 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear-LLM-SCM: Benchmarking LLMs for Coefficient Elicitation in Linear-Gaussian Causal Models
Feb 10, 2026Large language models (LLMs) have shown potential in identifying qualitative causal relations, but their ability to perform quantitative causal reasoning -- estimating effect sizes that parametrize functional relationships -- remains underexplored in continuous domains. We introduce Linear-LLM-SCM, a plug-and-play benchmarking framework for evaluating LLMs on linear Gaussian structural causal model (SCM) parametrization when the DAG is given. The framework decomposes a DAG into local parent-child sets and prompts an LLM to produce a regression-style structural equation per node, which is aggregated and compared against available ground-truth parameters. Our experiments show several challenges in such benchmarking tasks, namely, strong stochasticity in the results in some of the models and susceptibility to DAG misspecification via spurious edges in the continuous domains. Across models, we observe substantial variability in coefficient estimates for some settings and sensitivity to structural and semantic perturbations, highlighting current limitations of LLMs as quantitative causal parameterizers. We also open-sourced the benchmarking framework so that researchers can utilize their DAGs and any off-the-shelf LLMs plug-and-play for evaluation in their domains effortlessly.
Is BatchEnsemble a Single Model? On Calibration and Diversity of Efficient Ensembles
Jan 23, 2026In resource-constrained and low-latency settings, uncertainty estimates must be efficiently obtained. Deep Ensembles provide robust epistemic uncertainty (EU) but require training multiple full-size models. BatchEnsemble aims to deliver ensemble-like EU at far lower parameter and memory cost by applying learned rank-1 perturbations to a shared base network. We show that BatchEnsemble not only underperforms Deep Ensembles but closely tracks a single model baseline in terms of accuracy, calibration and out-of-distribution (OOD) detection on CIFAR10/10C/SVHN. A controlled study on MNIST finds members are near-identical in function and parameter space, indicating limited capacity to realize distinct predictive modes. Thus, BatchEnsemble behaves more like a single model than a true ensemble.
Probably Approximately Global Robustness Certification
Nov 09, 2025We propose and investigate probabilistic guarantees for the adversarial robustness of classification algorithms. While traditional formal verification approaches for robustness are intractable and sampling-based approaches do not provide formal guarantees, our approach is able to efficiently certify a probabilistic relaxation of robustness. The key idea is to sample an $ε$-net and invoke a local robustness oracle on the sample. Remarkably, the size of the sample needed to achieve probably approximately global robustness guarantees is independent of the input dimensionality, the number of classes, and the learning algorithm itself. Our approach can, therefore, be applied even to large neural networks that are beyond the scope of traditional formal verification. Experiments empirically confirm that it characterizes robustness better than state-of-the-art sampling-based approaches and scales better than formal methods.
WILTing Trees: Interpreting the Distance Between MPNN Embeddings
May 30, 2025We investigate the distance function learned by message passing neural networks (MPNNs) in specific tasks, aiming to capture the functional distance between prediction targets that MPNNs implicitly learn. This contrasts with previous work, which links MPNN distances on arbitrary tasks to structural distances on graphs that ignore task-specific information. To address this gap, we distill the distance between MPNN embeddings into an interpretable graph distance. Our method uses optimal transport on the Weisfeiler Leman Labeling Tree (WILT), where the edge weights reveal subgraphs that strongly influence the distance between embeddings. This approach generalizes two well-known graph kernels and can be computed in linear time. Through extensive experiments, we demonstrate that MPNNs define the relative position of embeddings by focusing on a small set of subgraphs that are known to be functionally important in the domain.
Towards Foundation Models on Graphs: An Analysis on Cross-Dataset Transfer of Pretrained GNNs
Dec 23, 2024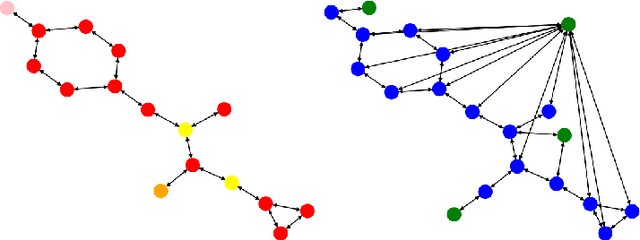
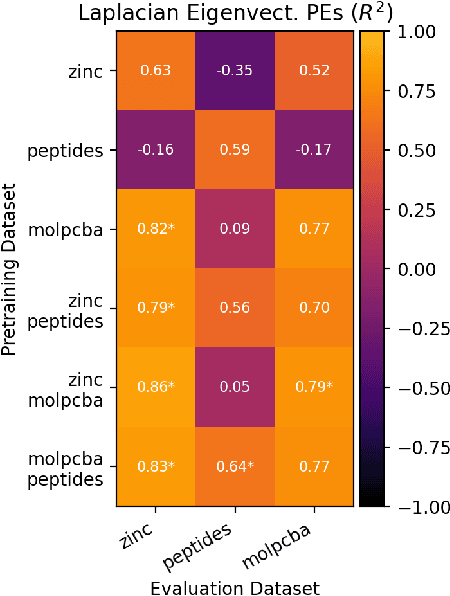
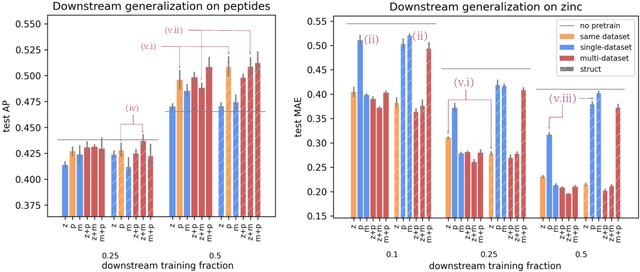
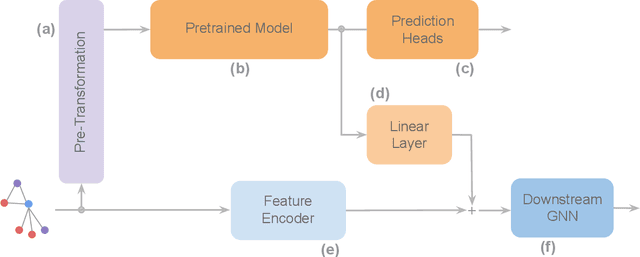
To develop a preliminary understanding towards Graph Foundation Models, we study the extent to which pretrained Graph Neural Networks can be applied across datasets, an effort requiring to be agnostic to dataset-specific features and their encodings. We build upon a purely structural pretraining approach and propose an extension to capture feature information while still being feature-agnostic. We evaluate pretrained models on downstream tasks for varying amounts of training samples and choices of pretraining datasets. Our preliminary results indicate that embeddings from pretrained models improve generalization only with enough downstream data points and in a degree which depends on the quantity and properties of pretraining data. Feature information can lead to improvements, but currently requires some similarities between pretraining and downstream feature spaces.
Logical Distillation of Graph Neural Networks
Jun 11, 2024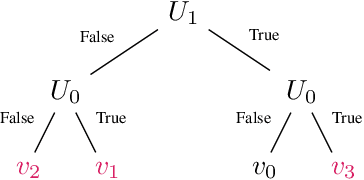
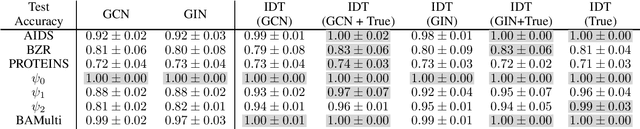
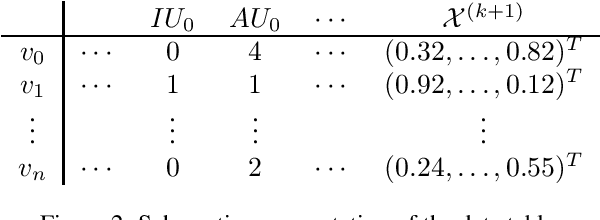
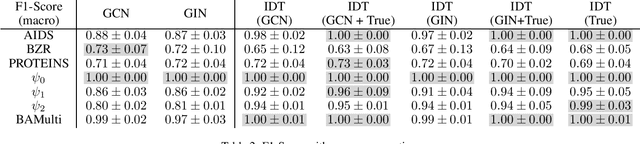
We present a logic based interpretable model for learning on graphs and an algorithm to distill this model from a Graph Neural Network (GNN). Recent results have shown connections between the expressivity of GNNs and the two-variable fragment of first-order logic with counting quantifiers (C2). We introduce a decision-tree based model which leverages an extension of C2 to distill interpretable logical classifiers from GNNs. We test our approach on multiple GNN architectures. The distilled models are interpretable, succinct, and attain similar accuracy to the underlying GNN. Furthermore, when the ground truth is expressible in C2, our approach outperforms the GNN.
On the Challenges and Opportunities in Generative AI
Feb 28, 2024The field of deep generative modeling has grown rapidly and consistently over the years. With the availability of massive amounts of training data coupled with advances in scalable unsupervised learning paradigms, recent large-scale generative models show tremendous promise in synthesizing high-resolution images and text, as well as structured data such as videos and molecules. However, we argue that current large-scale generative AI models do not sufficiently address several fundamental issues that hinder their widespread adoption across domains. In this work, we aim to identify key unresolved challenges in modern generative AI paradigms that should be tackled to further enhance their capabilities, versatility, and reliability. By identifying these challenges, we aim to provide researchers with valuable insights for exploring fruitful research directions, thereby fostering the development of more robust and accessible generative AI solutions.
Expectation-Complete Graph Representations with Homomorphisms
Jun 09, 2023We investigate novel random graph embeddings that can be computed in expected polynomial time and that are able to distinguish all non-isomorphic graphs in expectation. Previous graph embeddings have limited expressiveness and either cannot distinguish all graphs or cannot be computed efficiently for every graph. To be able to approximate arbitrary functions on graphs, we are interested in efficient alternatives that become arbitrarily expressive with increasing resources. Our approach is based on Lov\'asz' characterisation of graph isomorphism through an infinite dimensional vector of homomorphism counts. Our empirical evaluation shows competitive results on several benchmark graph learning tasks.
Corresponding Projections for Orphan Screening
Nov 30, 2018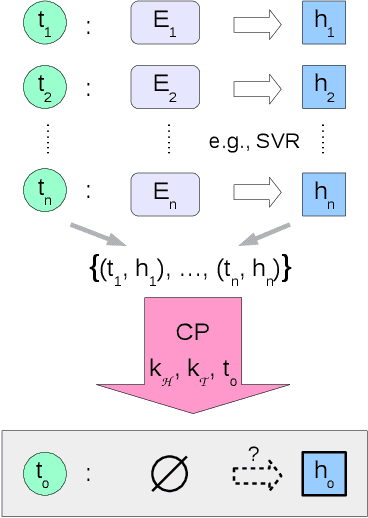

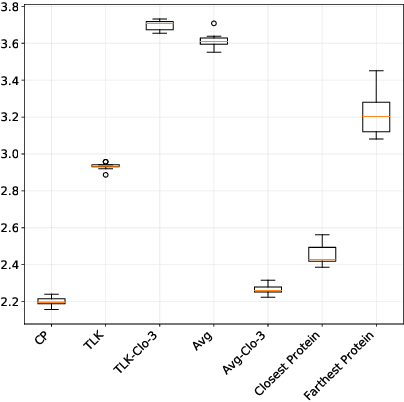
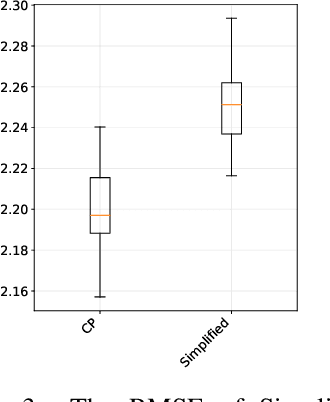
We propose a novel transfer learning approach for orphan screening called corresponding projections. In orphan screening the learning task is to predict the binding affinities of compounds to an orphan protein, i.e., one for which no training data is available. The identification of compounds with high affinity is a central concern in medicine since it can be used for drug discovery and design. Given a set of prediction models for proteins with labelled training data and a similarity between the proteins, corresponding projections constructs a model for the orphan protein from them such that the similarity between models resembles the one between proteins. Under the assumption that the similarity resemblance holds, we derive an efficient algorithm for kernel methods. We empirically show that the approach outperforms the state-of-the-art in orphan screening.
Effective Parallelisation for Machine Learning
Oct 08, 2018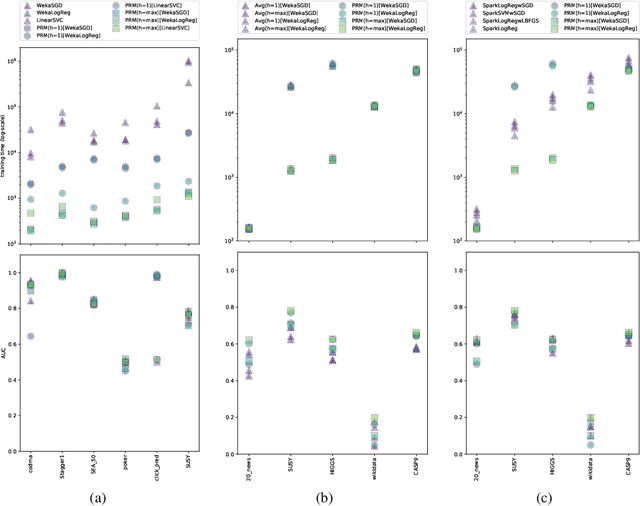
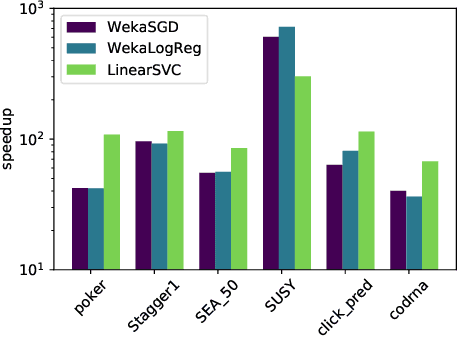
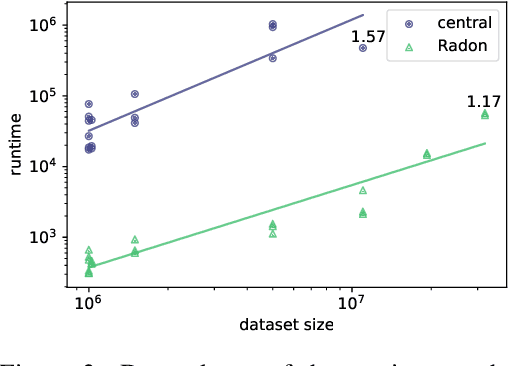
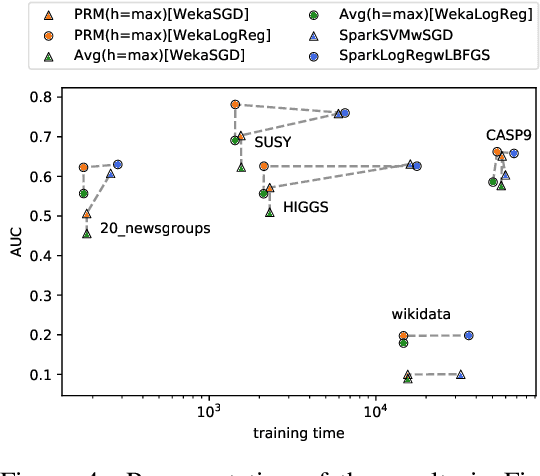
We present a novel parallelisation scheme that simplifies the adaptation of learning algorithms to growing amounts of data as well as growing needs for accurate and confident predictions in critical applications. In contrast to other parallelisation techniques, it can be applied to a broad class of learning algorithms without further mathematical derivations and without writing dedicated code, while at the same time maintaining theoretical performance guarantees. Moreover, our parallelisation scheme is able to reduce the runtime of many learning algorithms to polylogarithmic time on quasi-polynomially many processing units. This is a significant step towards a general answer to an open question on the efficient parallelisation of machine learning algorithms in the sense of Nick's Class (NC). The cost of this parallelisation is in the form of a larger sample complexity. Our empirical study confirms the potential of our parallelisation scheme with fixed numbers of processors and instances in realistic application scenarios.