 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverview and practical recommendations on using Shapley Values for identifying predictive biomarkers via CATE modeling
May 02, 2025
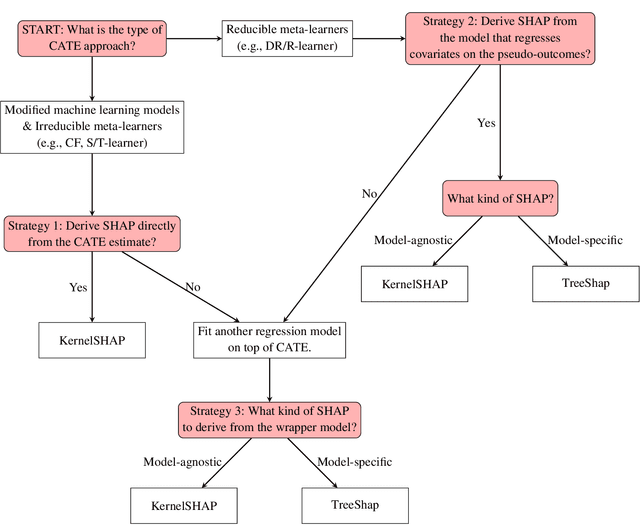
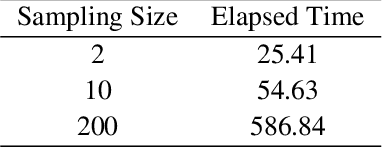
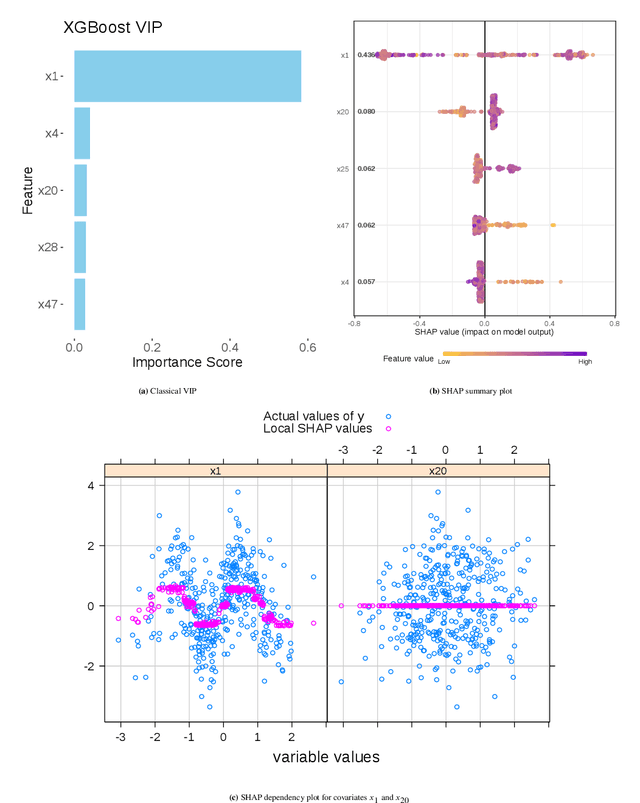
In recent years, two parallel research trends have emerged in machine learning, yet their intersections remain largely unexplored. On one hand, there has been a significant increase in literature focused on Individual Treatment Effect (ITE) modeling, particularly targeting the Conditional Average Treatment Effect (CATE) using meta-learner techniques. These approaches often aim to identify causal effects from observational data. On the other hand, the field of Explainable Machine Learning (XML) has gained traction, with various approaches developed to explain complex models and make their predictions more interpretable. A prominent technique in this area is Shapley Additive Explanations (SHAP), which has become mainstream in data science for analyzing supervised learning models. However, there has been limited exploration of SHAP application in identifying predictive biomarkers through CATE models, a crucial aspect in pharmaceutical precision medicine. We address inherent challenges associated with the SHAP concept in multi-stage CATE strategies and introduce a surrogate estimation approach that is agnostic to the choice of CATE strategy, effectively reducing computational burdens in high-dimensional data. Using this approach, we conduct simulation benchmarking to evaluate the ability to accurately identify biomarkers using SHAP values derived from various CATE meta-learners and Causal Forest.
Finding Pegasus: Enhancing Unsupervised Anomaly Detection in High-Dimensional Data using a Manifold-Based Approach
Feb 06, 2025Unsupervised machine learning methods are well suited to searching for anomalies at scale but can struggle with the high-dimensional representation of many modern datasets, hence dimensionality reduction (DR) is often performed first. In this paper we analyse unsupervised anomaly detection (AD) from the perspective of the manifold created in DR. We present an idealised illustration, "Finding Pegasus", and a novel formal framework with which we categorise AD methods and their results into "on manifold" and "off manifold". We define these terms and show how they differ. We then use this insight to develop an approach of combining AD methods which significantly boosts AD recall without sacrificing precision in situations employing high DR. When tested on MNIST data, our approach of combining AD methods improves recall by as much as 16 percent compared with simply combining with the best standalone AD method (Isolation Forest), a result which shows great promise for its application to real-world data.
Don't Pay Attention to the Noise: Learning Self-supervised Representations of Light Curves with a Denoising Time Series Transformer
Jul 06, 2022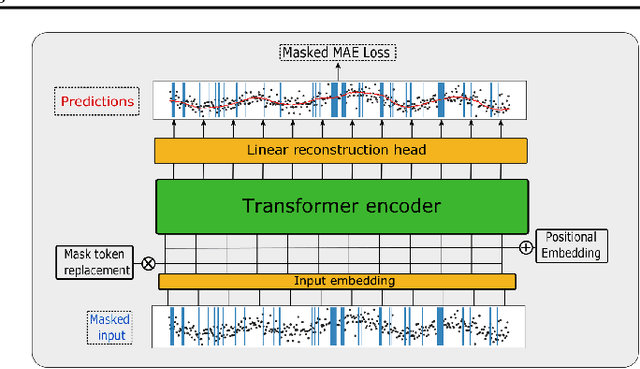

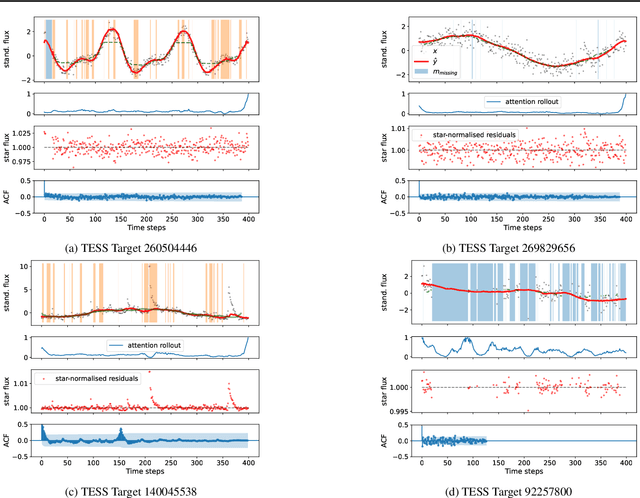

Astrophysical light curves are particularly challenging data objects due to the intensity and variety of noise contaminating them. Yet, despite the astronomical volumes of light curves available, the majority of algorithms used to process them are still operating on a per-sample basis. To remedy this, we propose a simple Transformer model -- called Denoising Time Series Transformer (DTST) -- and show that it excels at removing the noise and outliers in datasets of time series when trained with a masked objective, even when no clean targets are available. Moreover, the use of self-attention enables rich and illustrative queries into the learned representations. We present experiments on real stellar light curves from the Transiting Exoplanet Space Satellite (TESS), showing advantages of our approach compared to traditional denoising techniques.
Fast Regression of the Tritium Breeding Ratio in Fusion Reactors
Apr 08, 2021
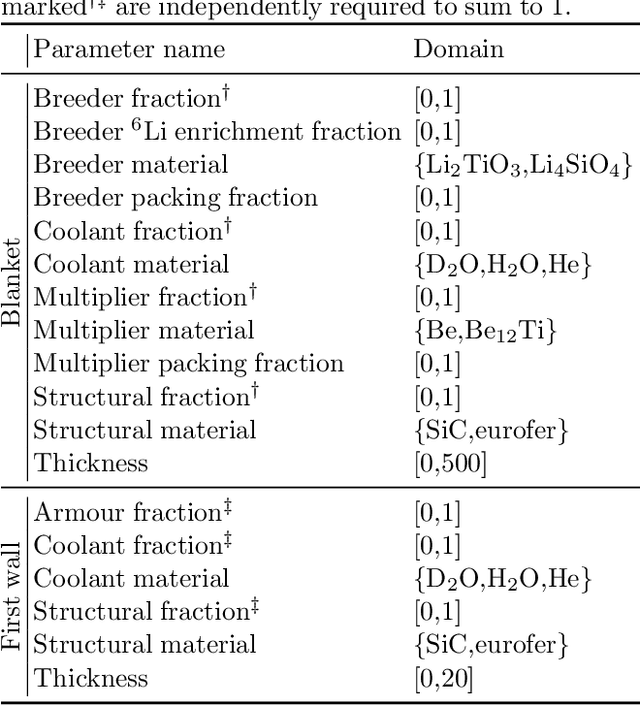
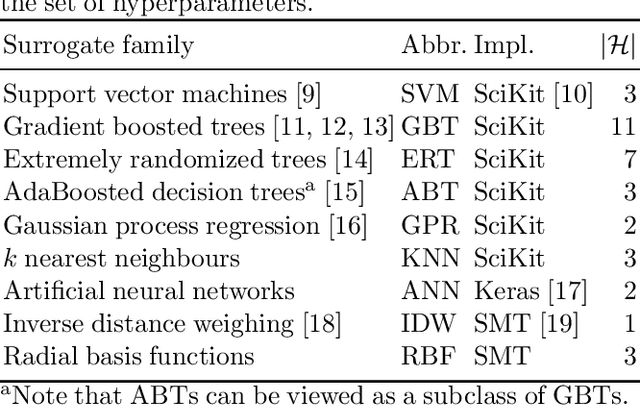
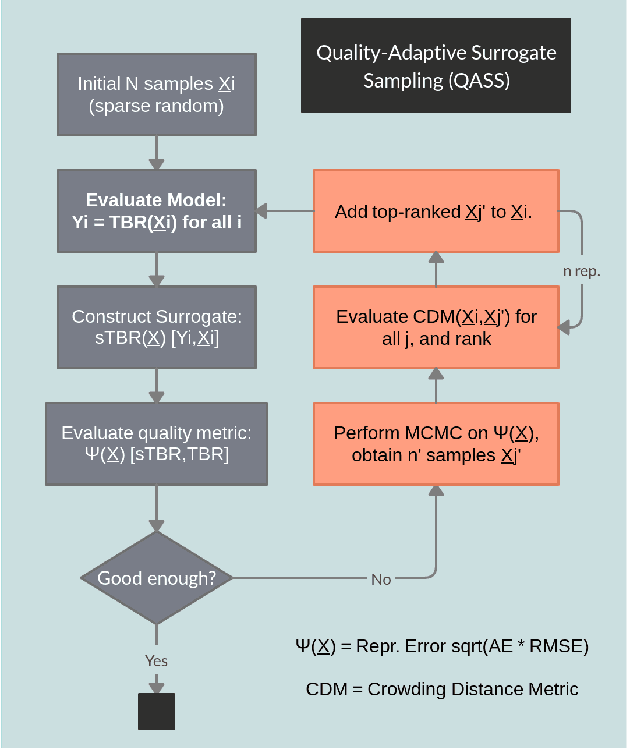
The tritium breeding ratio (TBR) is an essential quantity for the design of modern and next-generation D-T fueled nuclear fusion reactors. Representing the ratio between tritium fuel generated in breeding blankets and fuel consumed during reactor runtime, the TBR depends on reactor geometry and material properties in a complex manner. In this work, we explored the training of surrogate models to produce a cheap but high-quality approximation for a Monte Carlo TBR model in use at the UK Atomic Energy Authority. We investigated possibilities for dimensional reduction of its feature space, reviewed 9 families of surrogate models for potential applicability, and performed hyperparameter optimisation. Here we present the performance and scaling properties of these models, the fastest of which, an artificial neural network, demonstrated $R^2=0.985$ and a mean prediction time of $0.898\ \mu\mathrm{s}$, representing a relative speedup of $8\cdot 10^6$ with respect to the expensive MC model. We further present a novel adaptive sampling algorithm, Quality-Adaptive Surrogate Sampling, capable of interfacing with any of the individually studied surrogates. Our preliminary testing on a toy TBR theory has demonstrated the efficacy of this algorithm for accelerating the surrogate modelling process.
Peeking inside the Black Box: Interpreting Deep Learning Models for Exoplanet Atmospheric Retrievals
Nov 23, 2020
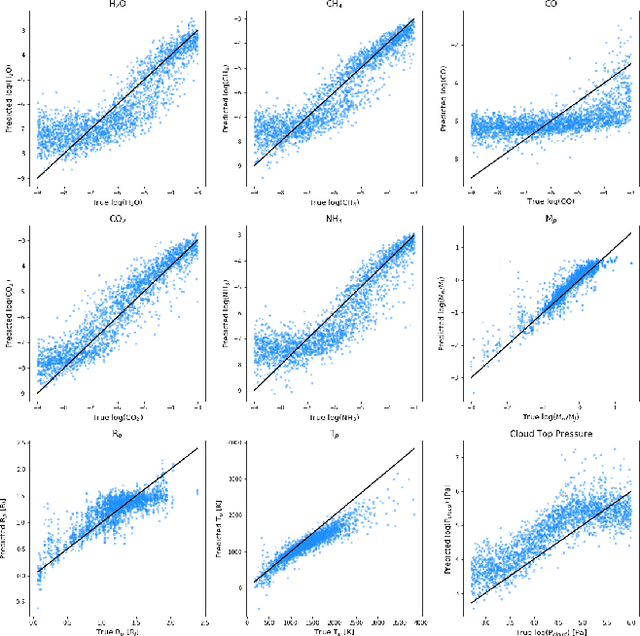
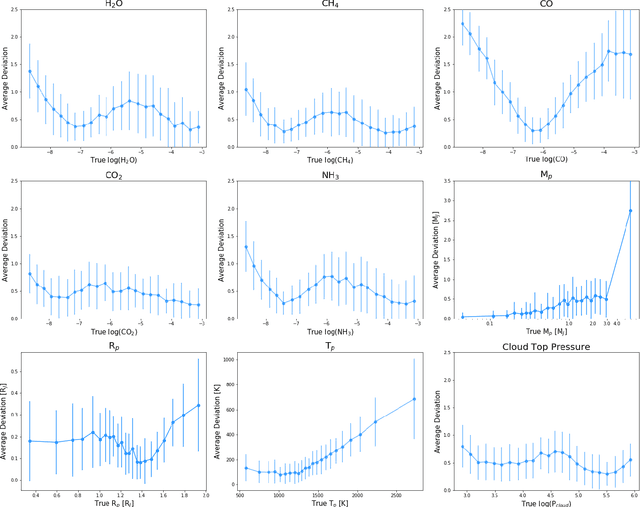

Deep learning algorithms are growing in popularity in the field of exoplanetary science due to their ability to model highly non-linear relations and solve interesting problems in a data-driven manner. Several works have attempted to perform fast retrievals of atmospheric parameters with the use of machine learning algorithms like deep neural networks (DNNs). Yet, despite their high predictive power, DNNs are also infamous for being 'black boxes'. It is their apparent lack of explainability that makes the astrophysics community reluctant to adopt them. What are their predictions based on? How confident should we be in them? When are they wrong and how wrong can they be? In this work, we present a number of general evaluation methodologies that can be applied to any trained model and answer questions like these. In particular, we train three different popular DNN architectures to retrieve atmospheric parameters from exoplanet spectra and show that all three achieve good predictive performance. We then present an extensive analysis of the predictions of DNNs, which can inform us - among other things - of the credibility limits for atmospheric parameters for a given instrument and model. Finally, we perform a perturbation-based sensitivity analysis to identify to which features of the spectrum the outcome of the retrieval is most sensitive. We conclude that for different molecules, the wavelength ranges to which the DNN's predictions are most sensitive, indeed coincide with their characteristic absorption regions. The methodologies presented in this work help to improve the evaluation of DNNs and to grant interpretability to their predictions.
PyLightcurve-torch: a transit modelling package for deep learning applications in PyTorch
Nov 03, 2020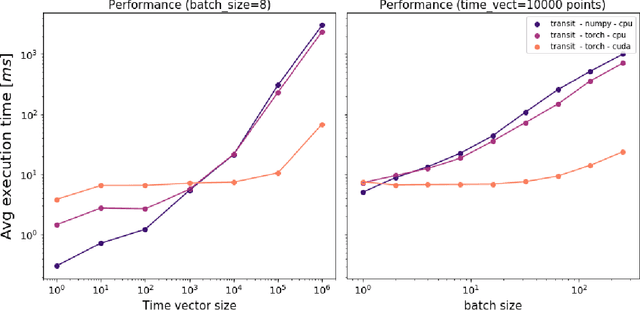
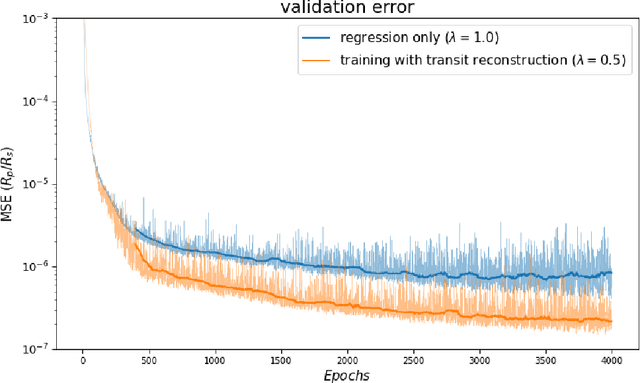
We present a new open source python package, based on PyLightcurve and PyTorch, tailored for efficient computation and automatic differentiation of exoplanetary transits. The classes and functions implemented are fully vectorised, natively GPU-compatible and differentiable with respect to the stellar and planetary parameters. This makes PyLightcurve-torch suitable for traditional forward computation of transits, but also extends the range of possible applications with inference and optimisation algorithms requiring access to the gradients of the physical model. This endeavour is aimed at fostering the use of deep learning in exoplanets research, motivated by an ever increasing amount of stellar light curves data and various incentives for the improvement of detection and characterisation techniques.
Lessons Learned from the 1st ARIEL Machine Learning Challenge: Correcting Transiting Exoplanet Light Curves for Stellar Spots
Oct 29, 2020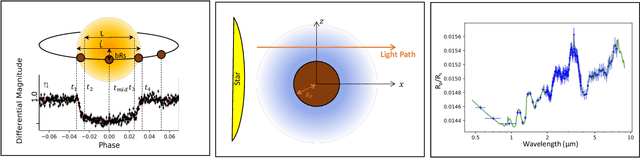

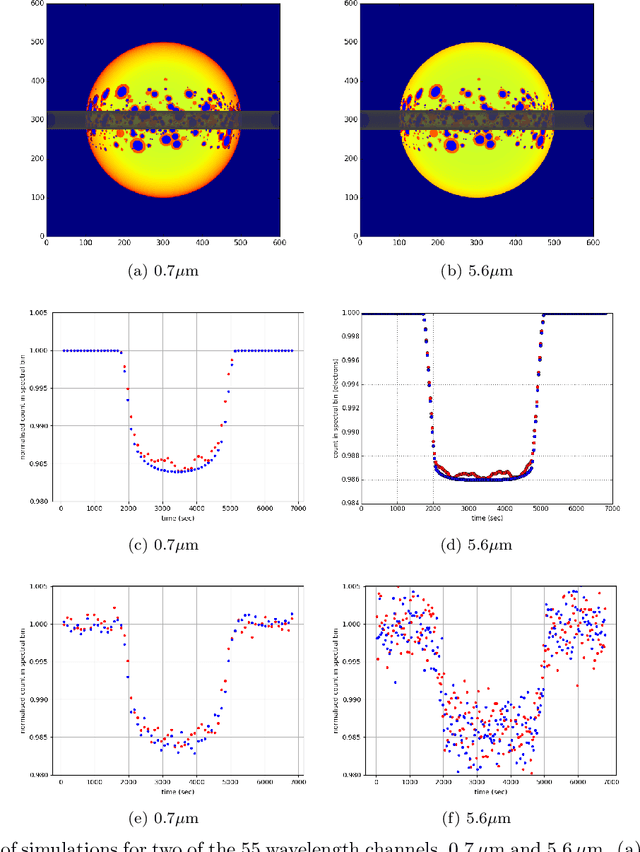
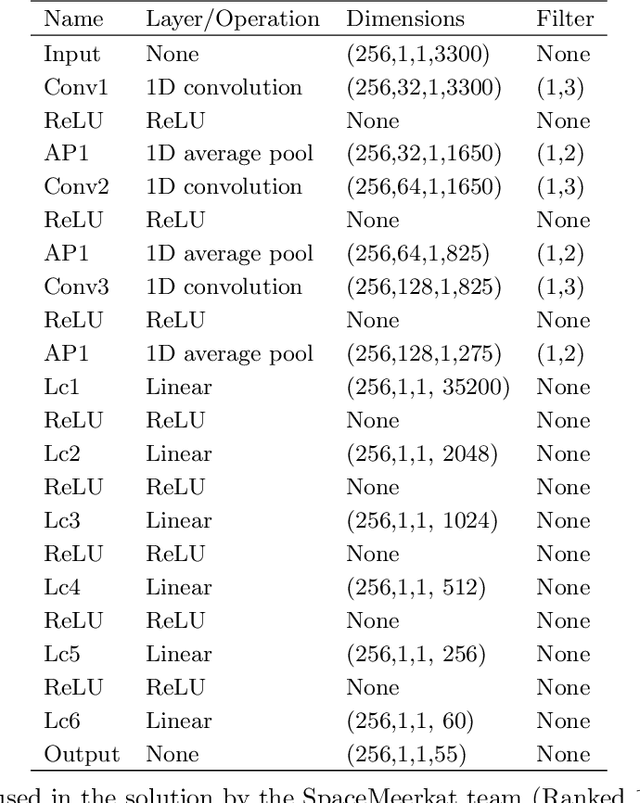
The last decade has witnessed a rapid growth of the field of exoplanet discovery and characterisation. However, several big challenges remain, many of which could be addressed using machine learning methodology. For instance, the most prolific method for detecting exoplanets and inferring several of their characteristics, transit photometry, is very sensitive to the presence of stellar spots. The current practice in the literature is to identify the effects of spots visually and correct for them manually or discard the affected data. This paper explores a first step towards fully automating the efficient and precise derivation of transit depths from transit light curves in the presence of stellar spots. The methods and results we present were obtained in the context of the 1st Machine Learning Challenge organized for the European Space Agency's upcoming Ariel mission. We first present the problem, the simulated Ariel-like data and outline the Challenge while identifying best practices for organizing similar challenges in the future. Finally, we present the solutions obtained by the top-5 winning teams, provide their code and discuss their implications. Successful solutions either construct highly non-linear (w.r.t. the raw data) models with minimal preprocessing -deep neural networks and ensemble methods- or amount to obtaining meaningful statistics from the light curves, constructing linear models on which yields comparably good predictive performance.
Inferring Causal Direction from Observational Data: A Complexity Approach
Oct 12, 2020
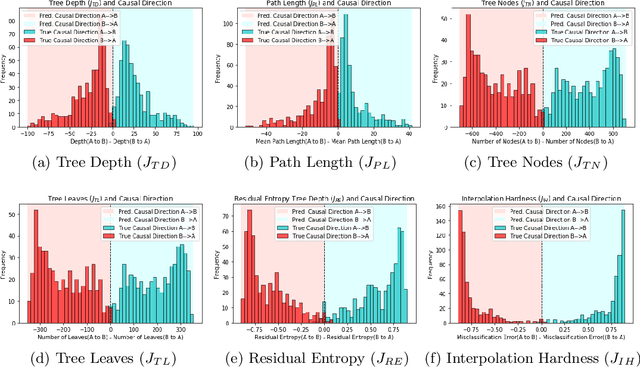
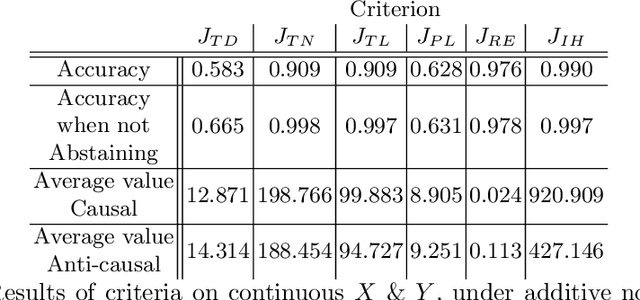
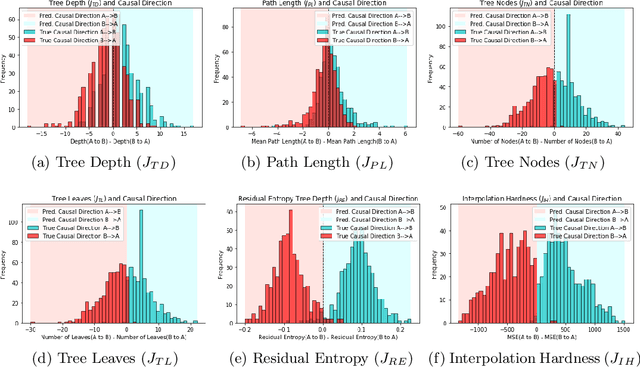
At the heart of causal structure learning from observational data lies a deceivingly simple question: given two statistically dependent random variables, which one has a causal effect on the other? This is impossible to answer using statistical dependence testing alone and requires that we make additional assumptions. We propose several fast and simple criteria for distinguishing cause and effect in pairs of discrete or continuous random variables. The intuition behind them is that predicting the effect variable using the cause variable should be `simpler' than the reverse -- different notions of `simplicity' giving rise to different criteria. We demonstrate the accuracy of the criteria on synthetic data generated under a broad family of causal mechanisms and types of noise.
* 9 Pages, 2 figures, Presented in Machine Learning for Pharma and Healthcare Applications ECML PKDD 2020 Workshop (PharML 2020)
Margin Maximization as Lossless Maximal Compression
Jan 28, 2020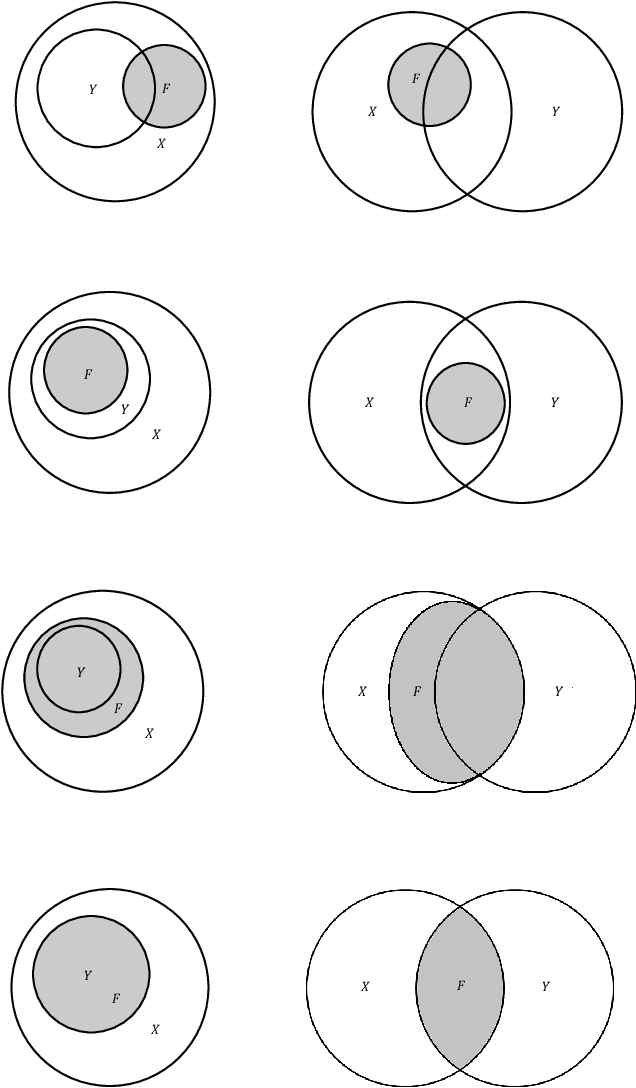
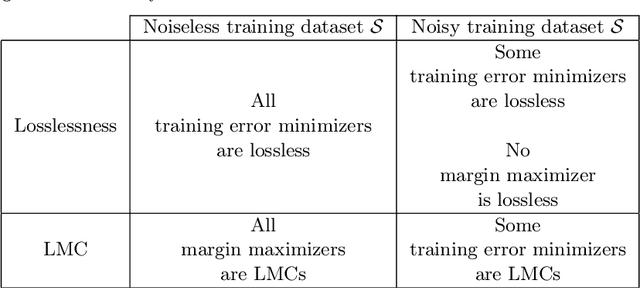

The ultimate goal of a supervised learning algorithm is to produce models constructed on the training data that can generalize well to new examples. In classification, functional margin maximization -- correctly classifying as many training examples as possible with maximal confidence --has been known to construct models with good generalization guarantees. This work gives an information-theoretic interpretation of a margin maximizing model on a noiseless training dataset as one that achieves lossless maximal compression of said dataset -- i.e. extracts from the features all the useful information for predicting the label and no more. The connection offers new insights on generalization in supervised machine learning, showing margin maximization as a special case (that of classification) of a more general principle and explains the success and potential limitations of popular learning algorithms like gradient boosting. We support our observations with theoretical arguments and empirical evidence and identify interesting directions for future work.
Better Boosting with Bandits for Online Learning
Jan 16, 2020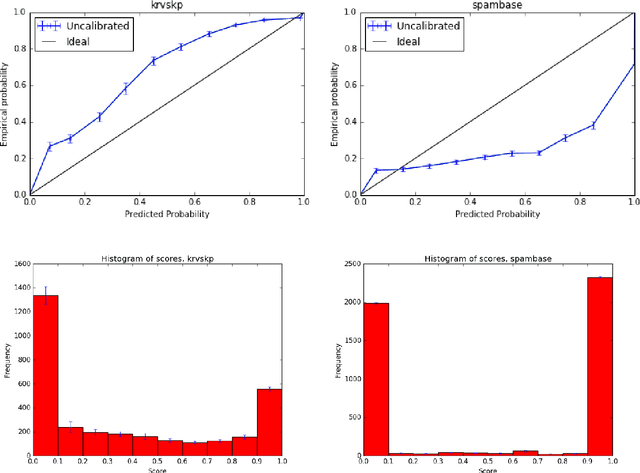
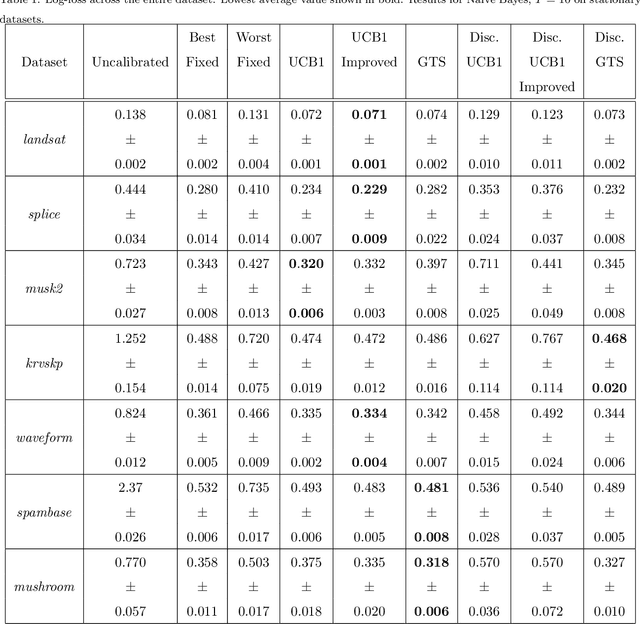
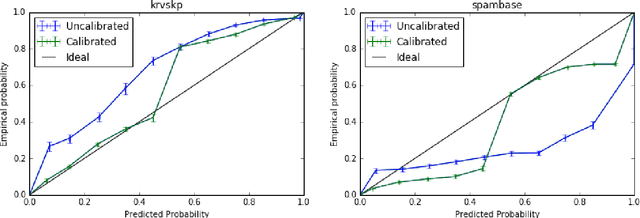
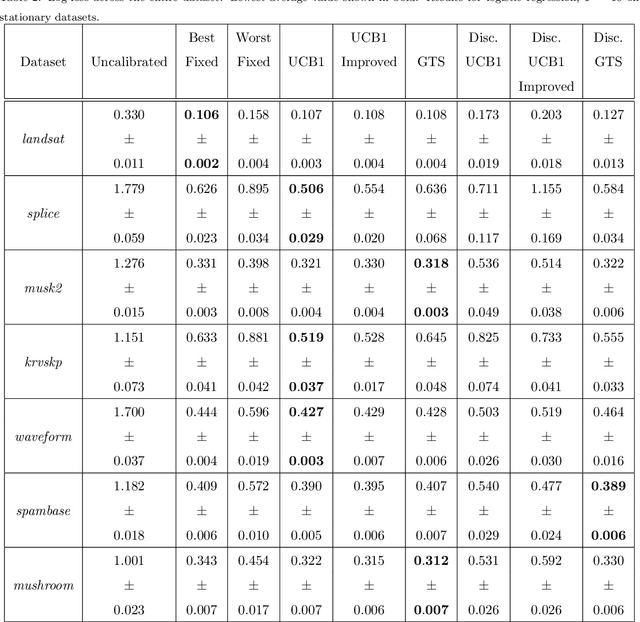
Probability estimates generated by boosting ensembles are poorly calibrated because of the margin maximization nature of the algorithm. The outputs of the ensemble need to be properly calibrated before they can be used as probability estimates. In this work, we demonstrate that online boosting is also prone to producing distorted probability estimates. In batch learning, calibration is achieved by reserving part of the training data for training the calibrator function. In the online setting, a decision needs to be made on each round: shall the new example(s) be used to update the parameters of the ensemble or those of the calibrator. We proceed to resolve this decision with the aid of bandit optimization algorithms. We demonstrate superior performance to uncalibrated and naively-calibrated on-line boosting ensembles in terms of probability estimation. Our proposed mechanism can be easily adapted to other tasks(e.g. cost-sensitive classification) and is robust to the choice of hyperparameters of both the calibrator and the ensemble.