 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainability-Aware One Point Attack for Point Cloud Neural Networks
Oct 08, 2021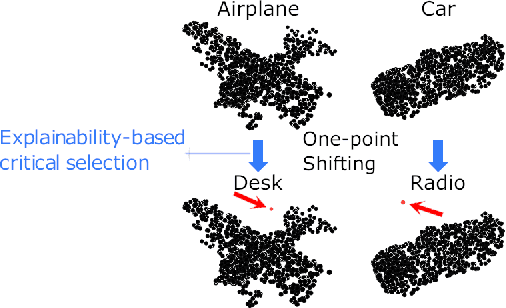
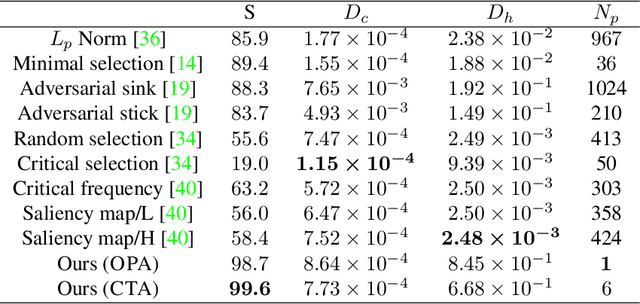


With the proposition of neural networks for point clouds, deep learning has started to shine in the field of 3D object recognition while researchers have shown an increased interest to investigate the reliability of point cloud networks by fooling them with perturbed instances. However, most studies focus on the imperceptibility or surface consistency, with humans perceiving no perturbations on the adversarial examples. This work proposes two new attack methods: opa and cta, which go in the opposite direction: we restrict the perturbation dimensions to a human cognizable range with the help of explainability methods, which enables the working principle or decision boundary of the models to be comprehensible through the observable perturbation magnitude. Our results show that the popular point cloud networks can be deceived with almost 100% success rate by shifting only one point from the input instance. In addition, we attempt to provide a more persuasive viewpoint of comparing the robustness of point cloud models against adversarial attacks. We also show the interesting impact of different point attribution distributions on the adversarial robustness of point cloud networks. Finally, we discuss how our approaches facilitate the explainability study for point cloud networks. To the best of our knowledge, this is the first point-cloud-based adversarial approach concerning explainability. Our code is available at https://github.com/Explain3D/Exp-One-Point-Atk-PC.
Surrogate Model-Based Explainability Methods for Point Cloud NNs
Aug 18, 2021


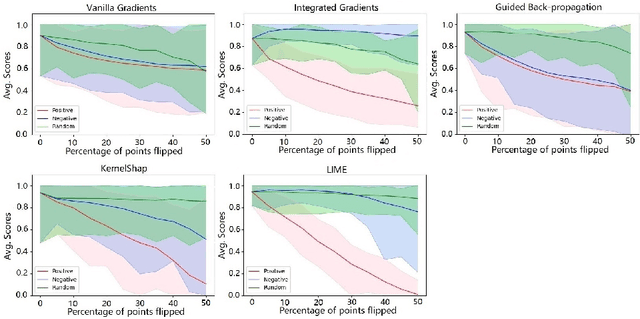
In the field of autonomous driving and robotics, point clouds are showing their excellent real-time performance as raw data from most of the mainstream 3D sensors. Therefore, point cloud neural networks have become a popular research direction in recent years. So far, however, there has been little discussion about the explainability of deep neural networks for point clouds. In this paper, we propose a point cloud-applicable explainability approach based on local surrogate model-based method to show which components contribute to the classification. Moreover, we propose quantitative fidelity validations for generated explanations that enhance the persuasive power of explainability and compare the plausibility of different existing point cloud-applicable explainability methods. Our new explainability approach provides a fairly accurate, more semantically coherent and widely applicable explanation for point cloud classification tasks. Our code is available at https://github.com/Explain3D/LIME-3D
The Care Label Concept: A Certification Suite for Trustworthy and Resource-Aware Machine Learning
Jun 01, 2021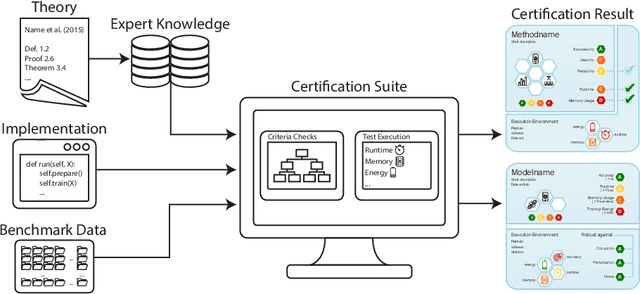
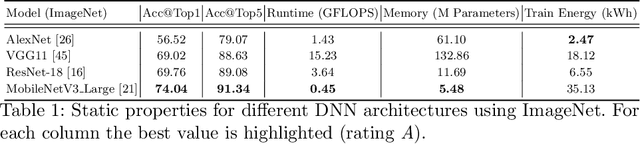
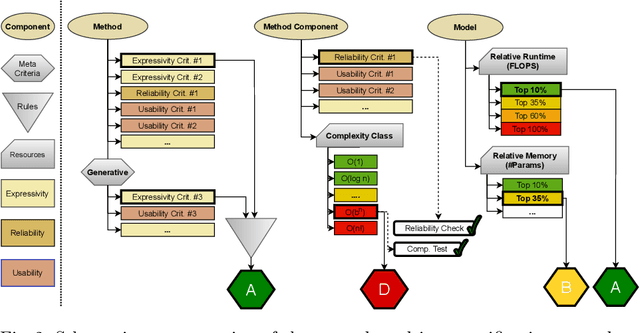
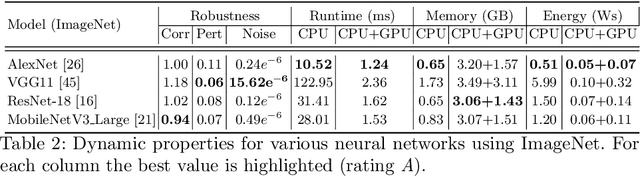
Machine learning applications have become ubiquitous. This has led to an increased effort of making machine learning trustworthy. Explainable and fair AI have already matured. They address knowledgeable users and application engineers. For those who do not want to invest time into understanding the method or the learned model, we offer care labels: easy to understand at a glance, allowing for method or model comparisons, and, at the same time, scientifically well-based. On one hand, this transforms descriptions as given by, e.g., Fact Sheets or Model Cards, into a form that is well-suited for end-users. On the other hand, care labels are the result of a certification suite that tests whether stated guarantees hold. In this paper, we present two experiments with our certification suite. One shows the care labels for configurations of Markov random fields (MRFs). Based on the underlying theory of MRFs, each choice leads to its specific rating of static properties like, e.g., expressivity and reliability. In addition, the implementation is tested and resource consumption is measured yielding dynamic properties. This two-level procedure is followed by another experiment certifying deep neural network (DNN) models. There, we draw the static properties from the literature on a particular model and data set. At the second level, experiments are generated that deliver measurements of robustness against certain attacks. We illustrate this by ResNet-18 and MobileNetV3 applied to ImageNet.
Yes We Care! -- Certification for Machine Learning Methods through the Care Label Framework
May 21, 2021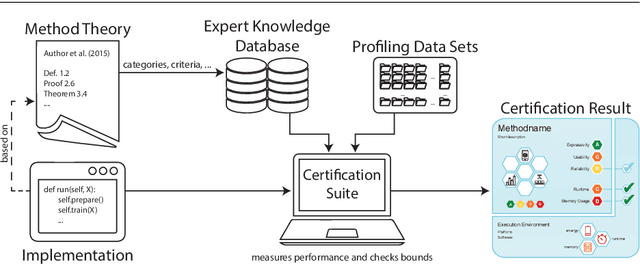
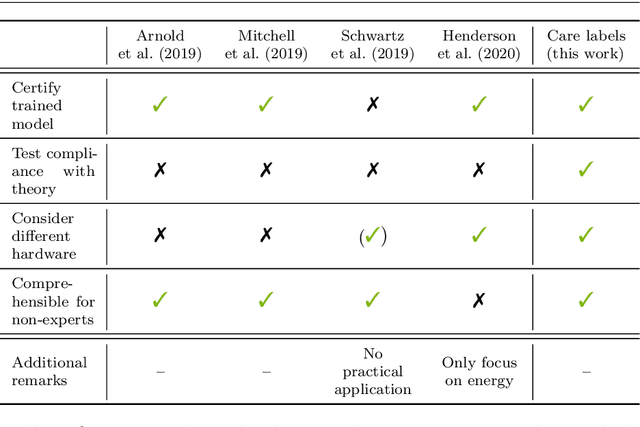
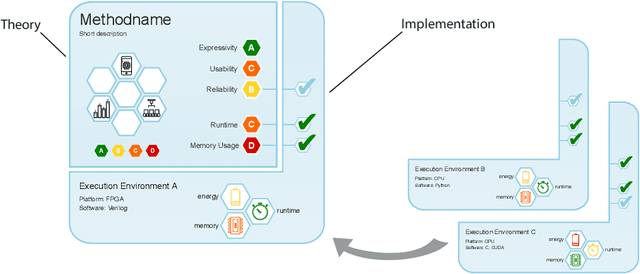
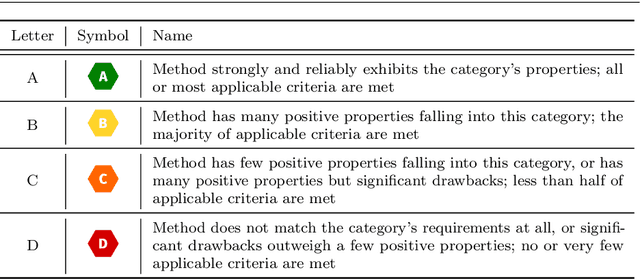
Machine learning applications have become ubiquitous. Their applications from machine embedded control in production over process optimization in diverse areas (e.g., traffic, finance, sciences) to direct user interactions like advertising and recommendations. This has led to an increased effort of making machine learning trustworthy. Explainable and fair AI have already matured. They address knowledgeable users and application engineers. However, there are users that want to deploy a learned model in a similar way as their washing machine. These stakeholders do not want to spend time understanding the model. Instead, they want to rely on guaranteed properties. What are the relevant properties? How can they be expressed to stakeholders without presupposing machine learning knowledge? How can they be guaranteed for a certain implementation of a model? These questions move far beyond the current state-of-the-art and we want to address them here. We propose a unified framework that certifies learning methods via care labels. They are easy to understand and draw inspiration from well-known certificates like textile labels or property cards of electronic devices. Our framework considers both, the machine learning theory and a given implementation. We test the implementation's compliance with theoretical properties and bounds. In this paper, we illustrate care labels by a prototype implementation of a certification suite for a selection of probabilistic graphical models.