standard interpretability evaluation techniques and find that our method increases interpretability scores in most cases. Qualitatively we compare the image regions that are most active under filters learned using CGL versus filters learned without CGL and find that CGL activation regions more strongly concentrate around semantically relevant features.
Fine-grained Generalization Analysis of Structured Output Prediction
May 31, 2021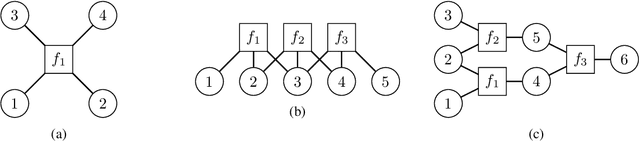
In machine learning we often encounter structured output prediction problems (SOPPs), i.e. problems where the output space admits a rich internal structure. Application domains where SOPPs naturally occur include natural language processing, speech recognition, and computer vision. Typical SOPPs have an extremely large label set, which grows exponentially as a function of the size of the output. Existing generalization analysis implies generalization bounds with at least a square-root dependency on the cardinality $d$ of the label set, which can be vacuous in practice. In this paper, we significantly improve the state of the art by developing novel high-probability bounds with a logarithmic dependency on $d$. Moreover, we leverage the lens of algorithmic stability to develop generalization bounds in expectation without any dependency on $d$. Our results therefore build a solid theoretical foundation for learning in large-scale SOPPs. Furthermore, we extend our results to learning with weakly dependent data.