 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExoMiner: A Highly Accurate and Explainable Deep Learning Classifier that Validates 301 New Exoplanets
Dec 08, 2021
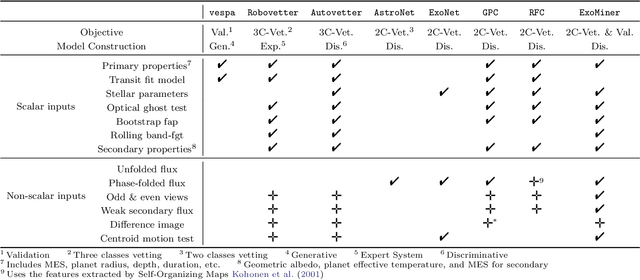
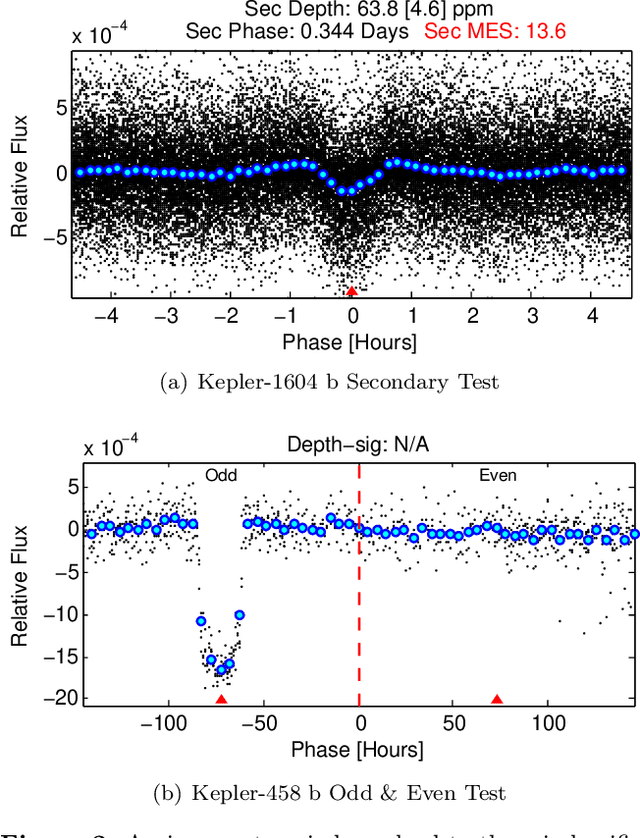
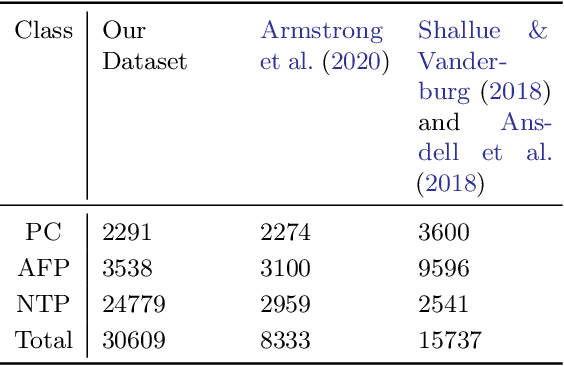
The kepler and TESS missions have generated over 100,000 potential transit signals that must be processed in order to create a catalog of planet candidates. During the last few years, there has been a growing interest in using machine learning to analyze these data in search of new exoplanets. Different from the existing machine learning works, ExoMiner, the proposed deep learning classifier in this work, mimics how domain experts examine diagnostic tests to vet a transit signal. ExoMiner is a highly accurate, explainable, and robust classifier that 1) allows us to validate 301 new exoplanets from the MAST Kepler Archive and 2) is general enough to be applied across missions such as the on-going TESS mission. We perform an extensive experimental study to verify that ExoMiner is more reliable and accurate than the existing transit signal classifiers in terms of different classification and ranking metrics. For example, for a fixed precision value of 99%, ExoMiner retrieves 93.6% of all exoplanets in the test set (i.e., recall=0.936) while this rate is 76.3% for the best existing classifier. Furthermore, the modular design of ExoMiner favors its explainability. We introduce a simple explainability framework that provides experts with feedback on why ExoMiner classifies a transit signal into a specific class label (e.g., planet candidate or not planet candidate).
Better Boosting with Bandits for Online Learning
Jan 16, 2020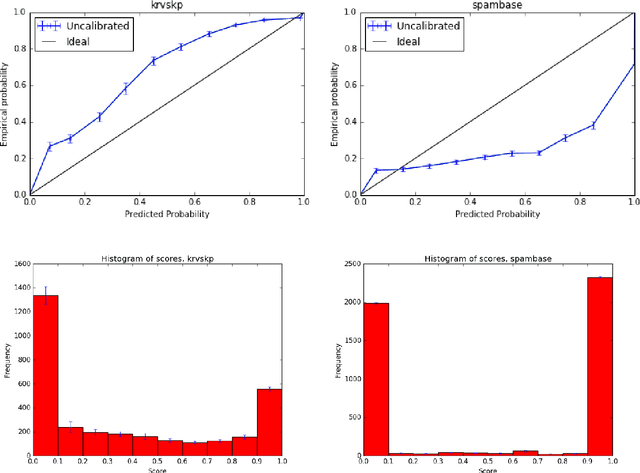
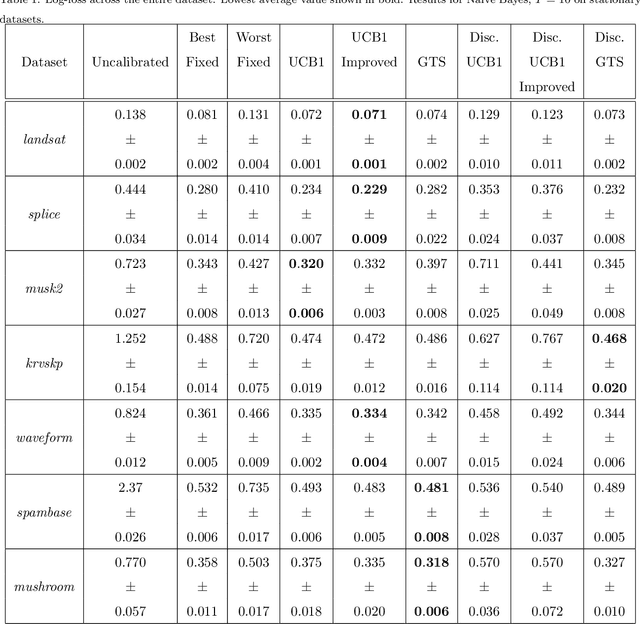
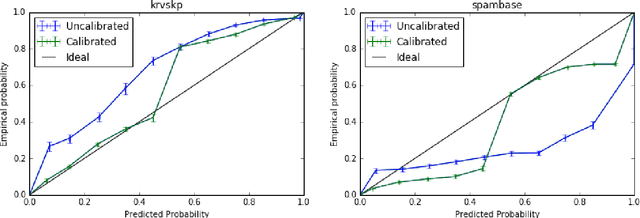
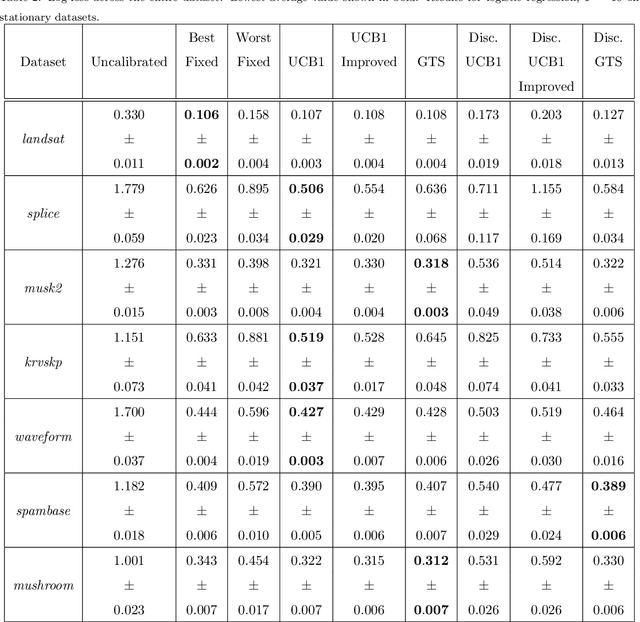
Probability estimates generated by boosting ensembles are poorly calibrated because of the margin maximization nature of the algorithm. The outputs of the ensemble need to be properly calibrated before they can be used as probability estimates. In this work, we demonstrate that online boosting is also prone to producing distorted probability estimates. In batch learning, calibration is achieved by reserving part of the training data for training the calibrator function. In the online setting, a decision needs to be made on each round: shall the new example(s) be used to update the parameters of the ensemble or those of the calibrator. We proceed to resolve this decision with the aid of bandit optimization algorithms. We demonstrate superior performance to uncalibrated and naively-calibrated on-line boosting ensembles in terms of probability estimation. Our proposed mechanism can be easily adapted to other tasks(e.g. cost-sensitive classification) and is robust to the choice of hyperparameters of both the calibrator and the ensemble.