 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Nascent Taxonomy of Machine Learning in Intelligent Robotic Process Automation
Sep 19, 2025Robotic process automation (RPA) is a lightweight approach to automating business processes using software robots that emulate user actions at the graphical user interface level. While RPA has gained popularity for its cost-effective and timely automation of rule-based, well-structured tasks, its symbolic nature has inherent limitations when approaching more complex tasks currently performed by human agents. Machine learning concepts enabling intelligent RPA provide an opportunity to broaden the range of automatable tasks. In this paper, we conduct a literature review to explore the connections between RPA and machine learning and organize the joint concept intelligent RPA into a taxonomy. Our taxonomy comprises the two meta-characteristics RPA-ML integration and RPA-ML interaction. Together, they comprise eight dimensions: architecture and ecosystem, capabilities, data basis, intelligence level, and technical depth of integration as well as deployment environment, lifecycle phase, and user-robot relation.
IXAII: An Interactive Explainable Artificial Intelligence Interface for Decision Support Systems
Jun 26, 2025Although several post-hoc methods for explainable AI have been developed, most are static and neglect the user perspective, limiting their effectiveness for the target audience. In response, we developed the interactive explainable intelligent system called IXAII that offers explanations from four explainable AI methods: LIME, SHAP, Anchors, and DiCE. Our prototype provides tailored views for five user groups and gives users agency over the explanations' content and their format. We evaluated IXAII through interviews with experts and lay users. Our results indicate that IXAII, which provides different explanations with multiple visualization options, is perceived as helpful to increase transparency. By bridging the gaps between explainable AI methods, interactivity, and practical implementation, we provide a novel perspective on AI explanation practices and human-AI interaction.
Beware of "Explanations" of AI
Apr 09, 2025Understanding the decisions made and actions taken by increasingly complex AI system remains a key challenge. This has led to an expanding field of research in explainable artificial intelligence (XAI), highlighting the potential of explanations to enhance trust, support adoption, and meet regulatory standards. However, the question of what constitutes a "good" explanation is dependent on the goals, stakeholders, and context. At a high level, psychological insights such as the concept of mental model alignment can offer guidance, but success in practice is challenging due to social and technical factors. As a result of this ill-defined nature of the problem, explanations can be of poor quality (e.g. unfaithful, irrelevant, or incoherent), potentially leading to substantial risks. Instead of fostering trust and safety, poorly designed explanations can actually cause harm, including wrong decisions, privacy violations, manipulation, and even reduced AI adoption. Therefore, we caution stakeholders to beware of explanations of AI: while they can be vital, they are not automatically a remedy for transparency or responsible AI adoption, and their misuse or limitations can exacerbate harm. Attention to these caveats can help guide future research to improve the quality and impact of AI explanations.
Bridging the Communication Gap: Evaluating AI Labeling Practices for Trustworthy AI Development
Jan 21, 2025As artificial intelligence (AI) becomes integral to economy and society, communication gaps between developers, users, and stakeholders hinder trust and informed decision-making. High-level AI labels, inspired by frameworks like EU energy labels, have been proposed to make the properties of AI models more transparent. Without requiring deep technical expertise, they can inform on the trade-off between predictive performance and resource efficiency. However, the practical benefits and limitations of AI labeling remain underexplored. This study evaluates AI labeling through qualitative interviews along four key research questions. Based on thematic analysis and inductive coding, we found a broad range of practitioners to be interested in AI labeling (RQ1). They see benefits for alleviating communication gaps and aiding non-expert decision-makers, however limitations, misunderstandings, and suggestions for improvement were also discussed (RQ2). Compared to other reporting formats, interviewees positively evaluated the reduced complexity of labels, increasing overall comprehensibility (RQ3). Trust was influenced most by usability and the credibility of the responsible labeling authority, with mixed preferences for self-certification versus third-party certification (RQ4). Our Insights highlight that AI labels pose a trade-off between simplicity and complexity, which could be resolved by developing customizable and interactive labeling frameworks to address diverse user needs. Transparent labeling of resource efficiency also nudged interviewee priorities towards paying more attention to sustainability aspects during AI development. This study validates AI labels as a valuable tool for enhancing trust and communication in AI, offering actionable guidelines for their refinement and standardization.
Generative AI
Sep 13, 2023The term "generative AI" refers to computational techniques that are capable of generating seemingly new, meaningful content such as text, images, or audio from training data. The widespread diffusion of this technology with examples such as Dall-E 2, GPT-4, and Copilot is currently revolutionizing the way we work and communicate with each other. In this article, we provide a conceptualization of generative AI as an entity in socio-technical systems and provide examples of models, systems, and applications. Based on that, we introduce limitations of current generative AI and provide an agenda for Business & Information Systems Engineering (BISE) research. Different from previous works, we focus on generative AI in the context of information systems, and, to this end, we discuss several opportunities and challenges that are unique to the BISE community and make suggestions for impactful directions for BISE research.
A Survey of Text Representation Methods and Their Genealogy
Nov 26, 2022In recent years, with the advent of highly scalable artificial-neural-network-based text representation methods the field of natural language processing has seen unprecedented growth and sophistication. It has become possible to distill complex linguistic information of text into multidimensional dense numeric vectors with the use of the distributional hypothesis. As a consequence, text representation methods have been evolving at such a quick pace that the research community is struggling to retain knowledge of the methods and their interrelations. We contribute threefold to this lack of compilation, composition, and systematization by providing a survey of current approaches, by arranging them in a genealogy, and by conceptualizing a taxonomy of text representation methods to examine and explain the state-of-the-art. Our research is a valuable guide and reference for artificial intelligence researchers and practitioners interested in natural language processing applications such as recommender systems, chatbots, and sentiment analysis.
* Published online in IEEE Access
Stop ordering machine learning algorithms by their explainability! A user-centered investigation of performance and explainability
Jun 20, 2022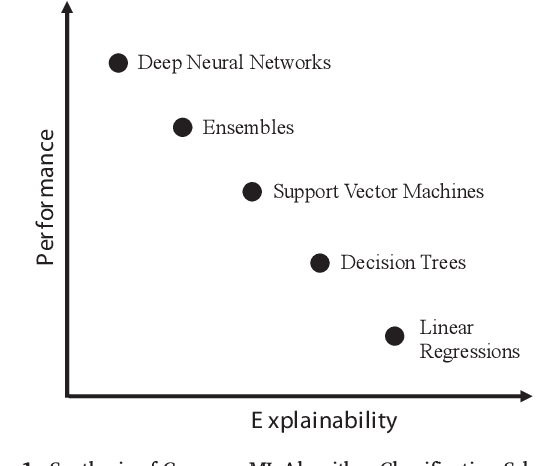
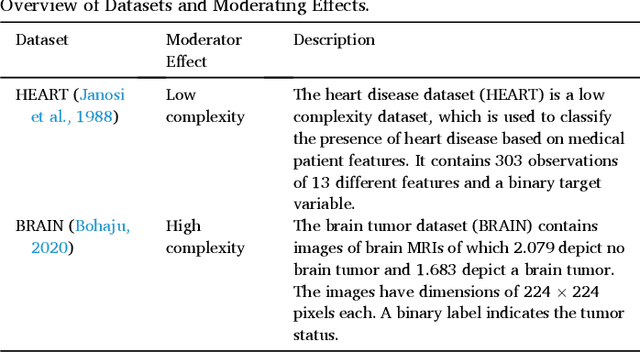
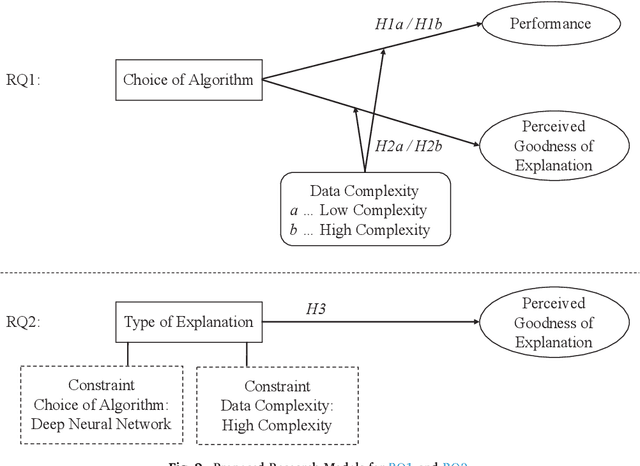

Machine learning algorithms enable advanced decision making in contemporary intelligent systems. Research indicates that there is a tradeoff between their model performance and explainability. Machine learning models with higher performance are often based on more complex algorithms and therefore lack explainability and vice versa. However, there is little to no empirical evidence of this tradeoff from an end user perspective. We aim to provide empirical evidence by conducting two user experiments. Using two distinct datasets, we first measure the tradeoff for five common classes of machine learning algorithms. Second, we address the problem of end user perceptions of explainable artificial intelligence augmentations aimed at increasing the understanding of the decision logic of high-performing complex models. Our results diverge from the widespread assumption of a tradeoff curve and indicate that the tradeoff between model performance and explainability is much less gradual in the end user's perception. This is a stark contrast to assumed inherent model interpretability. Further, we found the tradeoff to be situational for example due to data complexity. Results of our second experiment show that while explainable artificial intelligence augmentations can be used to increase explainability, the type of explanation plays an essential role in end user perception.
A survey of image labelling for computer vision applications
Apr 18, 2021
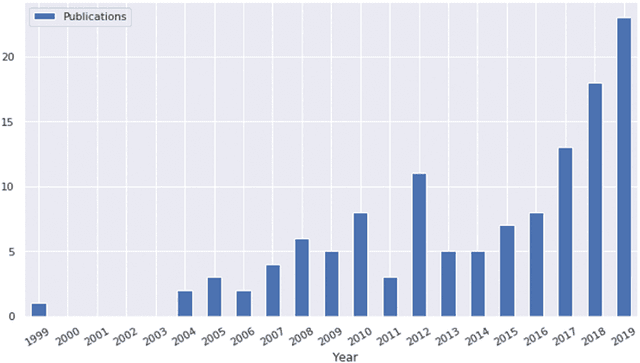
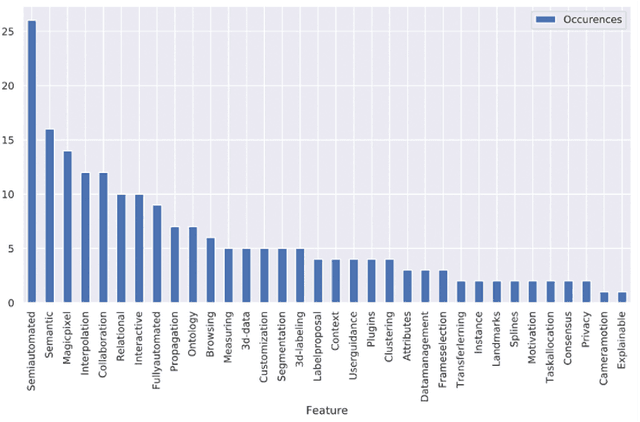

Supervised machine learning methods for image analysis require large amounts of labelled training data to solve computer vision problems. The recent rise of deep learning algorithms for recognising image content has led to the emergence of many ad-hoc labelling tools. With this survey, we capture and systematise the commonalities as well as the distinctions between existing image labelling software. We perform a structured literature review to compile the underlying concepts and features of image labelling software such as annotation expressiveness and degree of automation. We structure the manual labelling task by its organisation of work, user interface design options, and user support techniques to derive a systematisation schema for this survey. Applying it to available software and the body of literature, enabled us to uncover several application archetypes and key domains such as image retrieval or instance identification in healthcare or television.
Machine learning and deep learning
Apr 14, 2021

Today, intelligent systems that offer artificial intelligence capabilities often rely on machine learning. Machine learning describes the capacity of systems to learn from problem-specific training data to automate the process of analytical model building and solve associated tasks. Deep learning is a machine learning concept based on artificial neural networks. For many applications, deep learning models outperform shallow machine learning models and traditional data analysis approaches. In this article, we summarize the fundamentals of machine learning and deep learning to generate a broader understanding of the methodical underpinning of current intelligent systems. In particular, we provide a conceptual distinction between relevant terms and concepts, explain the process of automated analytical model building through machine learning and deep learning, and discuss the challenges that arise when implementing such intelligent systems in the field of electronic markets and networked business. These naturally go beyond technological aspects and highlight issues in human-machine interaction and artificial intelligence servitization.