 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Challenges and Opportunities in Generative AI
Feb 28, 2024The field of deep generative modeling has grown rapidly and consistently over the years. With the availability of massive amounts of training data coupled with advances in scalable unsupervised learning paradigms, recent large-scale generative models show tremendous promise in synthesizing high-resolution images and text, as well as structured data such as videos and molecules. However, we argue that current large-scale generative AI models do not sufficiently address several fundamental issues that hinder their widespread adoption across domains. In this work, we aim to identify key unresolved challenges in modern generative AI paradigms that should be tackled to further enhance their capabilities, versatility, and reliability. By identifying these challenges, we aim to provide researchers with valuable insights for exploring fruitful research directions, thereby fostering the development of more robust and accessible generative AI solutions.
MixerFlow for Image Modelling
Oct 25, 2023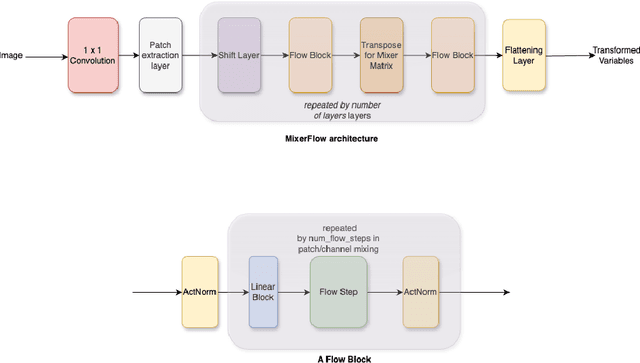
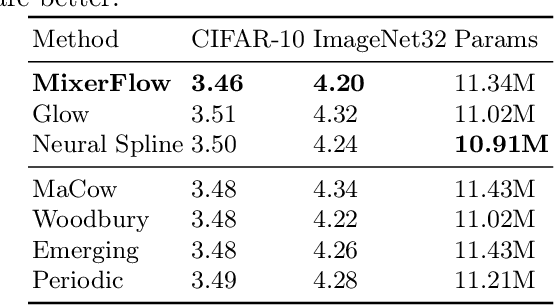

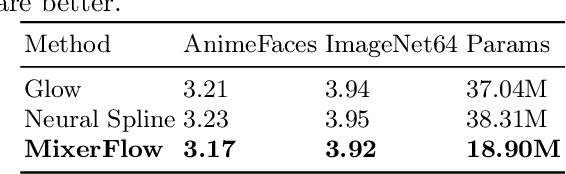
Normalising flows are statistical models that transform a complex density into a simpler density through the use of bijective transformations enabling both density estimation and data generation from a single model. In the context of image modelling, the predominant choice has been the Glow-based architecture, whereas alternative architectures remain largely unexplored in the research community. In this work, we propose a novel architecture called MixerFlow, based on the MLP-Mixer architecture, further unifying the generative and discriminative modelling architectures. MixerFlow offers an effective mechanism for weight sharing for flow-based models. Our results demonstrate better density estimation on image datasets under a fixed computational budget and scales well as the image resolution increases, making MixeFlow a powerful yet simple alternative to the Glow-based architectures. We also show that MixerFlow provides more informative embeddings than Glow-based architectures.
Kernelised Normalising Flows
Jul 27, 2023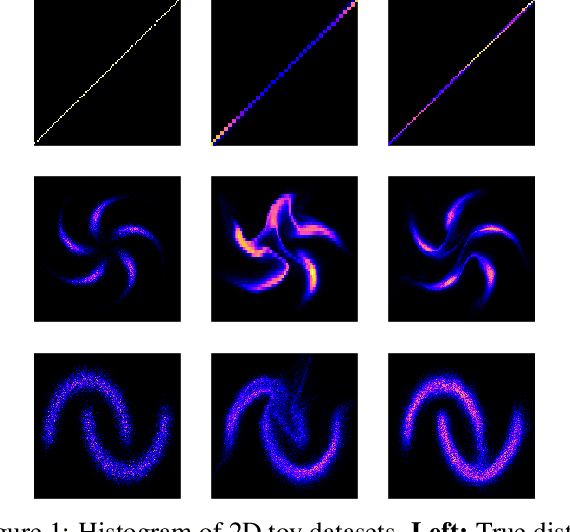
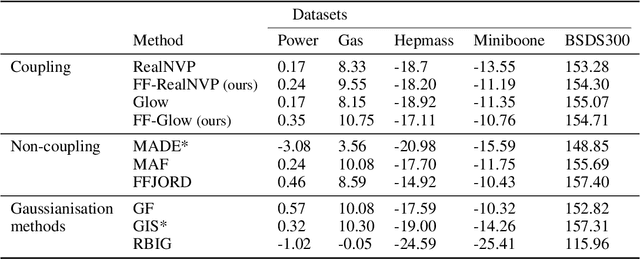
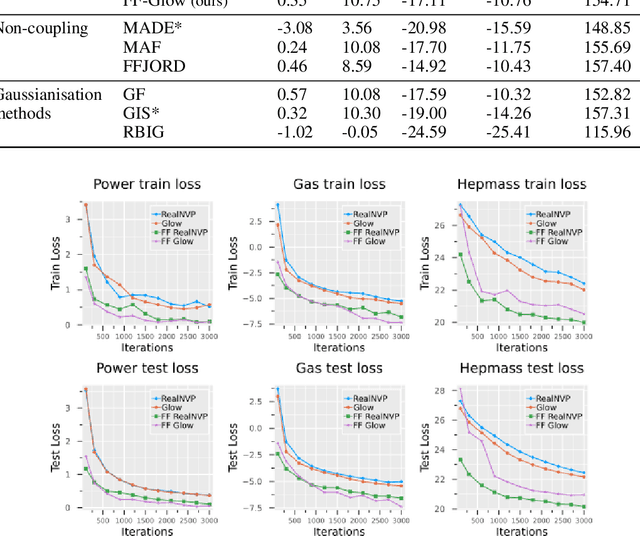
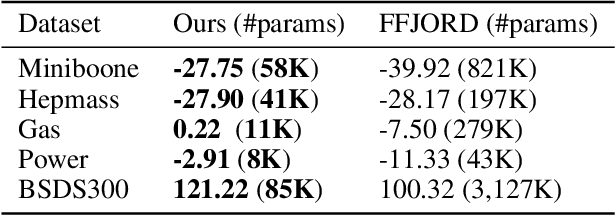
Normalising Flows are generative models characterised by their invertible architecture. However, the requirement of invertibility imposes constraints on their expressiveness, necessitating a large number of parameters and innovative architectural designs to achieve satisfactory outcomes. Whilst flow-based models predominantly rely on neural-network-based transformations for expressive designs, alternative transformation methods have received limited attention. In this work, we present Ferumal flow, a novel kernelised normalising flow paradigm that integrates kernels into the framework. Our results demonstrate that a kernelised flow can yield competitive or superior results compared to neural network-based flows whilst maintaining parameter efficiency. Kernelised flows excel especially in the low-data regime, enabling flexible non-parametric density estimation in applications with sparse data availability.
Training Normalizing Flows from Dependent Data
Sep 29, 2022
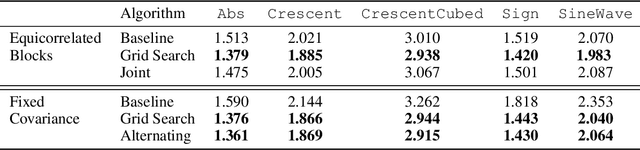


Normalizing flows are powerful non-parametric statistical models that function as a hybrid between density estimators and generative models. Current learning algorithms for normalizing flows assume that data points are sampled independently, an assumption that is frequently violated in practice, which may lead to erroneous density estimation and data generation. We propose a likelihood objective of normalizing flows incorporating dependencies between the data points, for which we derive a flexible and efficient learning algorithm suitable for different dependency structures. We show that respecting dependencies between observations can improve empirical results on both synthetic and real-world data.
ContIG: Self-supervised Multimodal Contrastive Learning for Medical Imaging with Genetics
Nov 26, 2021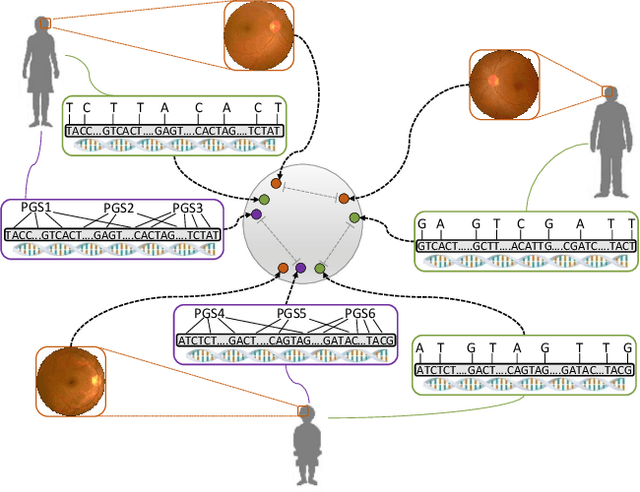
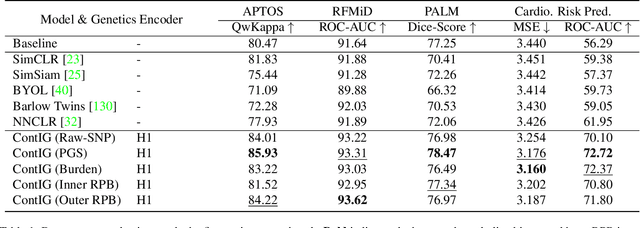
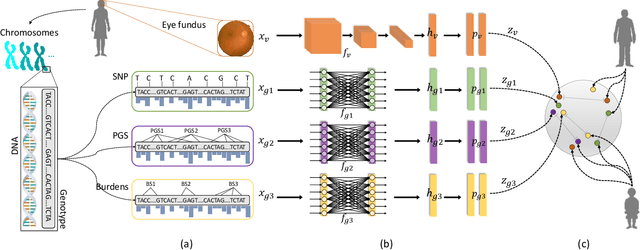
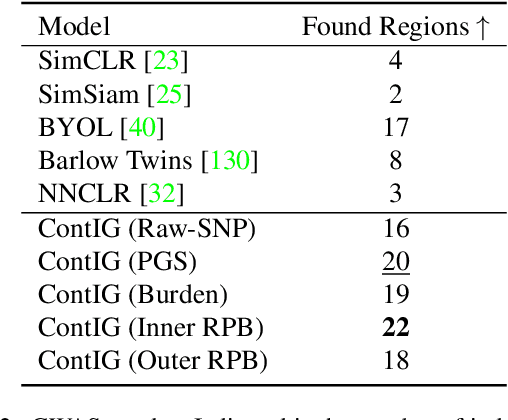
High annotation costs are a substantial bottleneck in applying modern deep learning architectures to clinically relevant medical use cases, substantiating the need for novel algorithms to learn from unlabeled data. In this work, we propose ContIG, a self-supervised method that can learn from large datasets of unlabeled medical images and genetic data. Our approach aligns images and several genetic modalities in the feature space using a contrastive loss. We design our method to integrate multiple modalities of each individual person in the same model end-to-end, even when the available modalities vary across individuals. Our procedure outperforms state-of-the-art self-supervised methods on all evaluated downstream benchmark tasks. We also adapt gradient-based explainability algorithms to better understand the learned cross-modal associations between the images and genetic modalities. Finally, we perform genome-wide association studies on the features learned by our models, uncovering interesting relationships between images and genetic data.
Explainability Requires Interactivity
Sep 16, 2021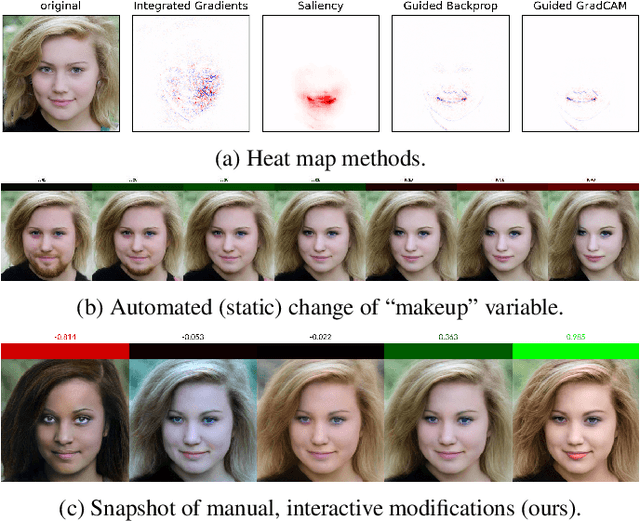

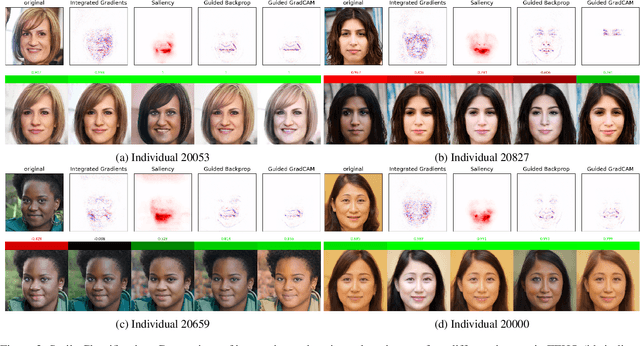

When explaining the decisions of deep neural networks, simple stories are tempting but dangerous. Especially in computer vision, the most popular explanation approaches give a false sense of comprehension to its users and provide an overly simplistic picture. We introduce an interactive framework to understand the highly complex decision boundaries of modern vision models. It allows the user to exhaustively inspect, probe, and test a network's decisions. Across a range of case studies, we compare the power of our interactive approach to static explanation methods, showing how these can lead a user astray, with potentially severe consequences.
Two-sample Testing Using Deep Learning
Oct 14, 2019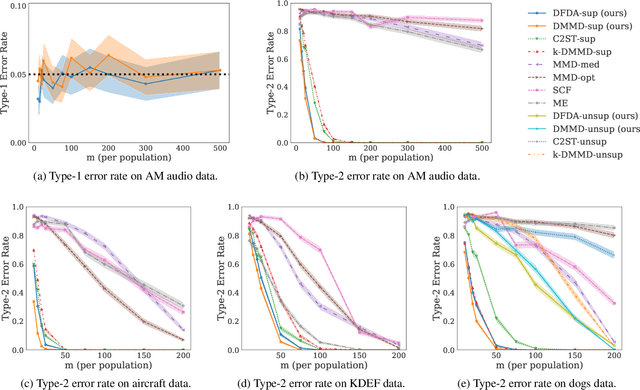
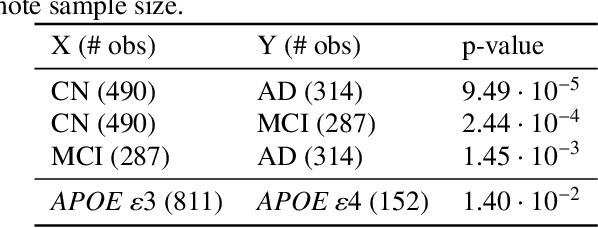
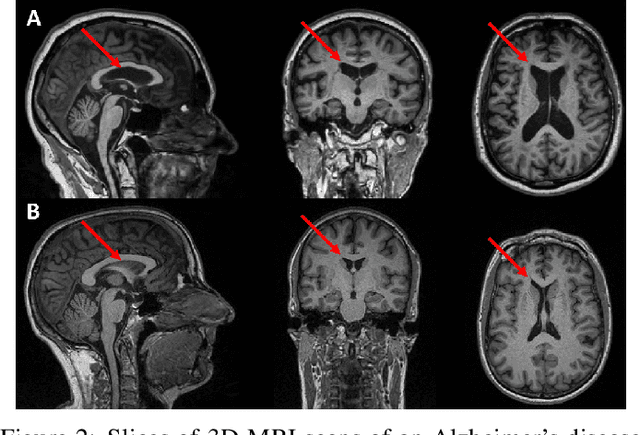
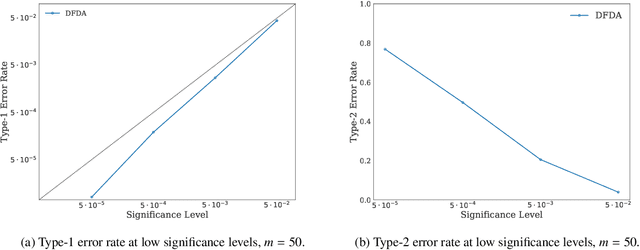
We propose a two-sample testing procedure based on learned deep neural network representations. To this end, we define two test statistics that perform an asymptotic location test on data samples mapped onto a hidden layer. The tests are consistent and asymptotically control the type-1 error rate. Their test statistics can be evaluated in linear time (in the sample size). Suitable data representations are obtained in a data-driven way, by solving a supervised or unsupervised transfer-learning task on an auxiliary (potentially distinct) data set. If no auxiliary data is available, we split the data into two chunks: one for learning representations and one for computing the test statistic. In experiments on audio samples, natural images and three-dimensional neuroimaging data our tests yield significant decreases in type-2 error rate (up to 35 percentage points) compared to state-of-the-art two-sample tests such as kernel-methods and classifier two-sample tests.