 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupporting verification of news articles with automated search for semantically similar articles
Mar 29, 2021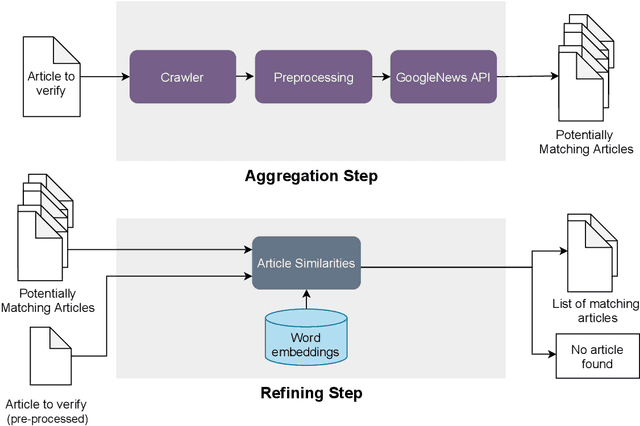

Fake information poses one of the major threats for society in the 21st century. Identifying misinformation has become a key challenge due to the amount of fake news that is published daily. Yet, no approach is established that addresses the dynamics and versatility of fake news editorials. Instead of classifying content, we propose an evidence retrieval approach to handle fake news. The learning task is formulated as an unsupervised machine learning problem. For validation purpose, we provide the user with a set of news articles from reliable news sources supporting the hypothesis of the news article in query and the final decision is left to the user. Technically we propose a two-step process: (i) Aggregation-step: With information extracted from the given text we query for similar content from reliable news sources. (ii) Refining-step: We narrow the supporting evidence down by measuring the semantic distance of the text with the collection from step (i). The distance is calculated based on Word2Vec and the Word Mover's Distance. In our experiments, only content that is below a certain distance threshold is considered as supporting evidence. We find that our approach is agnostic to concept drifts, i.e. the machine learning task is independent of the hypotheses in a text. This makes it highly adaptable in times where fake news is as diverse as classical news is. Our pipeline offers the possibility for further analysis in the future, such as investigating bias and differences in news reporting.