 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePruning Extensions and Efficiency Trade-Offs for Sustainable Time Series Classification
Apr 09, 2026Time series classification (TSC) enables important use cases, however lacks a unified understanding of performance trade-offs across models, datasets, and hardware. While resource awareness has grown in the field, TSC methods have not yet been rigorously evaluated for energy efficiency. This paper introduces a holistic evaluation framework that explicitly explores the balance of predictive performance and resource consumption in TSC. To boost efficiency, we apply a theoretically bounded pruning strategy to leading hybrid classifiers - Hydra and Quant - and present Hydrant, a novel, prunable combination of both. With over 4000 experimental configurations across 20 MONSTER datasets, 13 methods, and three compute setups, we systematically analyze how model design, hyperparameters, and hardware choices affect practical TSC performance. Our results showcase that pruning can significantly reduce energy consumption by up to 80% while maintaining competitive predictive quality, usually costing the model less than 5% of accuracy. The proposed methodology, experimental results, and accompanying software advance TSC toward sustainable and reproducible practice.
Ground-Truthing AI Energy Consumption: Validating CodeCarbon Against External Measurements
Sep 26, 2025Although machine learning (ML) and artificial intelligence (AI) present fascinating opportunities for innovation, their rapid development is also significantly impacting our environment. In response to growing resource-awareness in the field, quantification tools such as the ML Emissions Calculator and CodeCarbon were developed to estimate the energy consumption and carbon emissions of running AI models. They are easy to incorporate into AI projects, however also make pragmatic assumptions and neglect important factors, raising the question of estimation accuracy. This study systematically evaluates the reliability of static and dynamic energy estimation approaches through comparisons with ground-truth measurements across hundreds of AI experiments. Based on the proposed validation framework, investigative insights into AI energy demand and estimation inaccuracies are provided. While generally following the patterns of AI energy consumption, the established estimation approaches are shown to consistently make errors of up to 40%. By providing empirical evidence on energy estimation quality and errors, this study establishes transparency and validates widely used tools for sustainable AI development. It moreover formulates guidelines for improving the state-of-the-art and offers code for extending the validation to other domains and tools, thus making important contributions to resource-aware ML and AI sustainability research.
Bridging the Communication Gap: Evaluating AI Labeling Practices for Trustworthy AI Development
Jan 21, 2025As artificial intelligence (AI) becomes integral to economy and society, communication gaps between developers, users, and stakeholders hinder trust and informed decision-making. High-level AI labels, inspired by frameworks like EU energy labels, have been proposed to make the properties of AI models more transparent. Without requiring deep technical expertise, they can inform on the trade-off between predictive performance and resource efficiency. However, the practical benefits and limitations of AI labeling remain underexplored. This study evaluates AI labeling through qualitative interviews along four key research questions. Based on thematic analysis and inductive coding, we found a broad range of practitioners to be interested in AI labeling (RQ1). They see benefits for alleviating communication gaps and aiding non-expert decision-makers, however limitations, misunderstandings, and suggestions for improvement were also discussed (RQ2). Compared to other reporting formats, interviewees positively evaluated the reduced complexity of labels, increasing overall comprehensibility (RQ3). Trust was influenced most by usability and the credibility of the responsible labeling authority, with mixed preferences for self-certification versus third-party certification (RQ4). Our Insights highlight that AI labels pose a trade-off between simplicity and complexity, which could be resolved by developing customizable and interactive labeling frameworks to address diverse user needs. Transparent labeling of resource efficiency also nudged interviewee priorities towards paying more attention to sustainability aspects during AI development. This study validates AI labels as a valuable tool for enhancing trust and communication in AI, offering actionable guidelines for their refinement and standardization.
AutoXPCR: Automated Multi-Objective Model Selection for Time Series Forecasting
Dec 20, 2023Automated machine learning (AutoML) streamlines the creation of ML models. While most methods select the "best" model based on predictive quality, it's crucial to acknowledge other aspects, such as interpretability and resource consumption. This holds particular importance in the context of deep neural networks (DNNs), as these models are often perceived as computationally intensive black boxes. In the challenging domain of time series forecasting, DNNs achieve stunning results, but specialized approaches for automatically selecting models are scarce. In this paper, we propose AutoXPCR - a novel method for automated and explainable multi-objective model selection. Our approach leverages meta-learning to estimate any model's performance along PCR criteria, which encompass (P)redictive error, (C)omplexity, and (R)esource demand. Explainability is addressed on multiple levels, as our interactive framework can prioritize less complex models and provide by-product explanations of recommendations. We demonstrate practical feasibility by deploying AutoXPCR on over 1000 configurations across 114 data sets from various domains. Our method clearly outperforms other model selection approaches - on average, it only requires 20% of computation costs for recommending models with 90% of the best-possible quality.
Energy Efficiency Considerations for Popular AI Benchmarks
Apr 17, 2023Advances in artificial intelligence need to become more resource-aware and sustainable. This requires clear assessment and reporting of energy efficiency trade-offs, like sacrificing fast running time for higher predictive performance. While first methods for investigating efficiency have been proposed, we still lack comprehensive results for popular methods and data sets. In this work, we attempt to fill this information gap by providing empiric insights for popular AI benchmarks, with a total of 100 experiments. Our findings are evidence of how different data sets all have their own efficiency landscape, and show that methods can be more or less likely to act efficiently.
The Care Label Concept: A Certification Suite for Trustworthy and Resource-Aware Machine Learning
Jun 01, 2021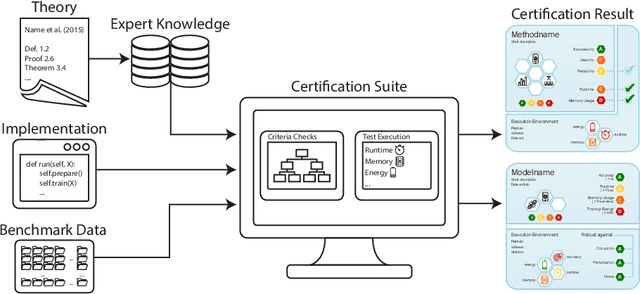
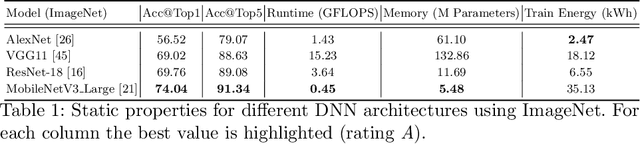
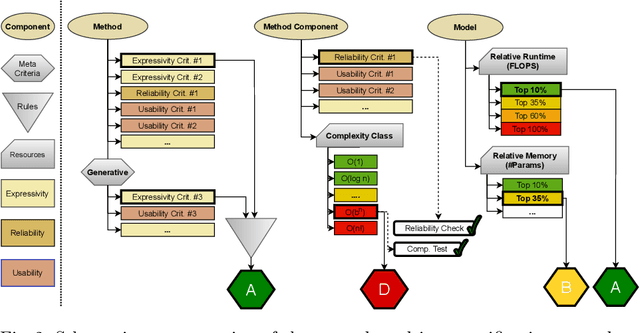
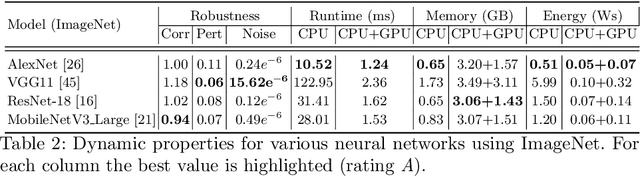
Machine learning applications have become ubiquitous. This has led to an increased effort of making machine learning trustworthy. Explainable and fair AI have already matured. They address knowledgeable users and application engineers. For those who do not want to invest time into understanding the method or the learned model, we offer care labels: easy to understand at a glance, allowing for method or model comparisons, and, at the same time, scientifically well-based. On one hand, this transforms descriptions as given by, e.g., Fact Sheets or Model Cards, into a form that is well-suited for end-users. On the other hand, care labels are the result of a certification suite that tests whether stated guarantees hold. In this paper, we present two experiments with our certification suite. One shows the care labels for configurations of Markov random fields (MRFs). Based on the underlying theory of MRFs, each choice leads to its specific rating of static properties like, e.g., expressivity and reliability. In addition, the implementation is tested and resource consumption is measured yielding dynamic properties. This two-level procedure is followed by another experiment certifying deep neural network (DNN) models. There, we draw the static properties from the literature on a particular model and data set. At the second level, experiments are generated that deliver measurements of robustness against certain attacks. We illustrate this by ResNet-18 and MobileNetV3 applied to ImageNet.
Yes We Care! -- Certification for Machine Learning Methods through the Care Label Framework
May 21, 2021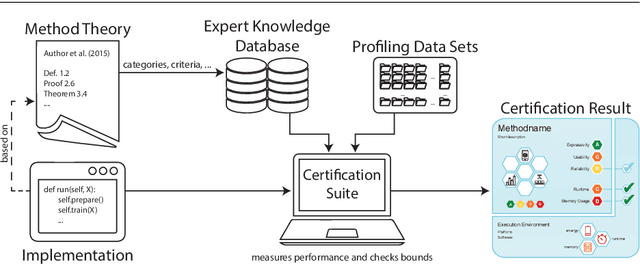
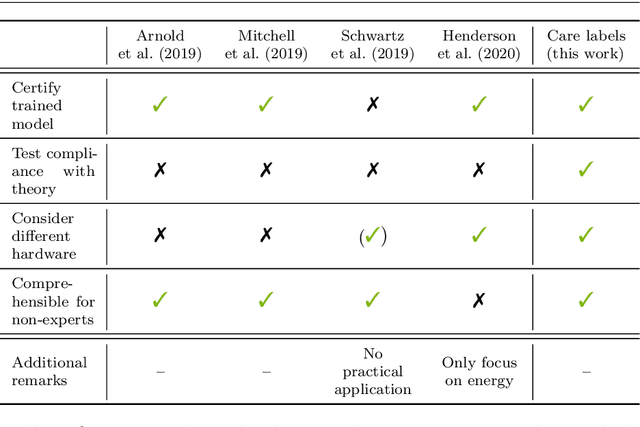
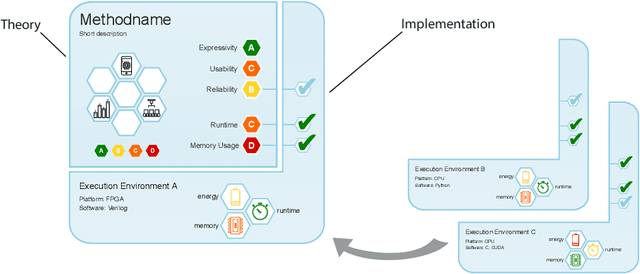
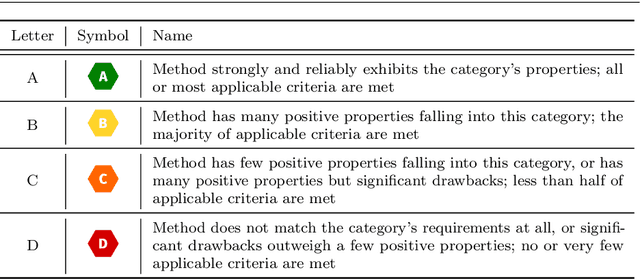
Machine learning applications have become ubiquitous. Their applications from machine embedded control in production over process optimization in diverse areas (e.g., traffic, finance, sciences) to direct user interactions like advertising and recommendations. This has led to an increased effort of making machine learning trustworthy. Explainable and fair AI have already matured. They address knowledgeable users and application engineers. However, there are users that want to deploy a learned model in a similar way as their washing machine. These stakeholders do not want to spend time understanding the model. Instead, they want to rely on guaranteed properties. What are the relevant properties? How can they be expressed to stakeholders without presupposing machine learning knowledge? How can they be guaranteed for a certain implementation of a model? These questions move far beyond the current state-of-the-art and we want to address them here. We propose a unified framework that certifies learning methods via care labels. They are easy to understand and draw inspiration from well-known certificates like textile labels or property cards of electronic devices. Our framework considers both, the machine learning theory and a given implementation. We test the implementation's compliance with theoretical properties and bounds. In this paper, we illustrate care labels by a prototype implementation of a certification suite for a selection of probabilistic graphical models.
Explainable Machine Learning with Prior Knowledge: An Overview
May 21, 2021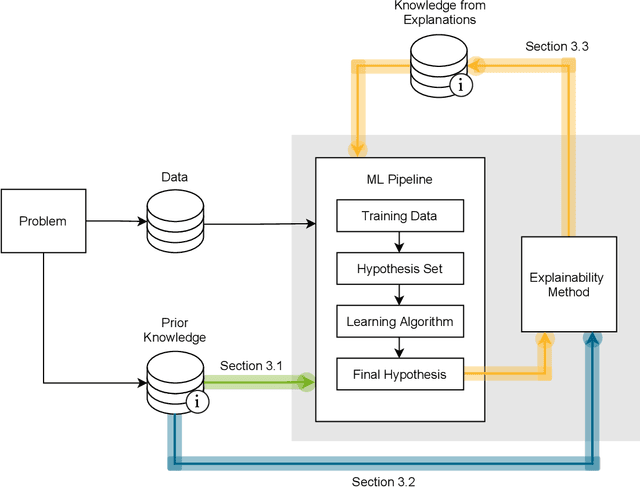

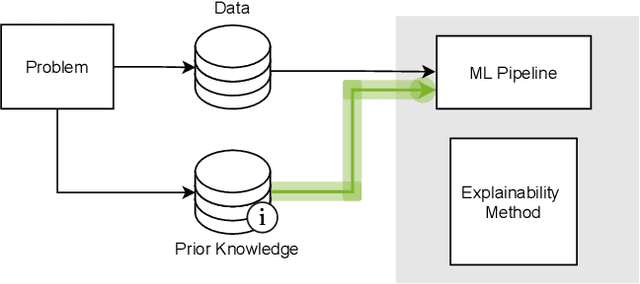
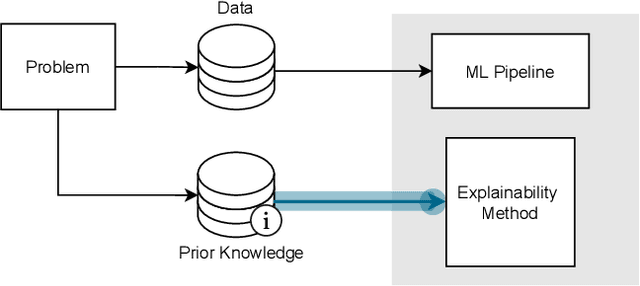
This survey presents an overview of integrating prior knowledge into machine learning systems in order to improve explainability. The complexity of machine learning models has elicited research to make them more explainable. However, most explainability methods cannot provide insight beyond the given data, requiring additional information about the context. We propose to harness prior knowledge to improve upon the explanation capabilities of machine learning models. In this paper, we present a categorization of current research into three main categories which either integrate knowledge into the machine learning pipeline, into the explainability method or derive knowledge from explanations. To classify the papers, we build upon the existing taxonomy of informed machine learning and extend it from the perspective of explainability. We conclude with open challenges and research directions.