 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundation Models for Natural Language Processing -- Pre-trained Language Models Integrating Media
Feb 16, 2023This open access book provides a comprehensive overview of the state of the art in research and applications of Foundation Models and is intended for readers familiar with basic Natural Language Processing (NLP) concepts. Over the recent years, a revolutionary new paradigm has been developed for training models for NLP. These models are first pre-trained on large collections of text documents to acquire general syntactic knowledge and semantic information. Then, they are fine-tuned for specific tasks, which they can often solve with superhuman accuracy. When the models are large enough, they can be instructed by prompts to solve new tasks without any fine-tuning. Moreover, they can be applied to a wide range of different media and problem domains, ranging from image and video processing to robot control learning. Because they provide a blueprint for solving many tasks in artificial intelligence, they have been called Foundation Models. After a brief introduction to basic NLP models the main pre-trained language models BERT, GPT and sequence-to-sequence transformer are described, as well as the concepts of self-attention and context-sensitive embedding. Then, different approaches to improving these models are discussed, such as expanding the pre-training criteria, increasing the length of input texts, or including extra knowledge. An overview of the best-performing models for about twenty application areas is then presented, e.g., question answering, translation, story generation, dialog systems, generating images from text, etc. For each application area, the strengths and weaknesses of current models are discussed, and an outlook on further developments is given. In addition, links are provided to freely available program code. A concluding chapter summarizes the economic opportunities, mitigation of risks, and potential developments of AI.
Supporting verification of news articles with automated search for semantically similar articles
Mar 29, 2021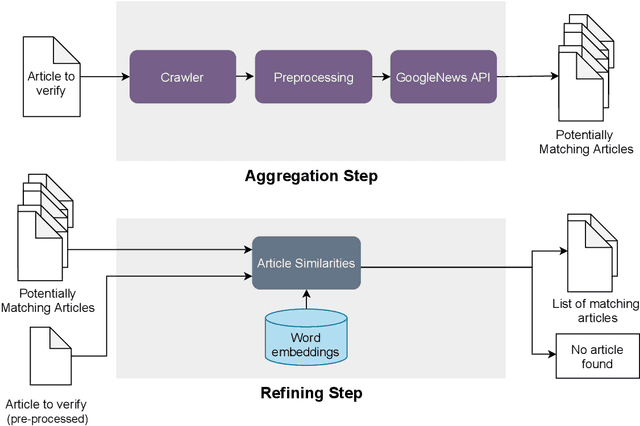

Fake information poses one of the major threats for society in the 21st century. Identifying misinformation has become a key challenge due to the amount of fake news that is published daily. Yet, no approach is established that addresses the dynamics and versatility of fake news editorials. Instead of classifying content, we propose an evidence retrieval approach to handle fake news. The learning task is formulated as an unsupervised machine learning problem. For validation purpose, we provide the user with a set of news articles from reliable news sources supporting the hypothesis of the news article in query and the final decision is left to the user. Technically we propose a two-step process: (i) Aggregation-step: With information extracted from the given text we query for similar content from reliable news sources. (ii) Refining-step: We narrow the supporting evidence down by measuring the semantic distance of the text with the collection from step (i). The distance is calculated based on Word2Vec and the Word Mover's Distance. In our experiments, only content that is below a certain distance threshold is considered as supporting evidence. We find that our approach is agnostic to concept drifts, i.e. the machine learning task is independent of the hypotheses in a text. This makes it highly adaptable in times where fake news is as diverse as classical news is. Our pipeline offers the possibility for further analysis in the future, such as investigating bias and differences in news reporting.
Systematic Comparison of the Influence of Different Data Preprocessing Methods on the Classification of Gait Using Machine Learning
Nov 11, 2019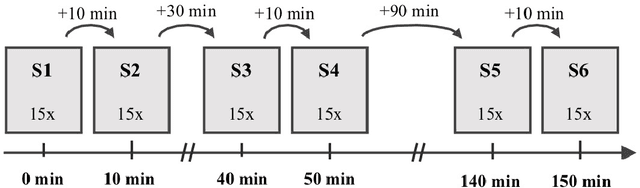
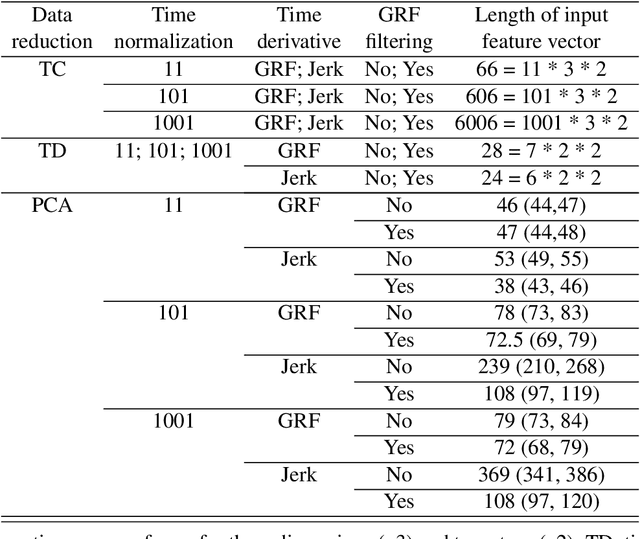
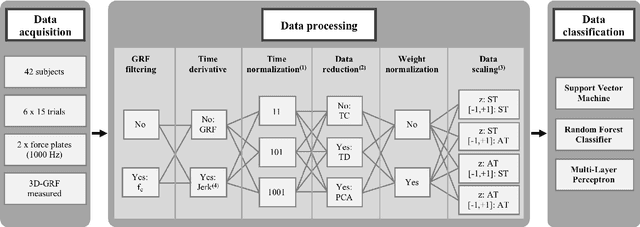
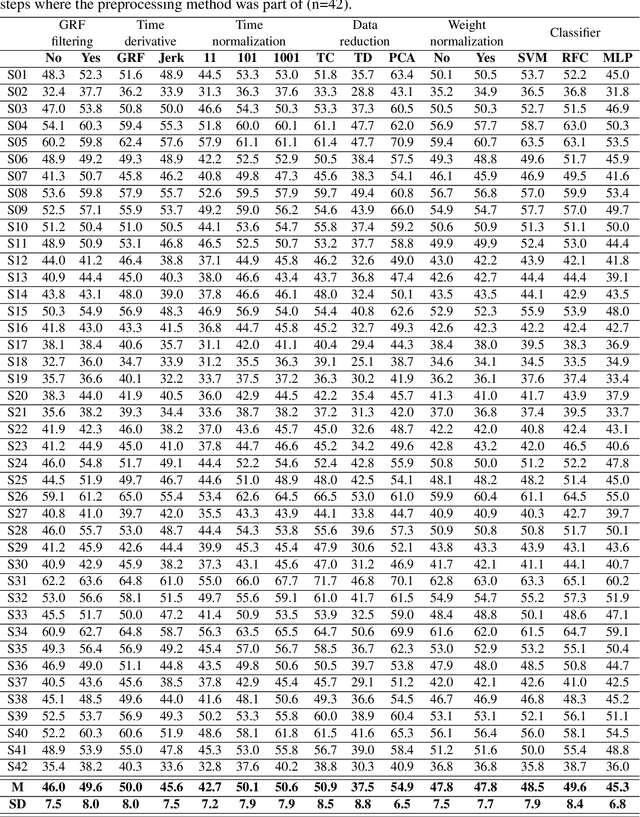
Human movements are characterized by highly non-linear and multi-dimensional interactions within the motor system. Recently, an increasing emphasis on machine-learning applications has led to a significant contribution to the field of gait analysis e.g. in increasing the classification accuracy. In order to ensure the generalizability of the machine-learning models, different data preprocessing steps are usually carried out to process the measured raw data before the classifications. In the past, various methods have been used for each of these preprocessing steps. However, there are hardly any standard procedures or rather systematic comparisons of these different methods and their impact on the classification accuracy. Therefore, the aim of this analysis is to compare different combinations of commonly applied data preprocessing steps and test their effects on the classification accuracy of gait patterns. A publicly available dataset on intra-individual changes of gait patterns was used for this analysis. Forty-two healthy subjects performed 6 sessions of 15 gait trials for one day. For each trial, two force plates recorded the 3D ground reaction forces (GRF). The data was preprocessed with the following steps: GRF filtering, time derivative, time normalization, data reduction, weight normalization and data scaling. Subsequently, combinations of all methods from each individual preprocessing step were analyzed and compared with respect to their prediction accuracy in a six-session classification using Support Vector Machines, Random Forest Classifiers and Multi-Layer Perceptrons. In conclusion, the present results provide first domain-specific recommendations for commonly applied data preprocessing methods and might help to build more comparable and more robust classification models based on machine learning that are suitable for a practical application.
Corresponding Projections for Orphan Screening
Nov 30, 2018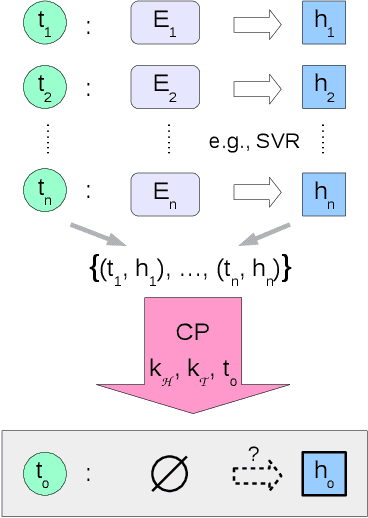

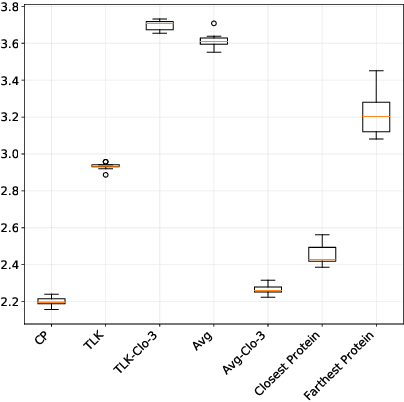
We propose a novel transfer learning approach for orphan screening called corresponding projections. In orphan screening the learning task is to predict the binding affinities of compounds to an orphan protein, i.e., one for which no training data is available. The identification of compounds with high affinity is a central concern in medicine since it can be used for drug discovery and design. Given a set of prediction models for proteins with labelled training data and a similarity between the proteins, corresponding projections constructs a model for the orphan protein from them such that the similarity between models resembles the one between proteins. Under the assumption that the similarity resemblance holds, we derive an efficient algorithm for kernel methods. We empirically show that the approach outperforms the state-of-the-art in orphan screening.
Making Efficient Use of a Domain Expert's Time in Relation Extraction
Jul 12, 2018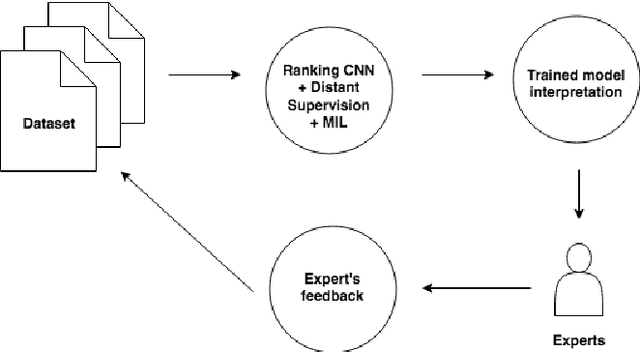
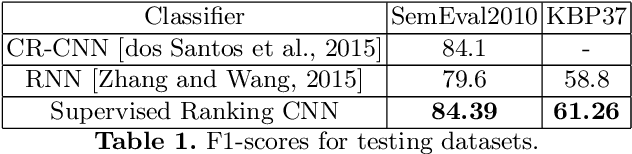
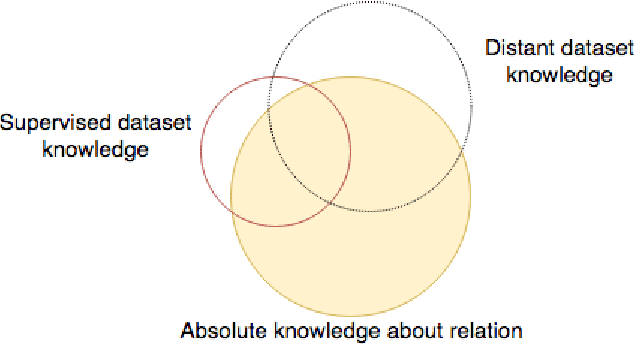
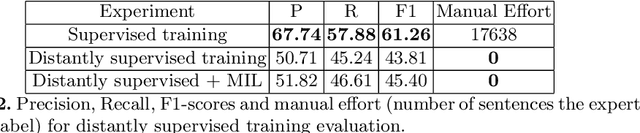
Scarcity of labeled data is one of the most frequent problems faced in machine learning. This is particularly true in relation extraction in text mining, where large corpora of texts exists in many application domains, while labeling of text data requires an expert to invest much time to read the documents. Overall, state-of-the art models, like the convolutional neural network used in this paper, achieve great results when trained on large enough amounts of labeled data. However, from a practical point of view the question arises whether this is the most efficient approach when one takes the manual effort of the expert into account. In this paper, we report on an alternative approach where we first construct a relation extraction model using distant supervision, and only later make use of a domain expert to refine the results. Distant supervision provides a mean of labeling data given known relations in a knowledge base, but it suffers from noisy labeling. We introduce an active learning based extension, that allows our neural network to incorporate expert feedback and report on first results on a complex data set.