 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePruning Extensions and Efficiency Trade-Offs for Sustainable Time Series Classification
Apr 09, 2026Time series classification (TSC) enables important use cases, however lacks a unified understanding of performance trade-offs across models, datasets, and hardware. While resource awareness has grown in the field, TSC methods have not yet been rigorously evaluated for energy efficiency. This paper introduces a holistic evaluation framework that explicitly explores the balance of predictive performance and resource consumption in TSC. To boost efficiency, we apply a theoretically bounded pruning strategy to leading hybrid classifiers - Hydra and Quant - and present Hydrant, a novel, prunable combination of both. With over 4000 experimental configurations across 20 MONSTER datasets, 13 methods, and three compute setups, we systematically analyze how model design, hyperparameters, and hardware choices affect practical TSC performance. Our results showcase that pruning can significantly reduce energy consumption by up to 80% while maintaining competitive predictive quality, usually costing the model less than 5% of accuracy. The proposed methodology, experimental results, and accompanying software advance TSC toward sustainable and reproducible practice.
Decentralized Time Series Classification with ROCKET Features
Apr 24, 2025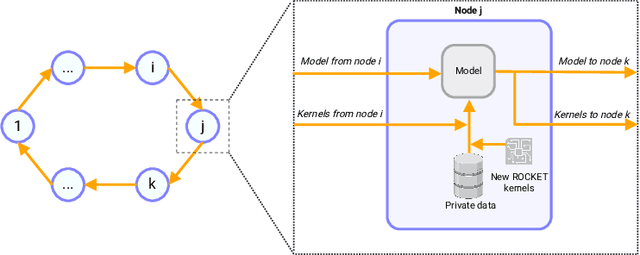

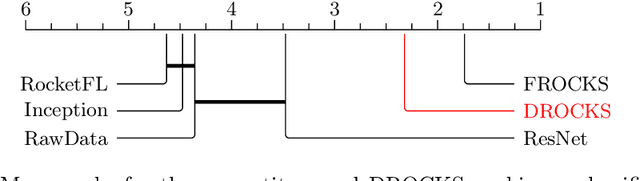

Time series classification (TSC) is a critical task with applications in various domains, including healthcare, finance, and industrial monitoring. Due to privacy concerns and data regulations, Federated Learning has emerged as a promising approach for learning from distributed time series data without centralizing raw information. However, most FL solutions rely on a client-server architecture, which introduces robustness and confidentiality risks related to the distinguished role of the server, which is a single point of failure and can observe knowledge extracted from clients. To address these challenges, we propose DROCKS, a fully decentralized FL framework for TSC that leverages ROCKET (RandOm Convolutional KErnel Transform) features. In DROCKS, the global model is trained by sequentially traversing a structured path across federation nodes, where each node refines the model and selects the most effective local kernels before passing them to the successor. Extensive experiments on the UCR archive demonstrate that DROCKS outperforms state-of-the-art client-server FL approaches while being more resilient to node failures and malicious attacks. Our code is available at https://anonymous.4open.science/r/DROCKS-7FF3/README.md.
Interpretable Rules for Online Failure Prediction: A Case Study on the Metro do Porto dataset
Feb 11, 2025Due to their high predictive performance, predictive maintenance applications have increasingly been approached with Deep Learning techniques in recent years. However, as in other real-world application scenarios, the need for explainability is often stated but not sufficiently addressed. This study will focus on predicting failures on Metro trains in Porto, Portugal. While recent works have found high-performing deep neural network architectures that feature a parallel explainability pipeline, the generated explanations are fairly complicated and need help explaining why the failures are happening. This work proposes a simple online rule-based explainability approach with interpretable features that leads to straightforward, interpretable rules. We showcase our approach on MetroPT2 and find that three specific sensors on the Metro do Porto trains suffice to predict the failures present in the dataset with simple rules.
AALF: Almost Always Linear Forecasting
Sep 16, 2024



Recent works for time-series forecasting more and more leverage the high predictive power of Deep Learning models. With this increase in model complexity, however, comes a lack in understanding of the underlying model decision process, which is problematic for high-stakes decision making. At the same time, simple, interpretable forecasting methods such as Linear Models can still perform very well, sometimes on-par, with Deep Learning approaches. We argue that simple models are good enough most of the time, and forecasting performance can be improved by choosing a Deep Learning method only for certain predictions, increasing the overall interpretability of the forecasting process. In this context, we propose a novel online model selection framework which uses meta-learning to identify these predictions and only rarely uses a non-interpretable, large model. An extensive empirical study on various real-world datasets shows that our selection methodology outperforms state-of-the-art online model selections methods in most cases. We find that almost always choosing a simple Linear Model for forecasting results in competitive performance, suggesting that the need for opaque black-box models in time-series forecasting is smaller than recent works would suggest.
Explainable Adaptive Tree-based Model Selection for Time Series Forecasting
Jan 02, 2024Tree-based models have been successfully applied to a wide variety of tasks, including time series forecasting. They are increasingly in demand and widely accepted because of their comparatively high level of interpretability. However, many of them suffer from the overfitting problem, which limits their application in real-world decision-making. This problem becomes even more severe in online-forecasting settings where time series observations are incrementally acquired, and the distributions from which they are drawn may keep changing over time. In this context, we propose a novel method for the online selection of tree-based models using the TreeSHAP explainability method in the task of time series forecasting. We start with an arbitrary set of different tree-based models. Then, we outline a performance-based ranking with a coherent design to make TreeSHAP able to specialize the tree-based forecasters across different regions in the input time series. In this framework, adequate model selection is performed online, adaptively following drift detection in the time series. In addition, explainability is supported on three levels, namely online input importance, model selection, and model output explanation. An extensive empirical study on various real-world datasets demonstrates that our method achieves excellent or on-par results in comparison to the state-of-the-art approaches as well as several baselines.
An Empirical Evaluation of the Rashomon Effect in Explainable Machine Learning
Jun 29, 2023The Rashomon Effect describes the following phenomenon: for a given dataset there may exist many models with equally good performance but with different solution strategies. The Rashomon Effect has implications for Explainable Machine Learning, especially for the comparability of explanations. We provide a unified view on three different comparison scenarios and conduct a quantitative evaluation across different datasets, models, attribution methods, and metrics. We find that hyperparameter-tuning plays a role and that metric selection matters. Our results provide empirical support for previously anecdotal evidence and exhibit challenges for both scientists and practitioners.
Energy Efficiency Considerations for Popular AI Benchmarks
Apr 17, 2023Advances in artificial intelligence need to become more resource-aware and sustainable. This requires clear assessment and reporting of energy efficiency trade-offs, like sacrificing fast running time for higher predictive performance. While first methods for investigating efficiency have been proposed, we still lack comprehensive results for popular methods and data sets. In this work, we attempt to fill this information gap by providing empiric insights for popular AI benchmarks, with a total of 100 experiments. Our findings are evidence of how different data sets all have their own efficiency landscape, and show that methods can be more or less likely to act efficiently.
Explainable Quantum Machine Learning
Jan 22, 2023Methods of artificial intelligence (AI) and especially machine learning (ML) have been growing ever more complex, and at the same time have more and more impact on people's lives. This leads to explainable AI (XAI) manifesting itself as an important research field that helps humans to better comprehend ML systems. In parallel, quantum machine learning (QML) is emerging with the ongoing improvement of quantum computing hardware combined with its increasing availability via cloud services. QML enables quantum-enhanced ML in which quantum mechanics is exploited to facilitate ML tasks, typically in form of quantum-classical hybrid algorithms that combine quantum and classical resources. Quantum gates constitute the building blocks of gate-based quantum hardware and form circuits that can be used for quantum computations. For QML applications, quantum circuits are typically parameterized and their parameters are optimized classically such that a suitably defined objective function is minimized. Inspired by XAI, we raise the question of explainability of such circuits by quantifying the importance of (groups of) gates for specific goals. To this end, we transfer and adapt the well-established concept of Shapley values to the quantum realm. The resulting attributions can be interpreted as explanations for why a specific circuit works well for a given task, improving the understanding of how to construct parameterized (or variational) quantum circuits, and fostering their human interpretability in general. An experimental evaluation on simulators and two superconducting quantum hardware devices demonstrates the benefits of the proposed framework for classification, generative modeling, transpilation, and optimization. Furthermore, our results shed some light on the role of specific gates in popular QML approaches.
Shapley Values with Uncertain Value Functions
Jan 19, 2023We propose a novel definition of Shapley values with uncertain value functions based on first principles using probability theory. Such uncertain value functions can arise in the context of explainable machine learning as a result of non-deterministic algorithms. We show that random effects can in fact be absorbed into a Shapley value with a noiseless but shifted value function. Hence, Shapley values with uncertain value functions can be used in analogy to regular Shapley values. However, their reliable evaluation typically requires more computational effort.
Yes We Care! -- Certification for Machine Learning Methods through the Care Label Framework
May 21, 2021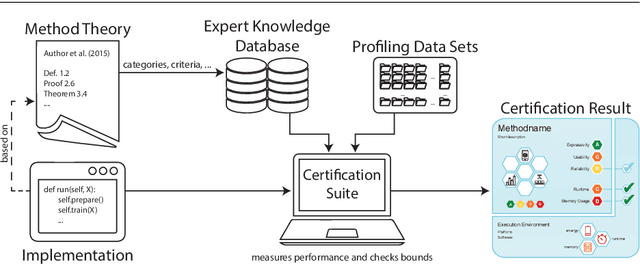
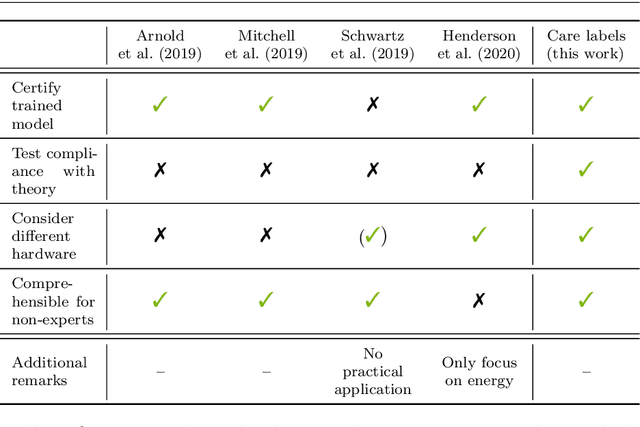
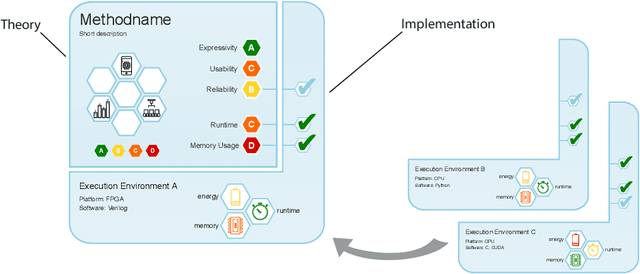
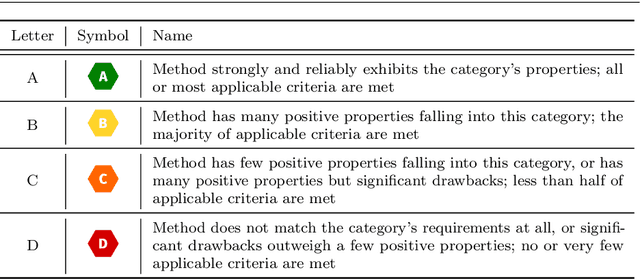
Machine learning applications have become ubiquitous. Their applications from machine embedded control in production over process optimization in diverse areas (e.g., traffic, finance, sciences) to direct user interactions like advertising and recommendations. This has led to an increased effort of making machine learning trustworthy. Explainable and fair AI have already matured. They address knowledgeable users and application engineers. However, there are users that want to deploy a learned model in a similar way as their washing machine. These stakeholders do not want to spend time understanding the model. Instead, they want to rely on guaranteed properties. What are the relevant properties? How can they be expressed to stakeholders without presupposing machine learning knowledge? How can they be guaranteed for a certain implementation of a model? These questions move far beyond the current state-of-the-art and we want to address them here. We propose a unified framework that certifies learning methods via care labels. They are easy to understand and draw inspiration from well-known certificates like textile labels or property cards of electronic devices. Our framework considers both, the machine learning theory and a given implementation. We test the implementation's compliance with theoretical properties and bounds. In this paper, we illustrate care labels by a prototype implementation of a certification suite for a selection of probabilistic graphical models.