 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextual Data Bias Detection and Mitigation -- An Extensible Pipeline with Experimental Evaluation
Dec 12, 2025Textual data used to train large language models (LLMs) exhibits multifaceted bias manifestations encompassing harmful language and skewed demographic distributions. Regulations such as the European AI Act require identifying and mitigating biases against protected groups in data, with the ultimate goal of preventing unfair model outputs. However, practical guidance and operationalization are lacking. We propose a comprehensive data bias detection and mitigation pipeline comprising four components that address two data bias types, namely representation bias and (explicit) stereotypes for a configurable sensitive attribute. First, we leverage LLM-generated word lists created based on quality criteria to detect relevant group labels. Second, representation bias is quantified using the Demographic Representation Score. Third, we detect and mitigate stereotypes using sociolinguistically informed filtering. Finally, we compensate representation bias through Grammar- and Context-Aware Counterfactual Data Augmentation. We conduct a two-fold evaluation using the examples of gender, religion and age. First, the effectiveness of each individual component on data debiasing is evaluated through human validation and baseline comparison. The findings demonstrate that we successfully reduce representation bias and (explicit) stereotypes in a text dataset. Second, the effect of data debiasing on model bias reduction is evaluated by bias benchmarking of several models (0.6B-8B parameters), fine-tuned on the debiased text dataset. This evaluation reveals that LLMs fine-tuned on debiased data do not consistently show improved performance on bias benchmarks, exposing critical gaps in current evaluation methodologies and highlighting the need for targeted data manipulation to address manifested model bias.
The Anatomy of Evidence: An Investigation Into Explainable ICD Coding
Jul 02, 2025Automatic medical coding has the potential to ease documentation and billing processes. For this task, transparency plays an important role for medical coders and regulatory bodies, which can be achieved using explainability methods. However, the evaluation of these approaches has been mostly limited to short text and binary settings due to a scarcity of annotated data. Recent efforts by Cheng et al. (2023) have introduced the MDACE dataset, which provides a valuable resource containing code evidence in clinical records. In this work, we conduct an in-depth analysis of the MDACE dataset and perform plausibility evaluation of current explainable medical coding systems from an applied perspective. With this, we contribute to a deeper understanding of automatic medical coding and evidence extraction. Our findings reveal that ground truth evidence aligns with code descriptions to a certain degree. An investigation into state-of-the-art approaches shows a high overlap with ground truth evidence. We propose match measures and highlight success and failure cases. Based on our findings, we provide recommendations for developing and evaluating explainable medical coding systems.
Detecting Systematic Weaknesses in Vision Models along Predefined Human-Understandable Dimensions
Feb 17, 2025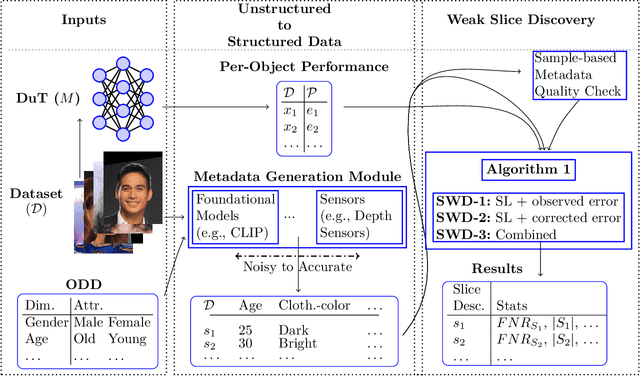
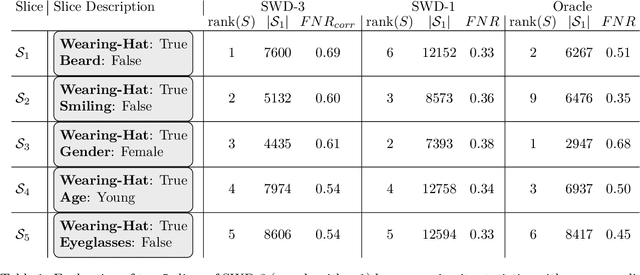
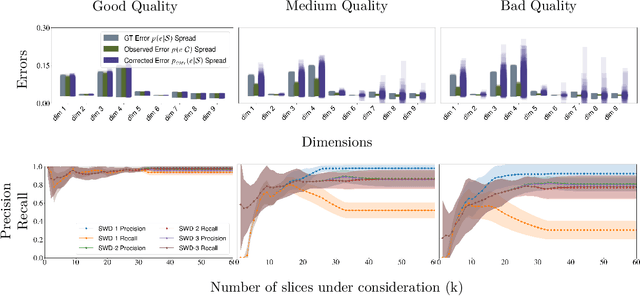
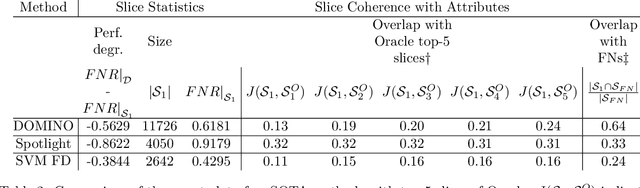
Studying systematic weaknesses of DNNs has gained prominence in the last few years with the rising focus on building safe AI systems. Slice discovery methods (SDMs) are prominent algorithmic approaches for finding such systematic weaknesses. They identify top-k semantically coherent slices/subsets of data where a DNN-under-test has low performance. For being directly useful, e.g., as evidences in a safety argumentation, slices should be aligned with human-understandable (safety-relevant) dimensions, which, for example, are defined by safety and domain experts as parts of the operational design domain (ODD). While straightforward for structured data, the lack of semantic metadata makes these investigations challenging for unstructured data. Therefore, we propose a complete workflow which combines contemporary foundation models with algorithms for combinatorial search that consider structured data and DNN errors for finding systematic weaknesses in images. In contrast to existing approaches, ours identifies weak slices that are in line with predefined human-understandable dimensions. As the workflow includes foundation models, its intermediate and final results may not always be exact. Therefore, we build into our workflow an approach to address the impact of noisy metadata. We evaluate our approach w.r.t. its quality on four popular computer vision datasets, including autonomous driving datasets like Cityscapes, BDD100k, and RailSem19, while using multiple state-of-the-art models as DNNs-under-test.
Assessing Systematic Weaknesses of DNNs using Counterfactuals
Aug 03, 2023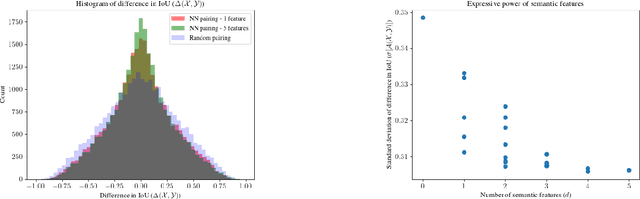
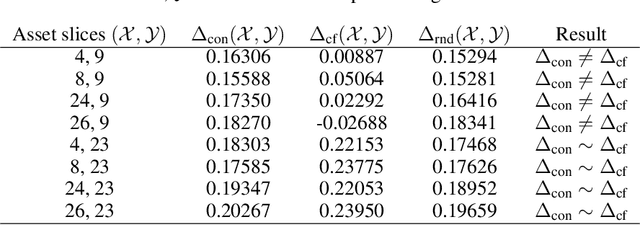
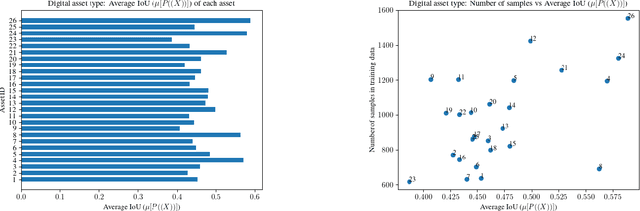

With the advancement of DNNs into safety-critical applications, testing approaches for such models have gained more attention. A current direction is the search for and identification of systematic weaknesses that put safety assumptions based on average performance values at risk. Such weaknesses can take on the form of (semantically coherent) subsets or areas in the input space where a DNN performs systematically worse than its expected average. However, it is non-trivial to attribute the reason for such observed low performances to the specific semantic features that describe the subset. For instance, inhomogeneities within the data w.r.t. other (non-considered) attributes might distort results. However, taking into account all (available) attributes and their interaction is often computationally highly expensive. Inspired by counterfactual explanations, we propose an effective and computationally cheap algorithm to validate the semantic attribution of existing subsets, i.e., to check whether the identified attribute is likely to have caused the degraded performance. We demonstrate this approach on an example from the autonomous driving domain using highly annotated simulated data, where we show for a semantic segmentation model that (i) performance differences among the different pedestrian assets exist, but (ii) only in some cases is the asset type itself the reason for this reduction in the performance.
Inspect, Understand, Overcome: A Survey of Practical Methods for AI Safety
Apr 29, 2021The use of deep neural networks (DNNs) in safety-critical applications like mobile health and autonomous driving is challenging due to numerous model-inherent shortcomings. These shortcomings are diverse and range from a lack of generalization over insufficient interpretability to problems with malicious inputs. Cyber-physical systems employing DNNs are therefore likely to suffer from safety concerns. In recent years, a zoo of state-of-the-art techniques aiming to address these safety concerns has emerged. This work provides a structured and broad overview of them. We first identify categories of insufficiencies to then describe research activities aiming at their detection, quantification, or mitigation. Our paper addresses both machine learning experts and safety engineers: The former ones might profit from the broad range of machine learning topics covered and discussions on limitations of recent methods. The latter ones might gain insights into the specifics of modern ML methods. We moreover hope that our contribution fuels discussions on desiderata for ML systems and strategies on how to propel existing approaches accordingly.