 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Variational Learning for Anomaly Detection in Multivariate Time Series
Aug 29, 2021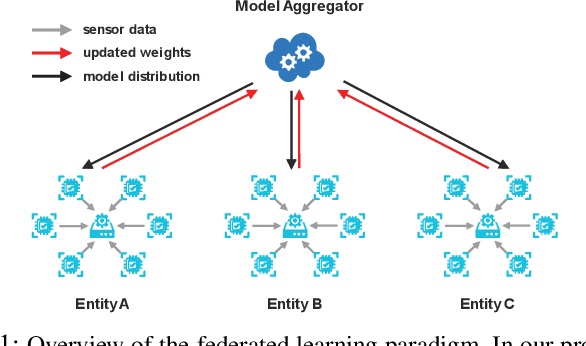
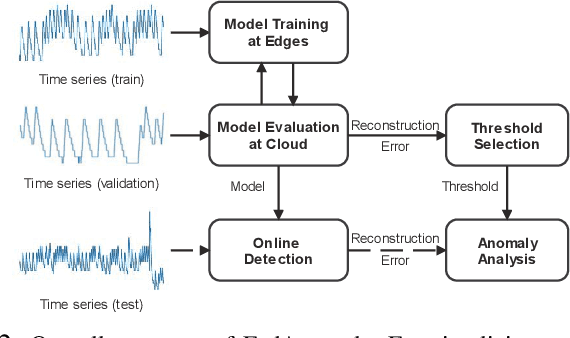
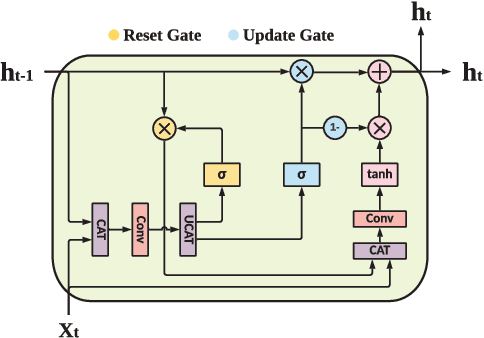
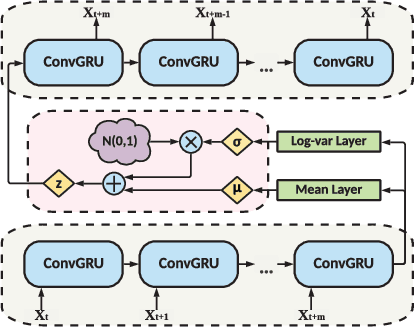
Anomaly detection has been a challenging task given high-dimensional multivariate time series data generated by networked sensors and actuators in Cyber-Physical Systems (CPS). Besides the highly nonlinear, complex, and dynamic natures of such time series, the lack of labeled data impedes data exploitation in a supervised manner and thus prevents an accurate detection of abnormal phenomenons. On the other hand, the collected data at the edge of the network is often privacy sensitive and large in quantity, which may hinder the centralized training at the main server. To tackle these issues, we propose an unsupervised time series anomaly detection framework in a federated fashion to continuously monitor the behaviors of interconnected devices within a network and alerts for abnormal incidents so that countermeasures can be taken before undesired consequences occur. To be specific, we leave the training data distributed at the edge to learn a shared Variational Autoencoder (VAE) based on Convolutional Gated Recurrent Unit (ConvGRU) model, which jointly captures feature and temporal dependencies in the multivariate time series data for representation learning and downstream anomaly detection tasks. Experiments on three real-world networked sensor datasets illustrate the advantage of our approach over other state-of-the-art models. We also conduct extensive experiments to demonstrate the effectiveness of our detection framework under non-federated and federated settings in terms of overall performance and detection latency.
Factor Analysis on Citation, Using a Combined Latent and Logistic Regression Model
Dec 02, 2019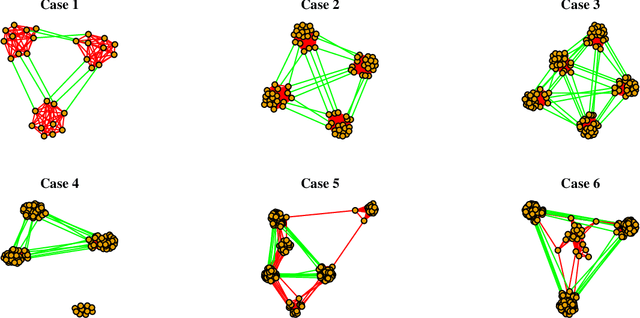
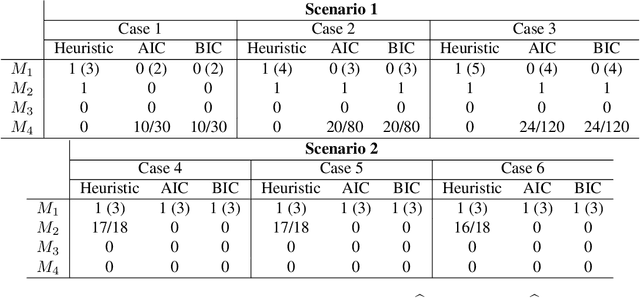
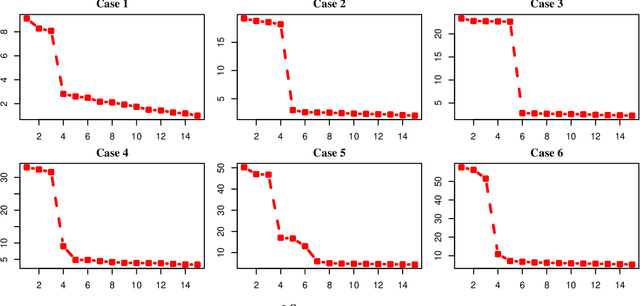
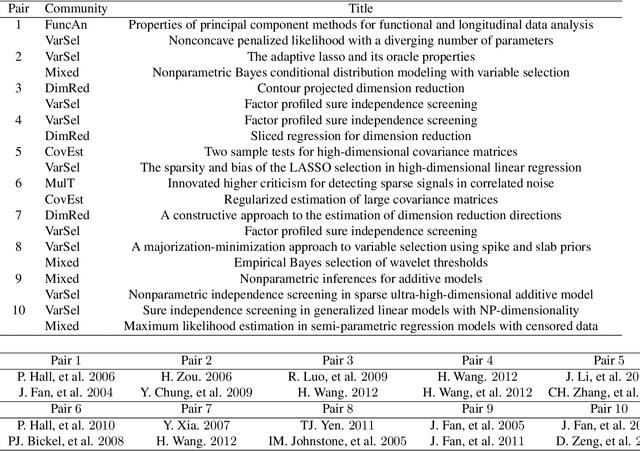
We propose a combined model, which integrates the latent factor model and the logistic regression model, for the citation network. It is noticed that neither a latent factor model nor a logistic regression model alone is sufficient to capture the structure of the data. The proposed model has a latent (i.e., factor analysis) model to represents the main technological trends (a.k.a., factors), and adds a sparse component that captures the remaining ad-hoc dependence. Parameter estimation is carried out through the construction of a joint-likelihood function of edges and properly chosen penalty terms. The convexity of the objective function allows us to develop an efficient algorithm, while the penalty terms push towards a low-dimensional latent component and a sparse graphical structure. Simulation results show that the proposed method works well in practical situations. The proposed method has been applied to a real application, which contains a citation network of statisticians (Ji and Jin, 2016). Some interesting findings are reported.
Sequential Low-Rank Change Detection
Oct 07, 2016
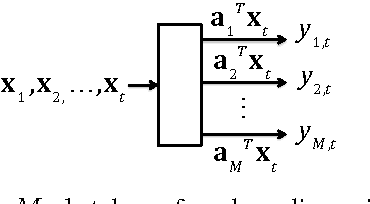
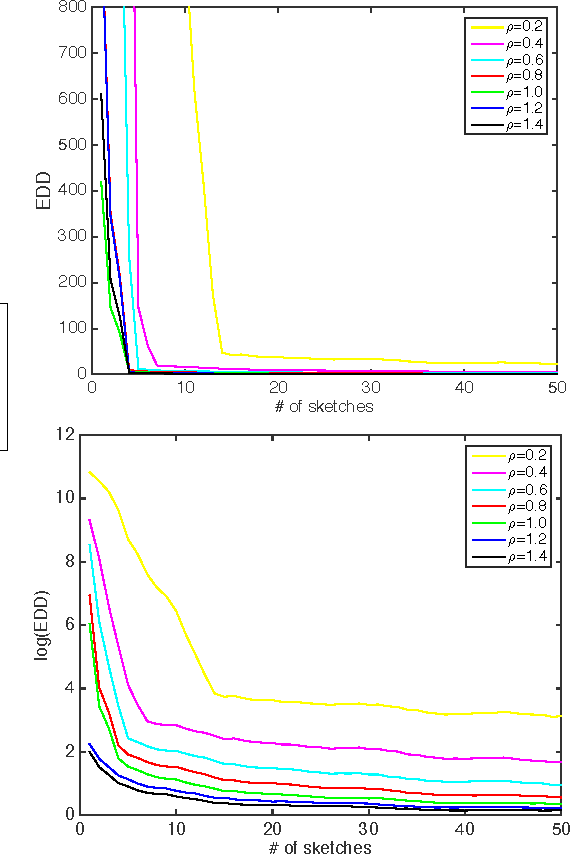
Detecting emergence of a low-rank signal from high-dimensional data is an important problem arising from many applications such as camera surveillance and swarm monitoring using sensors. We consider a procedure based on the largest eigenvalue of the sample covariance matrix over a sliding window to detect the change. To achieve dimensionality reduction, we present a sketching-based approach for rank change detection using the low-dimensional linear sketches of the original high-dimensional observations. The premise is that when the sketching matrix is a random Gaussian matrix, and the dimension of the sketching vector is sufficiently large, the rank of sample covariance matrix for these sketches equals the rank of the original sample covariance matrix with high probability. Hence, we may be able to detect the low-rank change using sample covariance matrices of the sketches without having to recover the original covariance matrix. We character the performance of the largest eigenvalue statistic in terms of the false-alarm-rate and the expected detection delay, and present an efficient online implementation via subspace tracking.
Active Perceptual Similarity Modeling with Auxiliary Information
Nov 06, 2015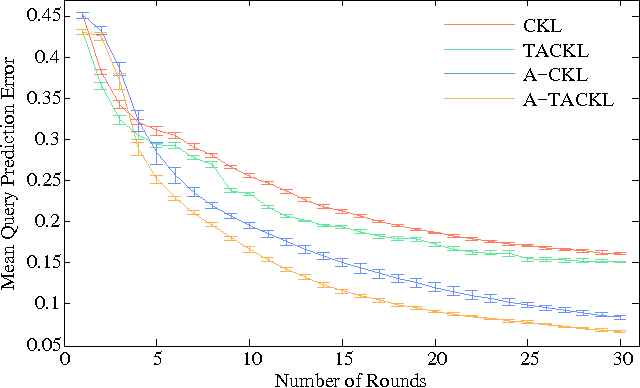
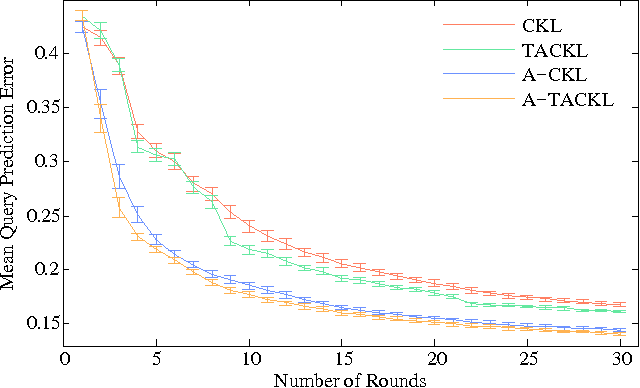
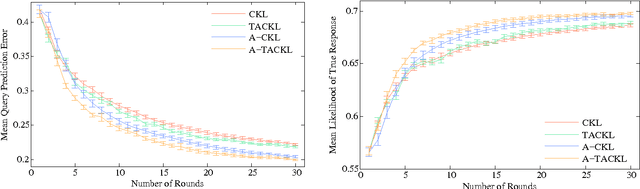

Learning a model of perceptual similarity from a collection of objects is a fundamental task in machine learning underlying numerous applications. A common way to learn such a model is from relative comparisons in the form of triplets: responses to queries of the form "Is object a more similar to b than it is to c?". If no consideration is made in the determination of which queries to ask, existing similarity learning methods can require a prohibitively large number of responses. In this work, we consider the problem of actively learning from triplets -finding which queries are most useful for learning. Different from previous active triplet learning approaches, we incorporate auxiliary information into our similarity model and introduce an active learning scheme to find queries that are informative for quickly learning both the relevant aspects of auxiliary data and the directly-learned similarity components. Compared to prior approaches, we show that we can learn just as effectively with much fewer queries. For evaluation, we introduce a new dataset of exhaustive triplet comparisons obtained from humans and demonstrate improved performance for different types of auxiliary information.