 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTargeted T2-FLAIR Dropout Training Improves Robustness of nnU-Net Glioblastoma Segmentation to Missing T2-FLAIR
Feb 23, 2026Purpose: To determine whether targeted T2 fluid-attenuated inversion recovery (T2-FLAIR) dropout training improves glioblastoma MRI tumor segmentation robustness to missing T2-FLAIR without degrading performance when T2-FLAIR is available. Materials and Methods: This retrospective multi-dataset study developed nnU-Net models on BraTS 2021 (n=848) and externally tested them on UPenn-GBM glioblastoma MRI (n=403; 2006-2018; age 18-89 years; 60% male). Models were trained with no dropout or targeted T2-FLAIR dropout (probability rate r=0.35 or 0.50) by replacing only the T2-FLAIR channel with zeros. Inference used T2-FLAIR-present and T2-FLAIR-absent scenarios (T2-FLAIR set to zero). The primary endpoint was Dice similarity coefficient (DSC); secondary endpoints were 95th percentile Hausdorff distance and Bland-Altman whole-tumor volume bias. Equivalence was assessed with two one-sided tests using +/-1.5 DSC percentage points, and noninferiority versus HD-GLIO used a -1.5-point margin. Results: With T2-FLAIR present, median overall DSC was 94.8% (interquartile range, 90.0%-97.1%) with dropout and 95.0% (interquartile range, 90.3%-97.1%) without dropout (equivalence supported, p<0.001). With T2-FLAIR absent, median overall DSC improved from 81.0% (interquartile range, 75.1%-86.4%) without dropout to 93.4% (interquartile range, 89.1%-96.2%) with dropout (r=0.35); edema DSC improved from 14.0% to 87.0%, edema 95th percentile Hausdorff distance improved from 22.44 mm to 2.45 mm, and whole-tumor volume bias improved from -45.6 mL to 0.83 mL. Dropout was noninferior to HD-GLIO under T2-FLAIR-present (all p<0.001). Conclusion: Targeted T2-FLAIR dropout preserved segmentation performance when T2-FLAIR was available and reduced segmentation error and whole-tumor volume bias when T2-FLAIR was absent.
Graph Deep Learning for Intracranial Aneurysm Blood Flow Simulation and Risk Assessment
Dec 09, 2025Intracranial aneurysms remain a major cause of neurological morbidity and mortality worldwide, where rupture risk is tightly coupled to local hemodynamics particularly wall shear stress and oscillatory shear index. Conventional computational fluid dynamics simulations provide accurate insights but are prohibitively slow and require specialized expertise. Clinical imaging alternatives such as 4D Flow MRI offer direct in-vivo measurements, yet their spatial resolution remains insufficient to capture the fine-scale shear patterns that drive endothelial remodeling and rupture risk while being extremely impractical and expensive. We present a graph neural network surrogate model that bridges this gap by reproducing full-field hemodynamics directly from vascular geometries in less than one minute per cardiac cycle. Trained on a comprehensive dataset of high-fidelity simulations of patient-specific aneurysms, our architecture combines graph transformers with autoregressive predictions to accurately simulate blood flow, wall shear stress, and oscillatory shear index. The model generalizes across unseen patient geometries and inflow conditions without mesh-specific calibration. Beyond accelerating simulation, our framework establishes the foundation for clinically interpretable hemodynamic prediction. By enabling near real-time inference integrated with existing imaging pipelines, it allows direct comparison with hospital phase-diagram assessments and extends them with physically grounded, high-resolution flow fields. This work transforms high-fidelity simulations from an expert-only research tool into a deployable, data-driven decision support system. Our full pipeline delivers high-resolution hemodynamic predictions within minutes of patient imaging, without requiring computational specialists, marking a step-change toward real-time, bedside aneurysm analysis.
What Can We Learn From MIMO Graph Convolutions?
May 16, 2025Most graph neural networks (GNNs) utilize approximations of the general graph convolution derived in the graph Fourier domain. While GNNs are typically applied in the multi-input multi-output (MIMO) case, the approximations are performed in the single-input single-output (SISO) case. In this work, we first derive the MIMO graph convolution through the convolution theorem and approximate it directly in the MIMO case. We find the key MIMO-specific property of the graph convolution to be operating on multiple computational graphs, or equivalently, applying distinct feature transformations for each pair of nodes. As a localized approximation, we introduce localized MIMO graph convolutions (LMGCs), which generalize many linear message-passing neural networks. For almost every choice of edge weights, we prove that LMGCs with a single computational graph are injective on multisets, and the resulting representations are linearly independent when more than one computational graph is used. Our experimental results confirm that an LMGC can combine the benefits of various methods.
Bridging the Communication Gap: Evaluating AI Labeling Practices for Trustworthy AI Development
Jan 21, 2025As artificial intelligence (AI) becomes integral to economy and society, communication gaps between developers, users, and stakeholders hinder trust and informed decision-making. High-level AI labels, inspired by frameworks like EU energy labels, have been proposed to make the properties of AI models more transparent. Without requiring deep technical expertise, they can inform on the trade-off between predictive performance and resource efficiency. However, the practical benefits and limitations of AI labeling remain underexplored. This study evaluates AI labeling through qualitative interviews along four key research questions. Based on thematic analysis and inductive coding, we found a broad range of practitioners to be interested in AI labeling (RQ1). They see benefits for alleviating communication gaps and aiding non-expert decision-makers, however limitations, misunderstandings, and suggestions for improvement were also discussed (RQ2). Compared to other reporting formats, interviewees positively evaluated the reduced complexity of labels, increasing overall comprehensibility (RQ3). Trust was influenced most by usability and the credibility of the responsible labeling authority, with mixed preferences for self-certification versus third-party certification (RQ4). Our Insights highlight that AI labels pose a trade-off between simplicity and complexity, which could be resolved by developing customizable and interactive labeling frameworks to address diverse user needs. Transparent labeling of resource efficiency also nudged interviewee priorities towards paying more attention to sustainability aspects during AI development. This study validates AI labels as a valuable tool for enhancing trust and communication in AI, offering actionable guidelines for their refinement and standardization.
ICE-T: A Multi-Faceted Concept for Teaching Machine Learning
Nov 08, 2024The topics of Artificial intelligence (AI) and especially Machine Learning (ML) are increasingly making their way into educational curricula. To facilitate the access for students, a variety of platforms, visual tools, and digital games are already being used to introduce ML concepts and strengthen the understanding of how AI works. We take a look at didactic principles that are employed for teaching computer science, define criteria, and, based on those, evaluate a selection of prominent existing platforms, tools, and games. Additionally, we criticize the approach of portraying ML mostly as a black-box and the resulting missing focus on creating an understanding of data, algorithms, and models that come with it. To tackle this issue, we present a concept that covers intermodal transfer, computational and explanatory thinking, ICE-T, as an extension of known didactic principles. With our multi-faceted concept, we believe that planners of learning units, creators of learning platforms and educators can improve on teaching ML.
Preventing Representational Rank Collapse in MPNNs by Splitting the Computational Graph
Sep 17, 2024The ability of message-passing neural networks (MPNNs) to fit complex functions over graphs is limited each iteration of message-passing over a simple makes representations more similar, a phenomenon known as rank collapse, and over-smoothing as a special case. Most approaches to mitigate over-smoothing extend common message-passing schemes, e.g., the graph convolutional network, by utilizing residual connections, gating mechanisms, normalization, or regularization techniques. Our work contrarily proposes to directly tackle the cause of this issue by modifying the message-passing scheme and exchanging different types of messages using multi-relational graphs. We identify the necessary and sufficient condition to ensure linearly independent node representations. As one instantion, we show that operating on multiple directed acyclic graphs always satisfies our condition and propose to obtain these by defining a strict partial ordering of the nodes. We conduct comprehensive experiments that confirm the benefits of operating on multi-relational graphs to achieve more informative node representations.
AALF: Almost Always Linear Forecasting
Sep 16, 2024



Recent works for time-series forecasting more and more leverage the high predictive power of Deep Learning models. With this increase in model complexity, however, comes a lack in understanding of the underlying model decision process, which is problematic for high-stakes decision making. At the same time, simple, interpretable forecasting methods such as Linear Models can still perform very well, sometimes on-par, with Deep Learning approaches. We argue that simple models are good enough most of the time, and forecasting performance can be improved by choosing a Deep Learning method only for certain predictions, increasing the overall interpretability of the forecasting process. In this context, we propose a novel online model selection framework which uses meta-learning to identify these predictions and only rarely uses a non-interpretable, large model. An extensive empirical study on various real-world datasets shows that our selection methodology outperforms state-of-the-art online model selections methods in most cases. We find that almost always choosing a simple Linear Model for forecasting results in competitive performance, suggesting that the need for opaque black-box models in time-series forecasting is smaller than recent works would suggest.
Using Petri Nets as an Integrated Constraint Mechanism for Reinforcement Learning Tasks
Jul 05, 2024The lack of trust in algorithms is usually an issue when using Reinforcement Learning (RL) agents for control in real-world domains such as production plants, autonomous vehicles, or traffic-related infrastructure, partly due to the lack of verifiability of the model itself. In such scenarios, Petri nets (PNs) are often available for flowcharts or process steps, as they are versatile and standardized. In order to facilitate integration of RL models and as a step towards increasing AI trustworthiness, we propose an approach that uses PNs with three main advantages over typical RL approaches: Firstly, the agent can now easily be modeled with a combined state including both external environmental observations and agent-specific state information from a given PN. Secondly, we can enforce constraints for state-dependent actions through the inherent PN model. And lastly, we can increase trustworthiness by verifying PN properties through techniques such as model checking. We test our approach on a typical four-way intersection traffic light control setting and present our results, beating cycle-based baselines.
Enhancing Safety for Autonomous Agents in Partly Concealed Urban Traffic Environments Through Representation-Based Shielding
Jul 05, 2024Navigating unsignalized intersections in urban environments poses a complex challenge for self-driving vehicles, where issues such as view obstructions, unpredictable pedestrian crossings, and diverse traffic participants demand a great focus on crash prevention. In this paper, we propose a novel state representation for Reinforcement Learning (RL) agents centered around the information perceivable by an autonomous agent, enabling the safe navigation of previously uncharted road maps. Our approach surpasses several baseline models by a sig nificant margin in terms of safety and energy consumption metrics. These improvements are achieved while maintaining a competitive average travel speed. Our findings pave the way for more robust and reliable autonomous navigation strategies, promising safer and more efficient urban traffic environments.
Distilling Influences to Mitigate Prediction Churn in Graph Neural Networks
Oct 02, 2023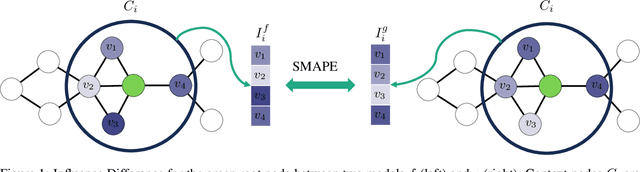
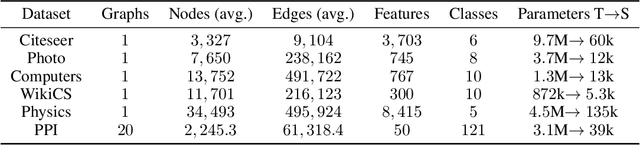
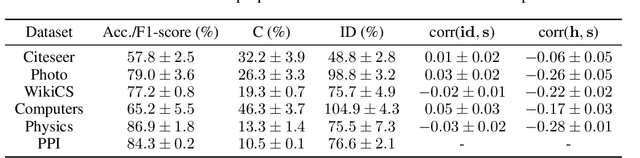
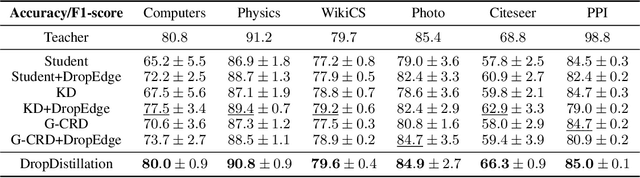
Models with similar performances exhibit significant disagreement in the predictions of individual samples, referred to as prediction churn. Our work explores this phenomenon in graph neural networks by investigating differences between models differing only in their initializations in their utilized features for predictions. We propose a novel metric called Influence Difference (ID) to quantify the variation in reasons used by nodes across models by comparing their influence distribution. Additionally, we consider the differences between nodes with a stable and an unstable prediction, positing that both equally utilize different reasons and thus provide a meaningful gradient signal to closely match two models even when the predictions for nodes are similar. Based on our analysis, we propose to minimize this ID in Knowledge Distillation, a domain where a new model should closely match an established one. As an efficient approximation, we introduce DropDistillation (DD) that matches the output for a graph perturbed by edge deletions. Our empirical evaluation of six benchmark datasets for node classification validates the differences in utilized features. DD outperforms previous methods regarding prediction stability and overall performance in all considered Knowledge Distillation experiments.