 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExoMiner++ 2.0: Vetting TESS Full-Frame Image Transit Signals
Jan 21, 2026The Transiting Exoplanet Survey Satellite (TESS) Full-Frame Images (FFIs) provide photometric time series for millions of stars, enabling transit searches beyond the limited set of pre-selected 2-minute targets. However, FFIs present additional challenges for transit identification and vetting. In this work, we apply ExoMiner++ 2.0, an adaptation of the ExoMiner++ framework originally developed for TESS 2-minute data, to FFI light curves. The model is used to perform large-scale planet versus non-planet classification of Threshold Crossing Events across the sectors analyzed in this study. We construct a uniform vetting catalog of all evaluated signals and assess model performance under different observing conditions. We find that ExoMiner++ 2.0 generalizes effectively to the FFI domain, providing robust discrimination between planetary signals, astrophysical false positives, and instrumental artifacts despite the limitations inherent to longer cadence data. This work extends the applicability of ExoMiner++ to the full TESS dataset and supports future population studies and follow-up prioritization.
TelescopeML -- I. An End-to-End Python Package for Interpreting Telescope Datasets through Training Machine Learning Models, Generating Statistical Reports, and Visualizing Results
Jul 24, 2024We are on the verge of a revolutionary era in space exploration, thanks to advancements in telescopes such as the James Webb Space Telescope (\textit{JWST}). High-resolution, high signal-to-noise spectra from exoplanet and brown dwarf atmospheres have been collected over the past few decades, requiring the development of accurate and reliable pipelines and tools for their analysis. Accurately and swiftly determining the spectroscopic parameters from the observational spectra of these objects is crucial for understanding their atmospheric composition and guiding future follow-up observations. \texttt{TelescopeML} is a Python package developed to perform three main tasks: 1. Process the synthetic astronomical datasets for training a CNN model and prepare the observational dataset for later use for prediction; 2. Train a CNN model by implementing the optimal hyperparameters; and 3. Deploy the trained CNN models on the actual observational data to derive the output spectroscopic parameters.
* Please find the accepted paper with complete reference list at https://joss.theoj.org/papers/10.21105/joss.06346
Multiplicity Boost Of Transit Signal Classifiers: Validation of 69 New Exoplanets Using The Multiplicity Boost of ExoMiner
May 05, 2023Most existing exoplanets are discovered using validation techniques rather than being confirmed by complementary observations. These techniques generate a score that is typically the probability of the transit signal being an exoplanet (y(x)=exoplanet) given some information related to that signal (represented by x). Except for the validation technique in Rowe et al. (2014) that uses multiplicity information to generate these probability scores, the existing validation techniques ignore the multiplicity boost information. In this work, we introduce a framework with the following premise: given an existing transit signal vetter (classifier), improve its performance using multiplicity information. We apply this framework to several existing classifiers, which include vespa (Morton et al. 2016), Robovetter (Coughlin et al. 2017), AstroNet (Shallue & Vanderburg 2018), ExoNet (Ansdel et al. 2018), GPC and RFC (Armstrong et al. 2020), and ExoMiner (Valizadegan et al. 2022), to support our claim that this framework is able to improve the performance of a given classifier. We then use the proposed multiplicity boost framework for ExoMiner V1.2, which addresses some of the shortcomings of the original ExoMiner classifier (Valizadegan et al. 2022), and validate 69 new exoplanets for systems with multiple KOIs from the Kepler catalog.
ExoMiner: A Highly Accurate and Explainable Deep Learning Classifier that Validates 301 New Exoplanets
Dec 08, 2021
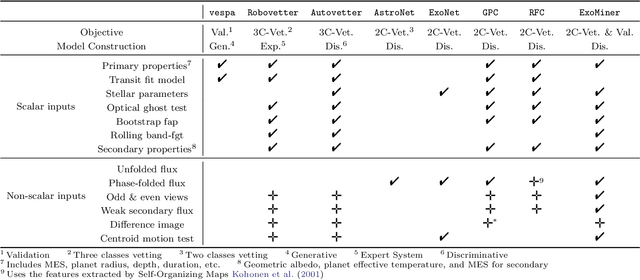
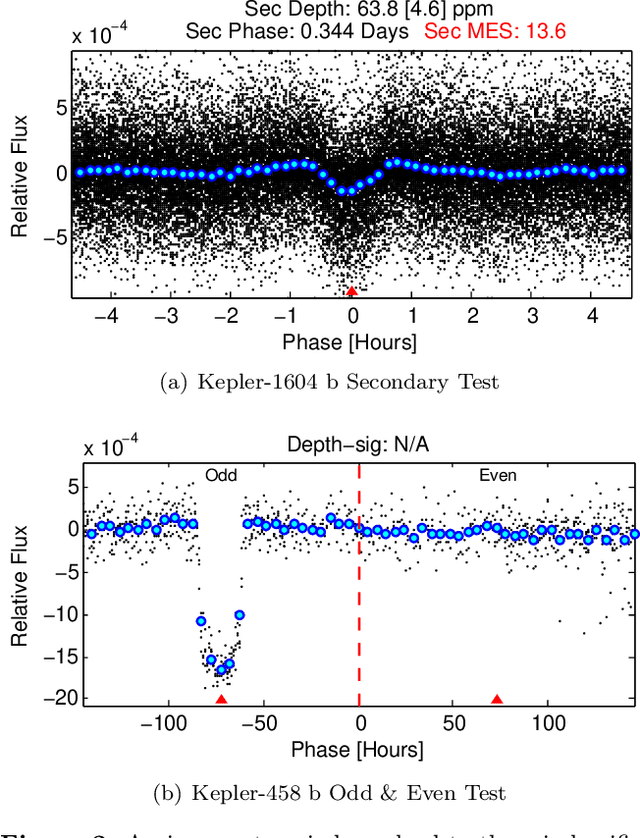
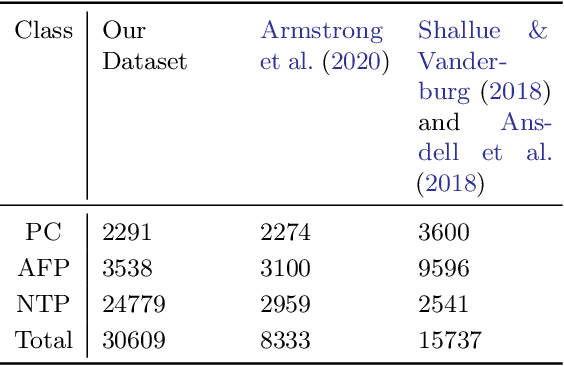
The kepler and TESS missions have generated over 100,000 potential transit signals that must be processed in order to create a catalog of planet candidates. During the last few years, there has been a growing interest in using machine learning to analyze these data in search of new exoplanets. Different from the existing machine learning works, ExoMiner, the proposed deep learning classifier in this work, mimics how domain experts examine diagnostic tests to vet a transit signal. ExoMiner is a highly accurate, explainable, and robust classifier that 1) allows us to validate 301 new exoplanets from the MAST Kepler Archive and 2) is general enough to be applied across missions such as the on-going TESS mission. We perform an extensive experimental study to verify that ExoMiner is more reliable and accurate than the existing transit signal classifiers in terms of different classification and ranking metrics. For example, for a fixed precision value of 99%, ExoMiner retrieves 93.6% of all exoplanets in the test set (i.e., recall=0.936) while this rate is 76.3% for the best existing classifier. Furthermore, the modular design of ExoMiner favors its explainability. We introduce a simple explainability framework that provides experts with feedback on why ExoMiner classifies a transit signal into a specific class label (e.g., planet candidate or not planet candidate).
Relative Comparison Kernel Learning with Auxiliary Kernels
Apr 15, 2014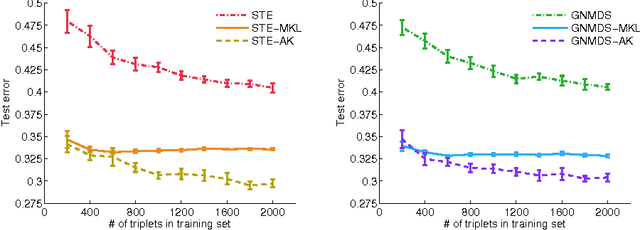
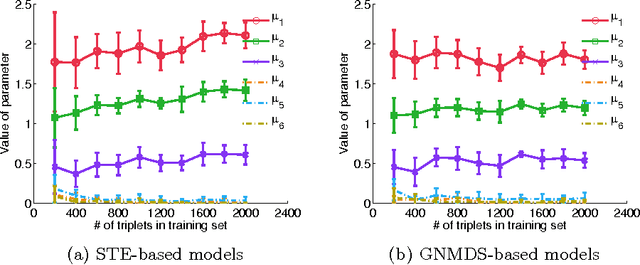
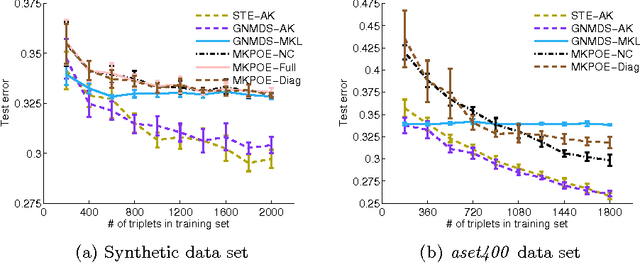
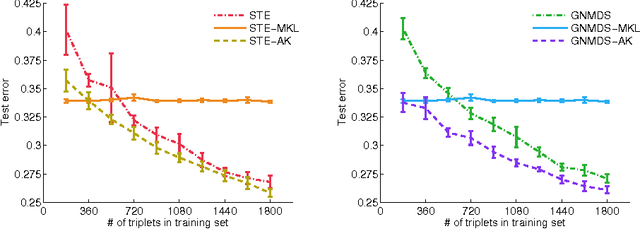
In this work we consider the problem of learning a positive semidefinite kernel matrix from relative comparisons of the form: "object A is more similar to object B than it is to C", where comparisons are given by humans. Existing solutions to this problem assume many comparisons are provided to learn a high quality kernel. However, this can be considered unrealistic for many real-world tasks since relative assessments require human input, which is often costly or difficult to obtain. Because of this, only a limited number of these comparisons may be provided. In this work, we explore methods for aiding the process of learning a kernel with the help of auxiliary kernels built from more easily extractable information regarding the relationships among objects. We propose a new kernel learning approach in which the target kernel is defined as a conic combination of auxiliary kernels and a kernel whose elements are learned directly. We formulate a convex optimization to solve for this target kernel that adds only minor overhead to methods that use no auxiliary information. Empirical results show that in the presence of few training relative comparisons, our method can learn kernels that generalize to more out-of-sample comparisons than methods that do not utilize auxiliary information, as well as similar methods that learn metrics over objects.