 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimization, Generalization and Differential Privacy Bounds for Gradient Descent on Kolmogorov-Arnold Networks
Jan 29, 2026Kolmogorov--Arnold Networks (KANs) have recently emerged as a structured alternative to standard MLPs, yet a principled theory for their training dynamics, generalization, and privacy properties remains limited. In this paper, we analyze gradient descent (GD) for training two-layer KANs and derive general bounds that characterize their training dynamics, generalization, and utility under differential privacy (DP). As a concrete instantiation, we specialize our analysis to logistic loss under an NTK-separable assumption, where we show that polylogarithmic network width suffices for GD to achieve an optimization rate of order $1/T$ and a generalization rate of order $1/n$, with $T$ denoting the number of GD iterations and $n$ the sample size. In the private setting, we characterize the noise required for $(ε,δ)$-DP and obtain a utility bound of order $\sqrt{d}/(nε)$ (with $d$ the input dimension), matching the classical lower bound for general convex Lipschitz problems. Our results imply that polylogarithmic width is not only sufficient but also necessary under differential privacy, revealing a qualitative gap between non-private (sufficiency only) and private (necessity also emerges) training regimes. Experiments further illustrate how these theoretical insights can guide practical choices, including network width selection and early stopping.
Multi-level Supervised Contrastive Learning
Feb 05, 2025



Contrastive learning is a well-established paradigm in representation learning. The standard framework of contrastive learning minimizes the distance between "similar" instances and maximizes the distance between dissimilar ones in the projection space, disregarding the various aspects of similarity that can exist between two samples. Current methods rely on a single projection head, which fails to capture the full complexity of different aspects of a sample, leading to suboptimal performance, especially in scenarios with limited training data. In this paper, we present a novel supervised contrastive learning method in a unified framework called multilevel contrastive learning (MLCL), that can be applied to both multi-label and hierarchical classification tasks. The key strength of the proposed method is the ability to capture similarities between samples across different labels and/or hierarchies using multiple projection heads. Extensive experiments on text and image datasets demonstrate that the proposed approach outperforms state-of-the-art contrastive learning methods
Sparse Data Generation Using Diffusion Models
Feb 04, 2025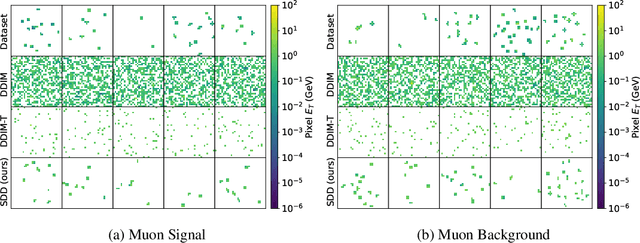
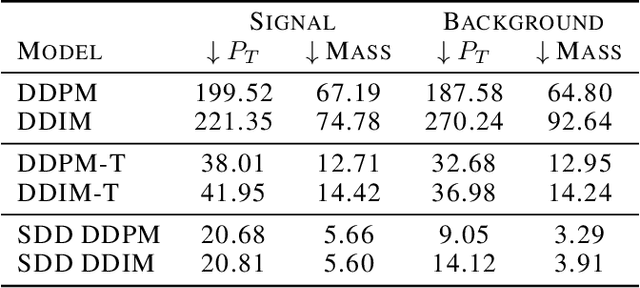
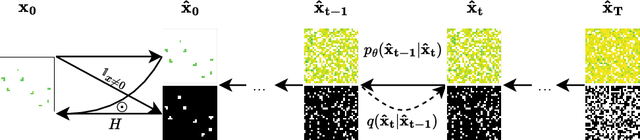
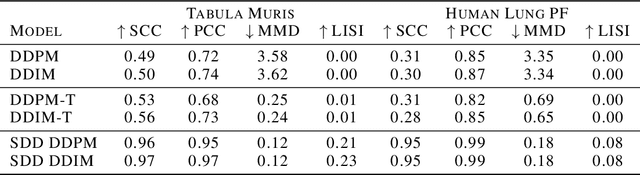
Sparse data is ubiquitous, appearing in numerous domains, from economics and recommender systems to astronomy and biomedical sciences. However, efficiently and realistically generating sparse data remains a significant challenge. We introduce Sparse Data Diffusion (SDD), a novel method for generating sparse data. SDD extends continuous state-space diffusion models by explicitly modeling sparsity through the introduction of Sparsity Bits. Empirical validation on image data from various domains-including two scientific applications, physics and biology-demonstrates that SDD achieves high fidelity in representing data sparsity while preserving the quality of the generated data.
Challenging Assumptions in Learning Generic Text Style Embeddings
Jan 27, 2025


Recent advancements in language representation learning primarily emphasize language modeling for deriving meaningful representations, often neglecting style-specific considerations. This study addresses this gap by creating generic, sentence-level style embeddings crucial for style-centric tasks. Our approach is grounded on the premise that low-level text style changes can compose any high-level style. We hypothesize that applying this concept to representation learning enables the development of versatile text style embeddings. By fine-tuning a general-purpose text encoder using contrastive learning and standard cross-entropy loss, we aim to capture these low-level style shifts, anticipating that they offer insights applicable to high-level text styles. The outcomes prompt us to reconsider the underlying assumptions as the results do not always show that the learned style representations capture high-level text styles.
Towards Graph Foundation Models: A Study on the Generalization of Positional and Structural Encodings
Dec 10, 2024Recent advances in integrating positional and structural encodings (PSEs) into graph neural networks (GNNs) have significantly enhanced their performance across various graph learning tasks. However, the general applicability of these encodings and their potential to serve as foundational representations for graphs remain uncertain. This paper investigates the fine-tuning efficiency, scalability with sample size, and generalization capability of learnable PSEs across diverse graph datasets. Specifically, we evaluate their potential as universal pre-trained models that can be easily adapted to new tasks with minimal fine-tuning and limited data. Furthermore, we assess the expressivity of the learned representations, particularly, when used to augment downstream GNNs. We demonstrate through extensive benchmarking and empirical analysis that PSEs generally enhance downstream models. However, some datasets may require specific PSE-augmentations to achieve optimal performance. Nevertheless, our findings highlight their significant potential to become integral components of future graph foundation models. We provide new insights into the strengths and limitations of PSEs, contributing to the broader discourse on foundation models in graph learning.
SetPINNs: Set-based Physics-informed Neural Networks
Sep 30, 2024Physics-Informed Neural Networks (PINNs) have emerged as a promising method for approximating solutions to partial differential equations (PDEs) using deep learning. However, PINNs, based on multilayer perceptrons (MLP), often employ point-wise predictions, overlooking the implicit dependencies within the physical system such as temporal or spatial dependencies. These dependencies can be captured using more complex network architectures, for example CNNs or Transformers. However, these architectures conventionally do not allow for incorporating physical constraints, as advancements in integrating such constraints within these frameworks are still lacking. Relying on point-wise predictions often results in trivial solutions. To address this limitation, we propose SetPINNs, a novel approach inspired by Finite Elements Methods from the field of Numerical Analysis. SetPINNs allow for incorporating the dependencies inherent in the physical system while at the same time allowing for incorporating the physical constraints. They accurately approximate PDE solutions of a region, thereby modeling the inherent dependencies between multiple neighboring points in that region. Our experiments show that SetPINNs demonstrate superior generalization performance and accuracy across diverse physical systems, showing that they mitigate failure modes and converge faster in comparison to existing approaches. Furthermore, we demonstrate the utility of SetPINNs on two real-world physical systems.
Comgra: A Tool for Analyzing and Debugging Neural Networks
Jul 31, 2024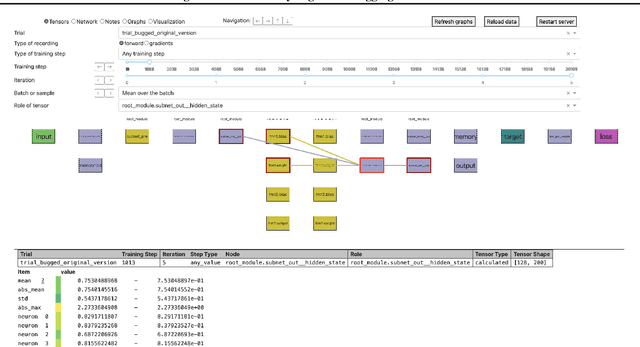
Neural Networks are notoriously difficult to inspect. We introduce comgra, an open source python library for use with PyTorch. Comgra extracts data about the internal activations of a model and organizes it in a GUI (graphical user interface). It can show both summary statistics and individual data points, compare early and late stages of training, focus on individual samples of interest, and visualize the flow of the gradient through the network. This makes it possible to inspect the model's behavior from many different angles and save time by rapidly testing different hypotheses without having to rerun it. Comgra has applications for debugging, neural architecture design, and mechanistic interpretability. We publish our library through Python Package Index (PyPI) and provide code, documentation, and tutorials at https://github.com/FlorianDietz/comgra.
Anomaly Detection of Tabular Data Using LLMs
Jun 24, 2024Large language models (LLMs) have shown their potential in long-context understanding and mathematical reasoning. In this paper, we study the problem of using LLMs to detect tabular anomalies and show that pre-trained LLMs are zero-shot batch-level anomaly detectors. That is, without extra distribution-specific model fitting, they can discover hidden outliers in a batch of data, demonstrating their ability to identify low-density data regions. For LLMs that are not well aligned with anomaly detection and frequently output factual errors, we apply simple yet effective data-generating processes to simulate synthetic batch-level anomaly detection datasets and propose an end-to-end fine-tuning strategy to bring out the potential of LLMs in detecting real anomalies. Experiments on a large anomaly detection benchmark (ODDS) showcase i) GPT-4 has on-par performance with the state-of-the-art transductive learning-based anomaly detection methods and ii) the efficacy of our synthetic dataset and fine-tuning strategy in aligning LLMs to this task.
AI-based Anomaly Detection for Clinical-Grade Histopathological Diagnostics
Jun 21, 2024



While previous studies have demonstrated the potential of AI to diagnose diseases in imaging data, clinical implementation is still lagging behind. This is partly because AI models require training with large numbers of examples only available for common diseases. In clinical reality, however, only few diseases are common, whereas the majority of diseases are less frequent (long-tail distribution). Current AI models overlook or misclassify these diseases. We propose a deep anomaly detection approach that only requires training data from common diseases to detect also all less frequent diseases. We collected two large real-world datasets of gastrointestinal biopsies, which are prototypical of the problem. Herein, the ten most common findings account for approximately 90% of cases, whereas the remaining 10% contained 56 disease entities, including many cancers. 17 million histological images from 5,423 cases were used for training and evaluation. Without any specific training for the diseases, our best-performing model reliably detected a broad spectrum of infrequent ("anomalous") pathologies with 95.0% (stomach) and 91.0% (colon) AUROC and generalized across scanners and hospitals. By design, the proposed anomaly detection can be expected to detect any pathological alteration in the diagnostic tail of gastrointestinal biopsies, including rare primary or metastatic cancers. This study establishes the first effective clinical application of AI-based anomaly detection in histopathology that can flag anomalous cases, facilitate case prioritization, reduce missed diagnoses and enhance the general safety of AI models, thereby driving AI adoption and automation in routine diagnostics and beyond.
Interpretable Tensor Fusion
May 07, 2024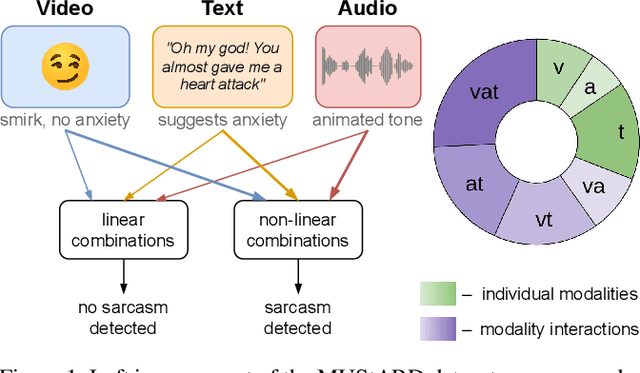
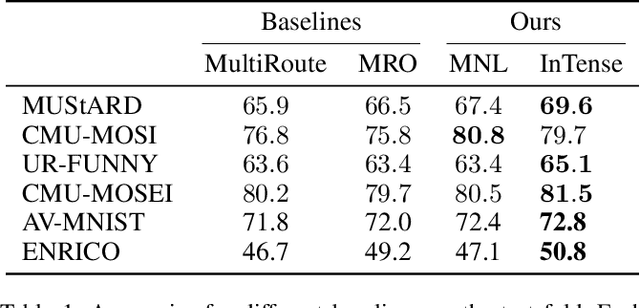
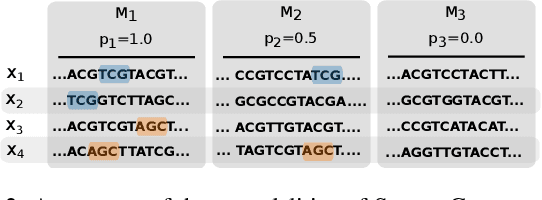
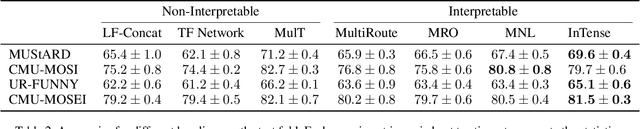
Conventional machine learning methods are predominantly designed to predict outcomes based on a single data type. However, practical applications may encompass data of diverse types, such as text, images, and audio. We introduce interpretable tensor fusion (InTense), a multimodal learning method for training neural networks to simultaneously learn multimodal data representations and their interpretable fusion. InTense can separately capture both linear combinations and multiplicative interactions of diverse data types, thereby disentangling higher-order interactions from the individual effects of each modality. InTense provides interpretability out of the box by assigning relevance scores to modalities and their associations. The approach is theoretically grounded and yields meaningful relevance scores on multiple synthetic and real-world datasets. Experiments on six real-world datasets show that InTense outperforms existing state-of-the-art multimodal interpretable approaches in terms of accuracy and interpretability.