 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExoMiner++ 2.0: Vetting TESS Full-Frame Image Transit Signals
Jan 21, 2026The Transiting Exoplanet Survey Satellite (TESS) Full-Frame Images (FFIs) provide photometric time series for millions of stars, enabling transit searches beyond the limited set of pre-selected 2-minute targets. However, FFIs present additional challenges for transit identification and vetting. In this work, we apply ExoMiner++ 2.0, an adaptation of the ExoMiner++ framework originally developed for TESS 2-minute data, to FFI light curves. The model is used to perform large-scale planet versus non-planet classification of Threshold Crossing Events across the sectors analyzed in this study. We construct a uniform vetting catalog of all evaluated signals and assess model performance under different observing conditions. We find that ExoMiner++ 2.0 generalizes effectively to the FFI domain, providing robust discrimination between planetary signals, astrophysical false positives, and instrumental artifacts despite the limitations inherent to longer cadence data. This work extends the applicability of ExoMiner++ to the full TESS dataset and supports future population studies and follow-up prioritization.
Multiplicity Boost Of Transit Signal Classifiers: Validation of 69 New Exoplanets Using The Multiplicity Boost of ExoMiner
May 05, 2023Most existing exoplanets are discovered using validation techniques rather than being confirmed by complementary observations. These techniques generate a score that is typically the probability of the transit signal being an exoplanet (y(x)=exoplanet) given some information related to that signal (represented by x). Except for the validation technique in Rowe et al. (2014) that uses multiplicity information to generate these probability scores, the existing validation techniques ignore the multiplicity boost information. In this work, we introduce a framework with the following premise: given an existing transit signal vetter (classifier), improve its performance using multiplicity information. We apply this framework to several existing classifiers, which include vespa (Morton et al. 2016), Robovetter (Coughlin et al. 2017), AstroNet (Shallue & Vanderburg 2018), ExoNet (Ansdel et al. 2018), GPC and RFC (Armstrong et al. 2020), and ExoMiner (Valizadegan et al. 2022), to support our claim that this framework is able to improve the performance of a given classifier. We then use the proposed multiplicity boost framework for ExoMiner V1.2, which addresses some of the shortcomings of the original ExoMiner classifier (Valizadegan et al. 2022), and validate 69 new exoplanets for systems with multiple KOIs from the Kepler catalog.
ExoMiner: A Highly Accurate and Explainable Deep Learning Classifier that Validates 301 New Exoplanets
Dec 08, 2021
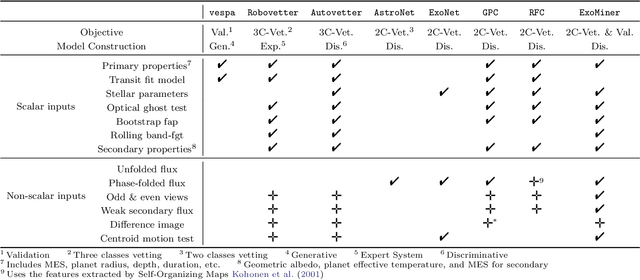
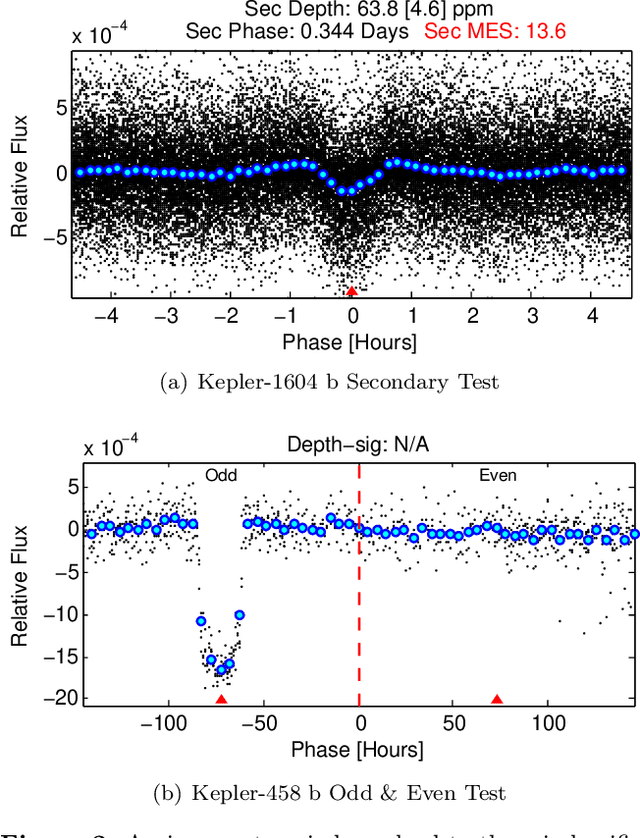
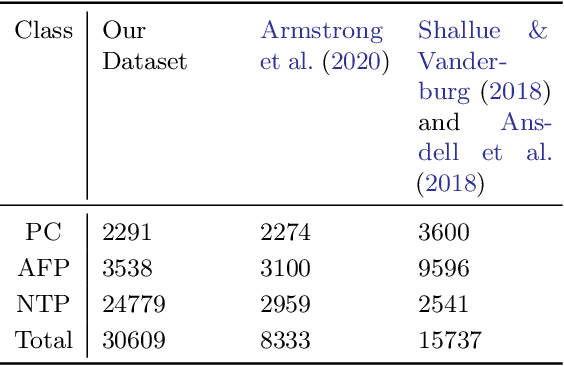
The kepler and TESS missions have generated over 100,000 potential transit signals that must be processed in order to create a catalog of planet candidates. During the last few years, there has been a growing interest in using machine learning to analyze these data in search of new exoplanets. Different from the existing machine learning works, ExoMiner, the proposed deep learning classifier in this work, mimics how domain experts examine diagnostic tests to vet a transit signal. ExoMiner is a highly accurate, explainable, and robust classifier that 1) allows us to validate 301 new exoplanets from the MAST Kepler Archive and 2) is general enough to be applied across missions such as the on-going TESS mission. We perform an extensive experimental study to verify that ExoMiner is more reliable and accurate than the existing transit signal classifiers in terms of different classification and ranking metrics. For example, for a fixed precision value of 99%, ExoMiner retrieves 93.6% of all exoplanets in the test set (i.e., recall=0.936) while this rate is 76.3% for the best existing classifier. Furthermore, the modular design of ExoMiner favors its explainability. We introduce a simple explainability framework that provides experts with feedback on why ExoMiner classifies a transit signal into a specific class label (e.g., planet candidate or not planet candidate).
Algorithms and Statistical Models for Scientific Discovery in the Petabyte Era
Nov 05, 2019The field of astronomy has arrived at a turning point in terms of size and complexity of both datasets and scientific collaboration. Commensurately, algorithms and statistical models have begun to adapt --- e.g., via the onset of artificial intelligence --- which itself presents new challenges and opportunities for growth. This white paper aims to offer guidance and ideas for how we can evolve our technical and collaborative frameworks to promote efficient algorithmic development and take advantage of opportunities for scientific discovery in the petabyte era. We discuss challenges for discovery in large and complex data sets; challenges and requirements for the next stage of development of statistical methodologies and algorithmic tool sets; how we might change our paradigms of collaboration and education; and the ethical implications of scientists' contributions to widely applicable algorithms and computational modeling. We start with six distinct recommendations that are supported by the commentary following them. This white paper is related to a larger corpus of effort that has taken place within and around the Petabytes to Science Workshops (https://petabytestoscience.github.io/).