 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Care Label Concept: A Certification Suite for Trustworthy and Resource-Aware Machine Learning
Jun 01, 2021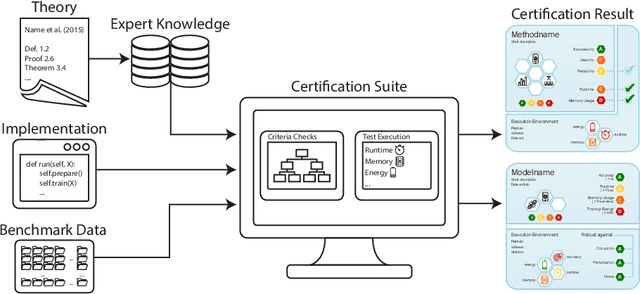
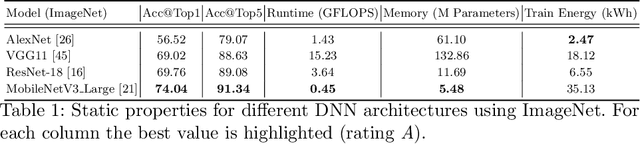
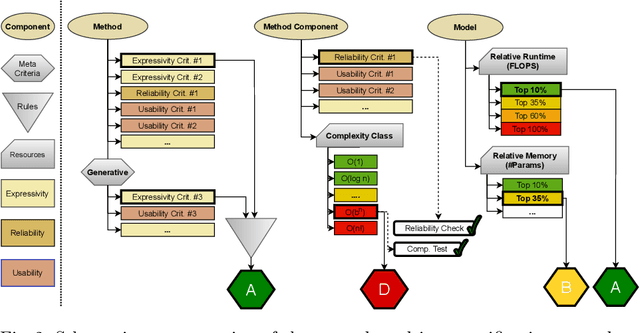
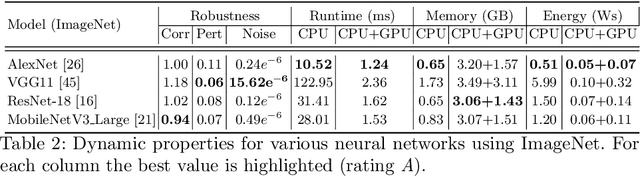
Machine learning applications have become ubiquitous. This has led to an increased effort of making machine learning trustworthy. Explainable and fair AI have already matured. They address knowledgeable users and application engineers. For those who do not want to invest time into understanding the method or the learned model, we offer care labels: easy to understand at a glance, allowing for method or model comparisons, and, at the same time, scientifically well-based. On one hand, this transforms descriptions as given by, e.g., Fact Sheets or Model Cards, into a form that is well-suited for end-users. On the other hand, care labels are the result of a certification suite that tests whether stated guarantees hold. In this paper, we present two experiments with our certification suite. One shows the care labels for configurations of Markov random fields (MRFs). Based on the underlying theory of MRFs, each choice leads to its specific rating of static properties like, e.g., expressivity and reliability. In addition, the implementation is tested and resource consumption is measured yielding dynamic properties. This two-level procedure is followed by another experiment certifying deep neural network (DNN) models. There, we draw the static properties from the literature on a particular model and data set. At the second level, experiments are generated that deliver measurements of robustness against certain attacks. We illustrate this by ResNet-18 and MobileNetV3 applied to ImageNet.
Yes We Care! -- Certification for Machine Learning Methods through the Care Label Framework
May 21, 2021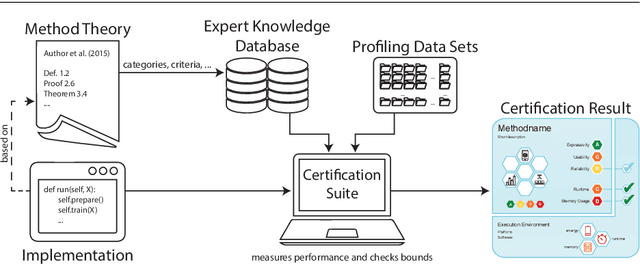
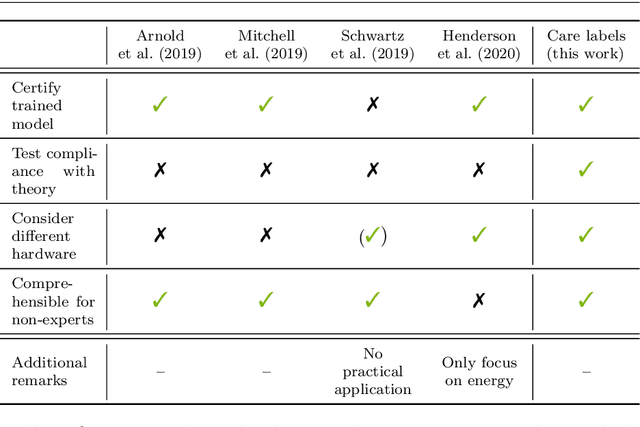
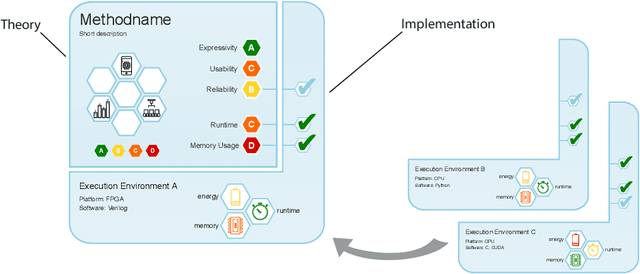
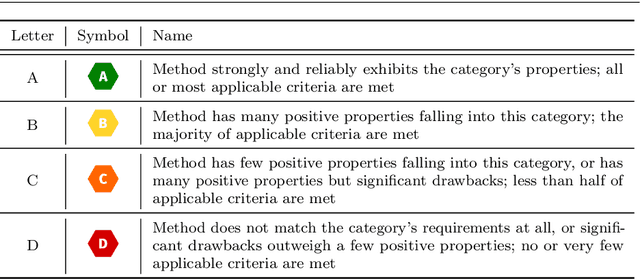
Machine learning applications have become ubiquitous. Their applications from machine embedded control in production over process optimization in diverse areas (e.g., traffic, finance, sciences) to direct user interactions like advertising and recommendations. This has led to an increased effort of making machine learning trustworthy. Explainable and fair AI have already matured. They address knowledgeable users and application engineers. However, there are users that want to deploy a learned model in a similar way as their washing machine. These stakeholders do not want to spend time understanding the model. Instead, they want to rely on guaranteed properties. What are the relevant properties? How can they be expressed to stakeholders without presupposing machine learning knowledge? How can they be guaranteed for a certain implementation of a model? These questions move far beyond the current state-of-the-art and we want to address them here. We propose a unified framework that certifies learning methods via care labels. They are easy to understand and draw inspiration from well-known certificates like textile labels or property cards of electronic devices. Our framework considers both, the machine learning theory and a given implementation. We test the implementation's compliance with theoretical properties and bounds. In this paper, we illustrate care labels by a prototype implementation of a certification suite for a selection of probabilistic graphical models.
Lessons Learned from the 1st ARIEL Machine Learning Challenge: Correcting Transiting Exoplanet Light Curves for Stellar Spots
Oct 29, 2020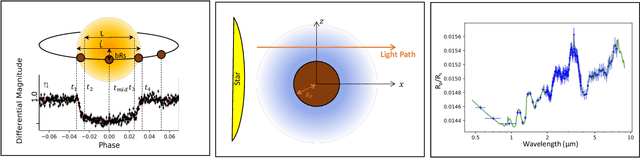

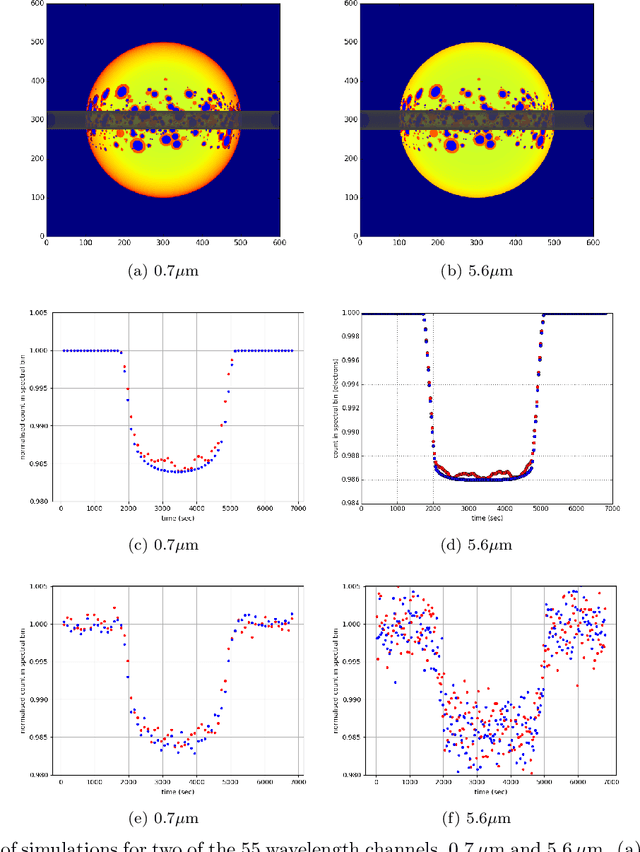
The last decade has witnessed a rapid growth of the field of exoplanet discovery and characterisation. However, several big challenges remain, many of which could be addressed using machine learning methodology. For instance, the most prolific method for detecting exoplanets and inferring several of their characteristics, transit photometry, is very sensitive to the presence of stellar spots. The current practice in the literature is to identify the effects of spots visually and correct for them manually or discard the affected data. This paper explores a first step towards fully automating the efficient and precise derivation of transit depths from transit light curves in the presence of stellar spots. The methods and results we present were obtained in the context of the 1st Machine Learning Challenge organized for the European Space Agency's upcoming Ariel mission. We first present the problem, the simulated Ariel-like data and outline the Challenge while identifying best practices for organizing similar challenges in the future. Finally, we present the solutions obtained by the top-5 winning teams, provide their code and discuss their implications. Successful solutions either construct highly non-linear (w.r.t. the raw data) models with minimal preprocessing -deep neural networks and ensemble methods- or amount to obtaining meaningful statistics from the light curves, constructing linear models on which yields comparably good predictive performance.
Resource-Constrained On-Device Learning by Dynamic Averaging
Sep 25, 2020
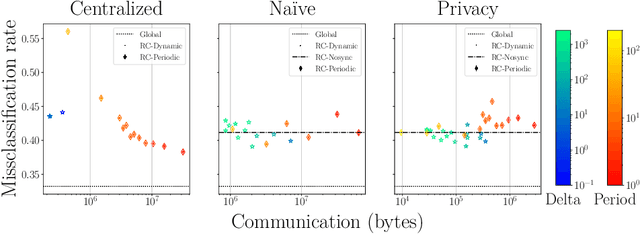
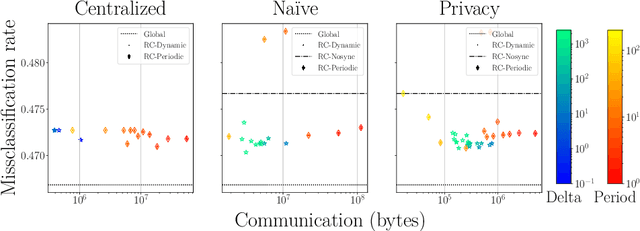
The communication between data-generating devices is partially responsible for a growing portion of the world's power consumption. Thus reducing communication is vital, both, from an economical and an ecological perspective. For machine learning, on-device learning avoids sending raw data, which can reduce communication substantially. Furthermore, not centralizing the data protects privacy-sensitive data. However, most learning algorithms require hardware with high computation power and thus high energy consumption. In contrast, ultra-low-power processors, like FPGAs or micro-controllers, allow for energy-efficient learning of local models. Combined with communication-efficient distributed learning strategies, this reduces the overall energy consumption and enables applications that were yet impossible due to limited energy on local devices. The major challenge is then, that the low-power processors typically only have integer processing capabilities. This paper investigates an approach to communication-efficient on-device learning of integer exponential families that can be executed on low-power processors, is privacy-preserving, and effectively minimizes communication. The empirical evaluation shows that the approach can reach a model quality comparable to a centrally learned regular model with an order of magnitude less communication. Comparing the overall energy consumption, this reduces the required energy for solving the machine learning task by a significant amount.