 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized Event Prediction for Electronic Health Records
Aug 21, 2023



Clinical event sequences consist of hundreds of clinical events that represent records of patient care in time. Developing accurate predictive models of such sequences is of a great importance for supporting a variety of models for interpreting/classifying the current patient condition, or predicting adverse clinical events and outcomes, all aimed to improve patient care. One important challenge of learning predictive models of clinical sequences is their patient-specific variability. Based on underlying clinical conditions, each patient's sequence may consist of different sets of clinical events (observations, lab results, medications, procedures). Hence, simple population-wide models learned from event sequences for many different patients may not accurately predict patient-specific dynamics of event sequences and their differences. To address the problem, we propose and investigate multiple new event sequence prediction models and methods that let us better adjust the prediction for individual patients and their specific conditions. The methods developed in this work pursue refinement of population-wide models to subpopulations, self-adaptation, and a meta-level model switching that is able to adaptively select the model with the best chance to support the immediate prediction. We analyze and test the performance of these models on clinical event sequences of patients in MIMIC-III database.
* arXiv admin note: text overlap with arXiv:2104.01787
Learning to Adapt Clinical Sequences with Residual Mixture of Experts
Apr 06, 2022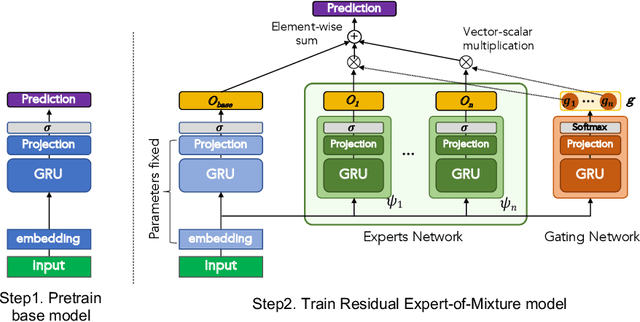



Clinical event sequences in Electronic Health Records (EHRs) record detailed information about the patient condition and patient care as they occur in time. Recent years have witnessed increased interest of machine learning community in developing machine learning models solving different types of problems defined upon information in EHRs. More recently, neural sequential models, such as RNN and LSTM, became popular and widely applied models for representing patient sequence data and for predicting future events or outcomes based on such data. However, a single neural sequential model may not properly represent complex dynamics of all patients and the differences in their behaviors. In this work, we aim to alleviate this limitation by refining a one-fits-all model using a Mixture-of-Experts (MoE) architecture. The architecture consists of multiple (expert) RNN models covering patient sub-populations and refining the predictions of the base model. That is, instead of training expert RNN models from scratch we define them on the residual signal that attempts to model the differences from the population-wide model. The heterogeneity of various patient sequences is modeled through multiple experts that consist of RNN. Particularly, instead of directly training MoE from scratch, we augment MoE based on the prediction signal from pretrained base GRU model. With this way, the mixture of experts can provide flexible adaptation to the (limited) predictive power of the single base RNN model. We experiment with the newly proposed model on real-world EHRs data and the multivariate clinical event prediction task. We implement RNN using Gated Recurrent Units (GRU). We show 4.1% gain on AUPRC statistics compared to a single RNN prediction.
Improving Prediction of Low-Prior Clinical Events with Simultaneous General Patient-State Representation Learning
Jun 28, 2021

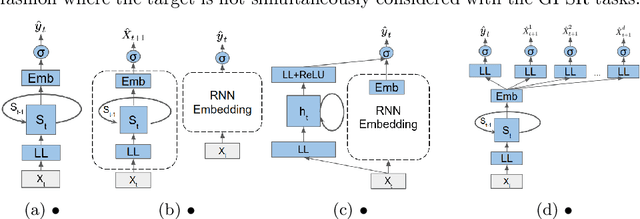

Low-prior targets are common among many important clinical events, which introduces the challenge of having enough data to support learning of their predictive models. Many prior works have addressed this problem by first building a general patient-state representation model, and then adapting it to a new low-prior prediction target. In this schema, there is potential for the predictive performance to be hindered by the misalignment between the general patient-state model and the target task. To overcome this challenge, we propose a new method that simultaneously optimizes a shared model through multi-task learning of both the low-prior supervised target and general purpose patient-state representation (GPSR). More specifically, our method improves prediction performance of a low-prior task by jointly optimizing a shared model that combines the loss of the target event and a broad range of generic clinical events. We study the approach in the context of Recurrent Neural Networks (RNNs). Through extensive experiments on multiple clinical event targets using MIMIC-III data, we show that the inclusion of general patient-state representation tasks during model training improves the prediction of individual low-prior targets.
Neural Clinical Event Sequence Prediction through Personalized Online Adaptive Learning
Apr 06, 2021
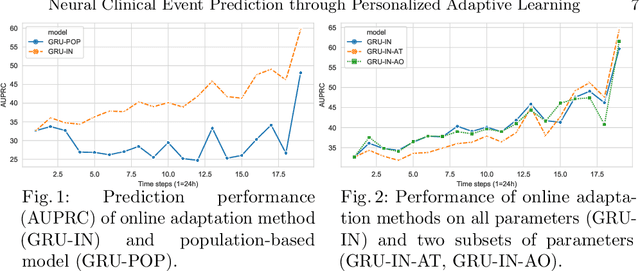
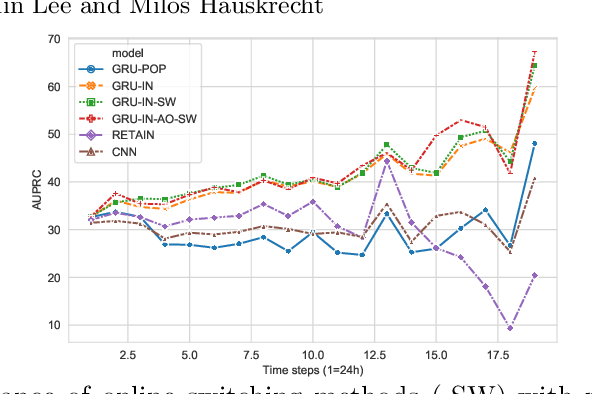
Clinical event sequences consist of thousands of clinical events that represent records of patient care in time. Developing accurate prediction models for such sequences is of a great importance for defining representations of a patient state and for improving patient care. One important challenge of learning a good predictive model of clinical sequences is patient-specific variability. Based on underlying clinical complications, each patient's sequence may consist of different sets of clinical events. However, population-based models learned from such sequences may not accurately predict patient-specific dynamics of event sequences. To address the problem, we develop a new adaptive event sequence prediction framework that learns to adjust its prediction for individual patients through an online model update.
Contextual Outlier Detection in Continuous-Time Event Sequences
Dec 19, 2019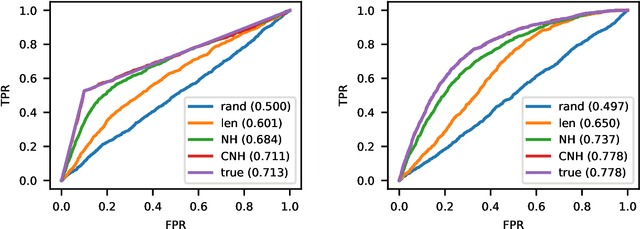
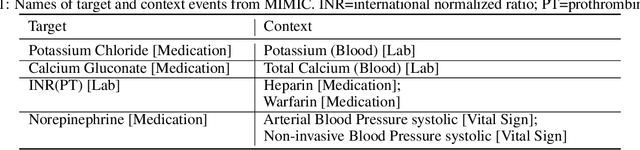
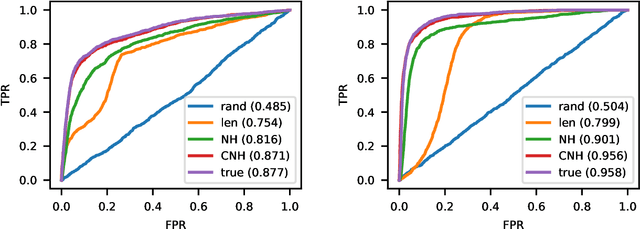
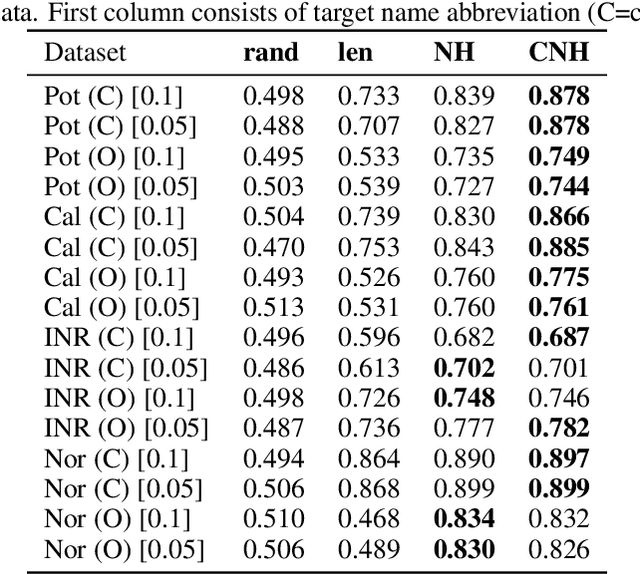
Continuous-time event sequences represent discrete events occurring in continuous time. Such sequences arise frequently in real-life and cover a wide variety of natural events, such as earthquakes, or events corresponding to human actions, such as medical administrations. Usually we expect the event sequences to follow some regular pattern over time. However, sometimes these regular patterns may be interrupted by unexpected absence or unexpected occurrences of events. Identification of these unexpected cases can be very important as they may point to abnormal situations that need human attention. In this work, we study and develop methods for detecting outliers in continuous-time event sequences, including unexpected absence and unexpected occurrences of events. Since the patterns that event sequences tend to follow may change in different contexts, we develop outlier detection methods based on point processes that take into account different contexts. Our outlier scoring methods are based on Bayesian decision theory and hypothesis testing with theoretical guarantees. To test the performance of the methods, we conduct experiments on both synthetic data and real-world clinical data and show the effectiveness of the proposed methods.
Detection of Abnormal Input-Output Associations
Aug 03, 2017
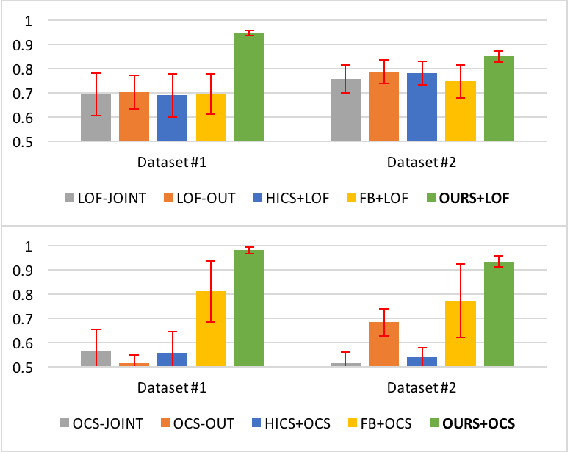
We study a novel outlier detection problem that aims to identify abnormal input-output associations in data, whose instances consist of multi-dimensional input (context) and output (responses) pairs. We present our approach that works by analyzing data in the conditional (input--output) relation space, captured by a decomposable probabilistic model. Experimental results demonstrate the ability of our approach in identifying multivariate conditional outliers.
Detecting Unusual Input-Output Associations in Multivariate Conditional Data
Dec 21, 2016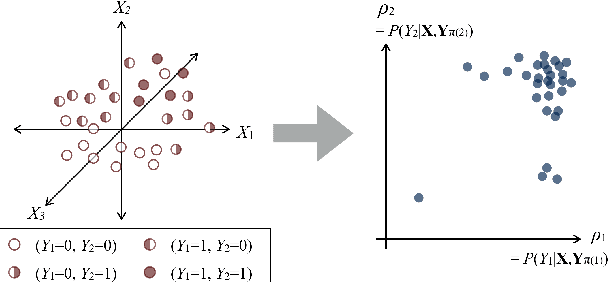
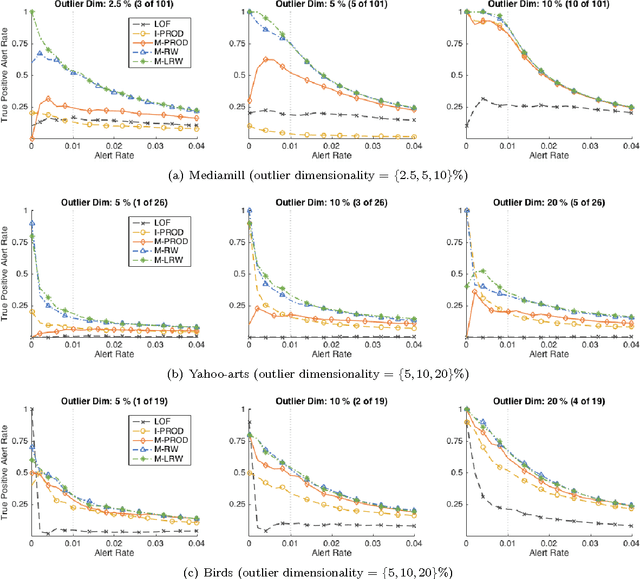
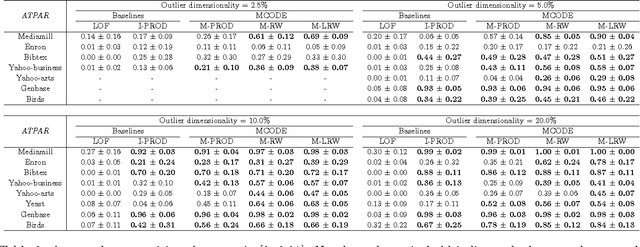
Despite tremendous progress in outlier detection research in recent years, the majority of existing methods are designed only to detect unconditional outliers that correspond to unusual data patterns expressed in the joint space of all data attributes. Such methods are not applicable when we seek to detect conditional outliers that reflect unusual responses associated with a given context or condition. This work focuses on multivariate conditional outlier detection, a special type of the conditional outlier detection problem, where data instances consist of multi-dimensional input (context) and output (responses) pairs. We present a novel outlier detection framework that identifies abnormal input-output associations in data with the help of a decomposable conditional probabilistic model that is learned from all data instances. Since components of this model can vary in their quality, we combine them with the help of weights reflecting their reliability in assessment of outliers. We study two ways of calculating the component weights: global that relies on all data, and local that relies only on instances similar to the target instance. Experimental results on data from various domains demonstrate the ability of our framework to successfully identify multivariate conditional outliers.
Active Perceptual Similarity Modeling with Auxiliary Information
Nov 06, 2015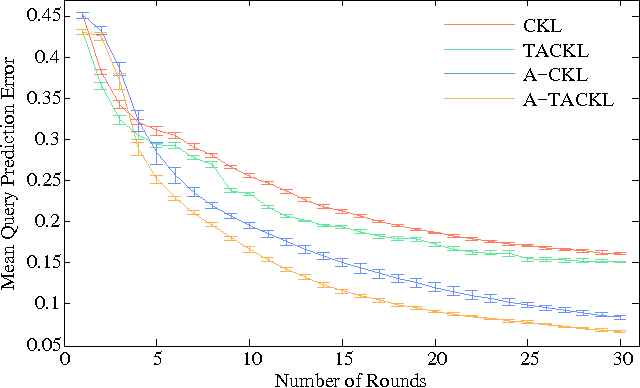
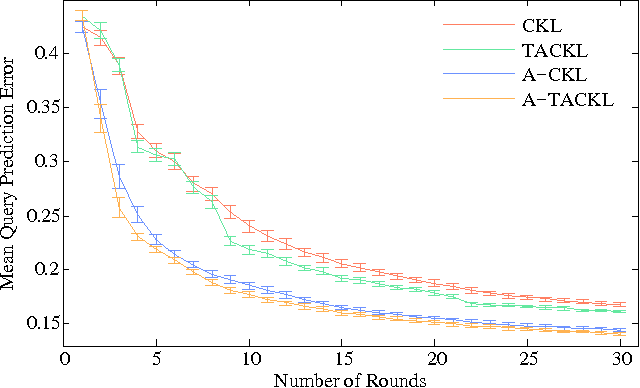
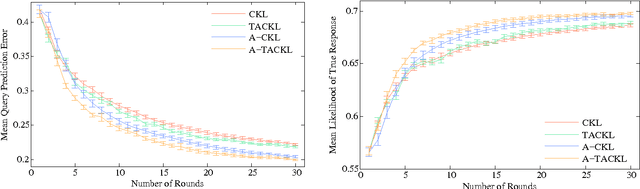

Learning a model of perceptual similarity from a collection of objects is a fundamental task in machine learning underlying numerous applications. A common way to learn such a model is from relative comparisons in the form of triplets: responses to queries of the form "Is object a more similar to b than it is to c?". If no consideration is made in the determination of which queries to ask, existing similarity learning methods can require a prohibitively large number of responses. In this work, we consider the problem of actively learning from triplets -finding which queries are most useful for learning. Different from previous active triplet learning approaches, we incorporate auxiliary information into our similarity model and introduce an active learning scheme to find queries that are informative for quickly learning both the relevant aspects of auxiliary data and the directly-learned similarity components. Compared to prior approaches, we show that we can learn just as effectively with much fewer queries. For evaluation, we introduce a new dataset of exhaustive triplet comparisons obtained from humans and demonstrate improved performance for different types of auxiliary information.
Sparse Multidimensional Patient Modeling using Auxiliary Confidence Labels
Jul 28, 2015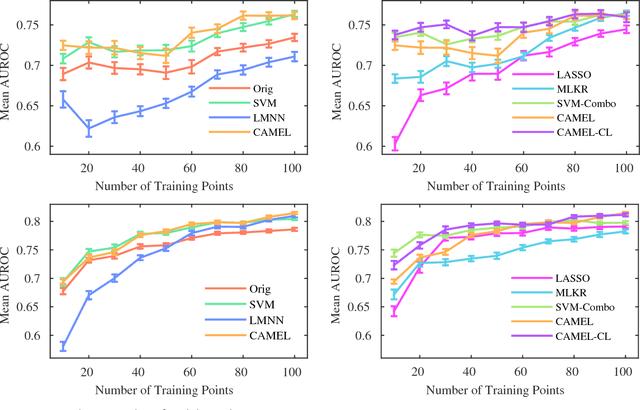



In this work, we focus on the problem of learning a classification model that performs inference on patient Electronic Health Records (EHRs). Often, a large amount of costly expert supervision is required to learn such a model. To reduce this cost, we obtain confidence labels that indicate how sure an expert is in the class labels she provides. If meaningful confidence information can be incorporated into a learning method, fewer patient instances may need to be labeled to learn an accurate model. In addition, while accuracy of predictions is important for any inference model, a model of patients must be interpretable so that clinicians can understand how the model is making decisions. To these ends, we develop a novel metric learning method called Confidence bAsed MEtric Learning (CAMEL) that supports inclusion of confidence labels, but also emphasizes interpretability in three ways. First, our method induces sparsity, thus producing simple models that use only a few features from patient EHRs. Second, CAMEL naturally produces confidence scores that can be taken into consideration when clinicians make treatment decisions. Third, the metrics learned by CAMEL induce multidimensional spaces where each dimension represents a different "factor" that clinicians can use to assess patients. In our experimental evaluation, we show on a real-world clinical data set that our CAMEL methods are able to learn models that are as or more accurate as other methods that use the same supervision. Furthermore, we show that when CAMEL uses confidence scores it is able to learn models as or more accurate as others we tested while using only 10% of the training instances. Finally, we perform qualitative assessments on the metrics learned by CAMEL and show that they identify and clearly articulate important factors in how the model performs inference.
MCODE: Multivariate Conditional Outlier Detection
May 15, 2015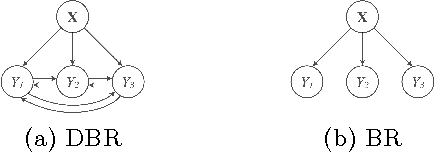

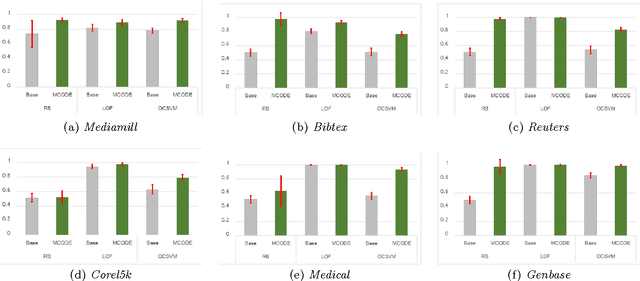
Outlier detection aims to identify unusual data instances that deviate from expected patterns. The outlier detection is particularly challenging when outliers are context dependent and when they are defined by unusual combinations of multiple outcome variable values. In this paper, we develop and study a new conditional outlier detection approach for multivariate outcome spaces that works by (1) transforming the conditional detection to the outlier detection problem in a new (unconditional) space and (2) defining outlier scores by analyzing the data in the new space. Our approach relies on the classifier chain decomposition of the multi-dimensional classification problem that lets us transform the output space into a probability vector, one probability for each dimension of the output space. Outlier scores applied to these transformed vectors are then used to detect the outliers. Experiments on multiple multi-dimensional classification problems with the different outlier injection rates show that our methodology is robust and able to successfully identify outliers when outliers are either sparse (manifested in one or very few dimensions) or dense (affecting multiple dimensions).