 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Sufficient is not Enough: Utilizing the Rashomon Effect for Complete Evidence Extraction
Nov 10, 2025Feature attribution methods typically provide minimal sufficient evidence justifying a model decision. However, in many applications this is inadequate. For compliance and cataloging, the full set of contributing features must be identified - complete evidence. We perform a case study on a medical dataset which contains human-annotated complete evidence. We show that individual models typically recover only subsets of complete evidence and that aggregating evidence from several models improves evidence recall from $\sim$0.60 (single best model) to $\sim$0.86 (ensemble). We analyze the recall-precision trade-off, the role of training with evidence, dynamic ensembles with certainty thresholds, and discuss implications.
GG-BBQ: German Gender Bias Benchmark for Question Answering
Jul 22, 2025Within the context of Natural Language Processing (NLP), fairness evaluation is often associated with the assessment of bias and reduction of associated harm. In this regard, the evaluation is usually carried out by using a benchmark dataset, for a task such as Question Answering, created for the measurement of bias in the model's predictions along various dimensions, including gender identity. In our work, we evaluate gender bias in German Large Language Models (LLMs) using the Bias Benchmark for Question Answering by Parrish et al. (2022) as a reference. Specifically, the templates in the gender identity subset of this English dataset were machine translated into German. The errors in the machine translated templates were then manually reviewed and corrected with the help of a language expert. We find that manual revision of the translation is crucial when creating datasets for gender bias evaluation because of the limitations of machine translation from English to a language such as German with grammatical gender. Our final dataset is comprised of two subsets: Subset-I, which consists of group terms related to gender identity, and Subset-II, where group terms are replaced with proper names. We evaluate several LLMs used for German NLP on this newly created dataset and report the accuracy and bias scores. The results show that all models exhibit bias, both along and against existing social stereotypes.
The Anatomy of Evidence: An Investigation Into Explainable ICD Coding
Jul 02, 2025Automatic medical coding has the potential to ease documentation and billing processes. For this task, transparency plays an important role for medical coders and regulatory bodies, which can be achieved using explainability methods. However, the evaluation of these approaches has been mostly limited to short text and binary settings due to a scarcity of annotated data. Recent efforts by Cheng et al. (2023) have introduced the MDACE dataset, which provides a valuable resource containing code evidence in clinical records. In this work, we conduct an in-depth analysis of the MDACE dataset and perform plausibility evaluation of current explainable medical coding systems from an applied perspective. With this, we contribute to a deeper understanding of automatic medical coding and evidence extraction. Our findings reveal that ground truth evidence aligns with code descriptions to a certain degree. An investigation into state-of-the-art approaches shows a high overlap with ground truth evidence. We propose match measures and highlight success and failure cases. Based on our findings, we provide recommendations for developing and evaluating explainable medical coding systems.
An Empirical Evaluation of the Rashomon Effect in Explainable Machine Learning
Jun 29, 2023The Rashomon Effect describes the following phenomenon: for a given dataset there may exist many models with equally good performance but with different solution strategies. The Rashomon Effect has implications for Explainable Machine Learning, especially for the comparability of explanations. We provide a unified view on three different comparison scenarios and conduct a quantitative evaluation across different datasets, models, attribution methods, and metrics. We find that hyperparameter-tuning plays a role and that metric selection matters. Our results provide empirical support for previously anecdotal evidence and exhibit challenges for both scientists and practitioners.
Explainable Machine Learning with Prior Knowledge: An Overview
May 21, 2021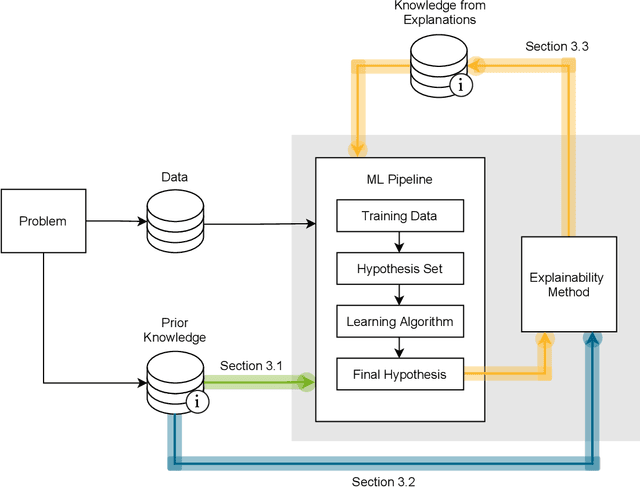

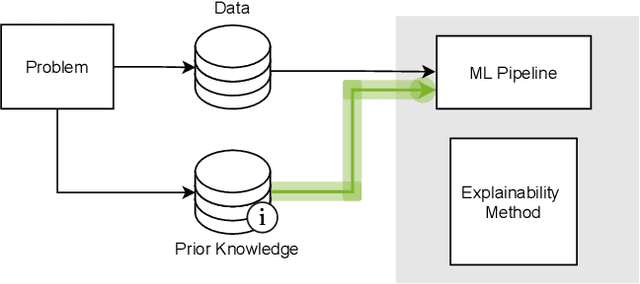
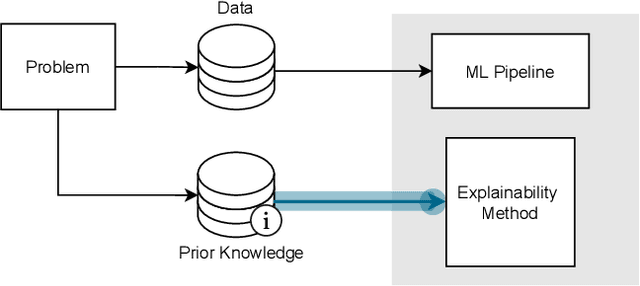
This survey presents an overview of integrating prior knowledge into machine learning systems in order to improve explainability. The complexity of machine learning models has elicited research to make them more explainable. However, most explainability methods cannot provide insight beyond the given data, requiring additional information about the context. We propose to harness prior knowledge to improve upon the explanation capabilities of machine learning models. In this paper, we present a categorization of current research into three main categories which either integrate knowledge into the machine learning pipeline, into the explainability method or derive knowledge from explanations. To classify the papers, we build upon the existing taxonomy of informed machine learning and extend it from the perspective of explainability. We conclude with open challenges and research directions.
Supporting verification of news articles with automated search for semantically similar articles
Mar 29, 2021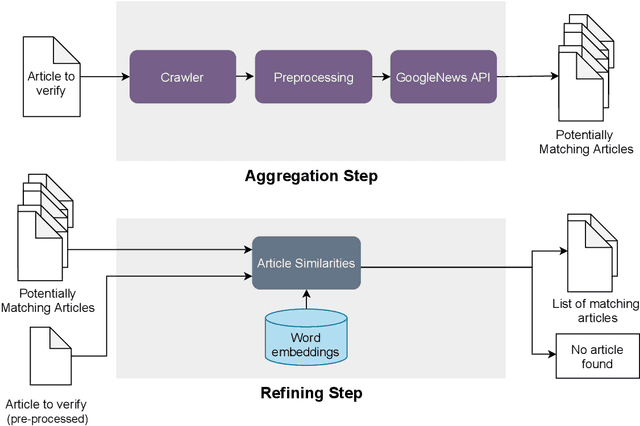
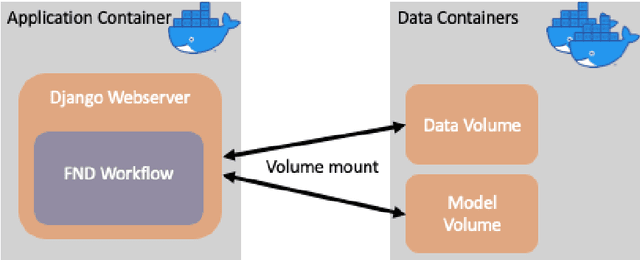

Fake information poses one of the major threats for society in the 21st century. Identifying misinformation has become a key challenge due to the amount of fake news that is published daily. Yet, no approach is established that addresses the dynamics and versatility of fake news editorials. Instead of classifying content, we propose an evidence retrieval approach to handle fake news. The learning task is formulated as an unsupervised machine learning problem. For validation purpose, we provide the user with a set of news articles from reliable news sources supporting the hypothesis of the news article in query and the final decision is left to the user. Technically we propose a two-step process: (i) Aggregation-step: With information extracted from the given text we query for similar content from reliable news sources. (ii) Refining-step: We narrow the supporting evidence down by measuring the semantic distance of the text with the collection from step (i). The distance is calculated based on Word2Vec and the Word Mover's Distance. In our experiments, only content that is below a certain distance threshold is considered as supporting evidence. We find that our approach is agnostic to concept drifts, i.e. the machine learning task is independent of the hypotheses in a text. This makes it highly adaptable in times where fake news is as diverse as classical news is. Our pipeline offers the possibility for further analysis in the future, such as investigating bias and differences in news reporting.