 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopology Guidance: Controlling the Outputs of Generative Models via Vector Field Topology
May 11, 2025



For domains that involve numerical simulation, it can be computationally expensive to run an ensemble of simulations spanning a parameter space of interest to a user. To this end, an attractive surrogate for simulation is the generative modeling of fields produced by an ensemble, allowing one to synthesize fields in a computationally cheap, yet accurate, manner. However, for the purposes of visual analysis, a limitation of generative models is their lack of control, as it is unclear what one should expect when sampling a field from a model. In this paper we study how to make generative models of fields more controllable, so that users can specify features of interest, in particular topological features, that they wish to see in the output. We propose topology guidance, a method for guiding the sampling process of a generative model, specifically a diffusion model, such that a topological description specified as input is satisfied in the generated output. Central to our method, we couple a coordinate-based neural network used to represent fields, with a diffusion model used for generation. We show how to use topologically-relevant signals provided by the coordinate-based network to help guide the denoising process of a diffusion model. This enables us to faithfully represent a user's specified topology, while ensuring that the output field remains within the generative data distribution. Specifically, we study 2D vector field topology, evaluating our method over an ensemble of fluid flows, where we show that generated vector fields faithfully adhere to the location, and type, of critical points over the spatial domain. We further show the benefits of our method in aiding the comparison of ensembles, allowing one to explore commonalities and differences in distributions along prescribed topological features.
See or Recall: A Sanity Check for the Role of Vision in Solving Visualization Question Answer Tasks with Multimodal LLMs
Apr 14, 2025Recent developments in multimodal large language models (MLLM) have equipped language models to reason about vision and language jointly. This permits MLLMs to both perceive and answer questions about data visualization across a variety of designs and tasks. Applying MLLMs to a broad range of visualization tasks requires us to properly evaluate their capabilities, and the most common way to conduct evaluation is through measuring a model's visualization reasoning capability, analogous to how we would evaluate human understanding of visualizations (e.g., visualization literacy). However, we found that in the context of visualization question answering (VisQA), how an MLLM perceives and reasons about visualizations can be fundamentally different from how humans approach the same problem. During the evaluation, even without visualization, the model could correctly answer a substantial portion of the visualization test questions, regardless of whether any selection options were provided. We hypothesize that the vast amount of knowledge encoded in the language model permits factual recall that supersedes the need to seek information from the visual signal. It raises concerns that the current VisQA evaluation may not fully capture the models' visualization reasoning capabilities. To address this, we propose a comprehensive sanity check framework that integrates a rule-based decision tree and a sanity check table to disentangle the effects of "seeing" (visual processing) and "recall" (reliance on prior knowledge). This validates VisQA datasets for evaluation, highlighting where models are truly "seeing", positively or negatively affected by the factual recall, or relying on inductive biases for question answering. Our study underscores the need for careful consideration in designing future visualization understanding studies when utilizing MLLMs.
CUPID: Contextual Understanding of Prompt-conditioned Image Distributions
Jun 11, 2024We present CUPID: a visualization method for the contextual understanding of prompt-conditioned image distributions. CUPID targets the visual analysis of distributions produced by modern text-to-image generative models, wherein a user can specify a scene via natural language, and the model generates a set of images, each intended to satisfy the user's description. CUPID is designed to help understand the resulting distribution, using contextual cues to facilitate analysis: objects mentioned in the prompt, novel, synthesized objects not explicitly mentioned, and their potential relationships. Central to CUPID is a novel method for visualizing high-dimensional distributions, wherein contextualized embeddings of objects, those found within images, are mapped to a low-dimensional space via density-based embeddings. We show how such embeddings allows one to discover salient styles of objects within a distribution, as well as identify anomalous, or rare, object styles. Moreover, we introduce conditional density embeddings, whereby conditioning on a given object allows one to compare object dependencies within the distribution. We employ CUPID for analyzing image distributions produced by large-scale diffusion models, where our experimental results offer insights on language misunderstanding from such models and biases in object composition, while also providing an interface for discovery of typical, or rare, synthesized scenes.
Graphical Perception of Saliency-based Model Explanations
Jun 11, 2024In recent years, considerable work has been devoted to explaining predictive, deep learning-based models, and in turn how to evaluate explanations. An important class of evaluation methods are ones that are human-centered, which typically require the communication of explanations through visualizations. And while visualization plays a critical role in perceiving and understanding model explanations, how visualization design impacts human perception of explanations remains poorly understood. In this work, we study the graphical perception of model explanations, specifically, saliency-based explanations for visual recognition models. We propose an experimental design to investigate how human perception is influenced by visualization design, wherein we study the task of alignment assessment, or whether a saliency map aligns with an object in an image. Our findings show that factors related to visualization design decisions, the type of alignment, and qualities of the saliency map all play important roles in how humans perceive saliency-based visual explanations.
Compressive Neural Representations of Volumetric Scalar Fields
Apr 11, 2021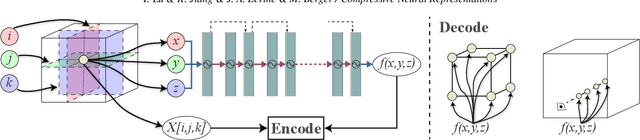
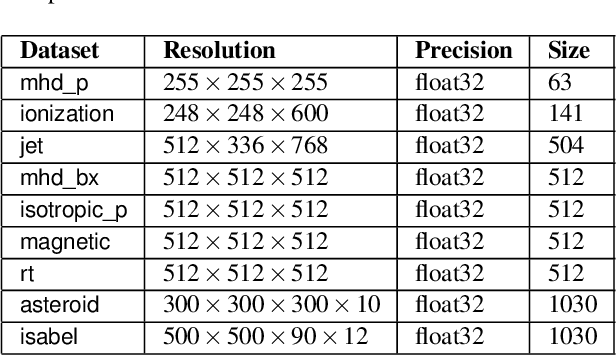
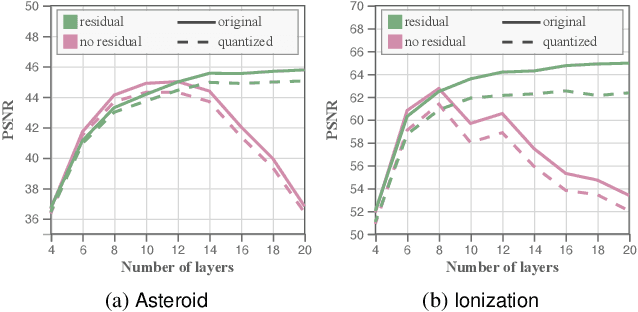
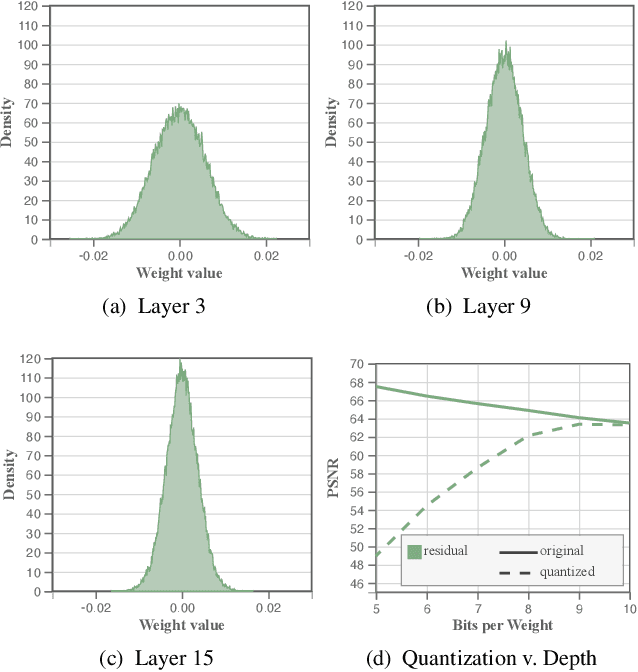
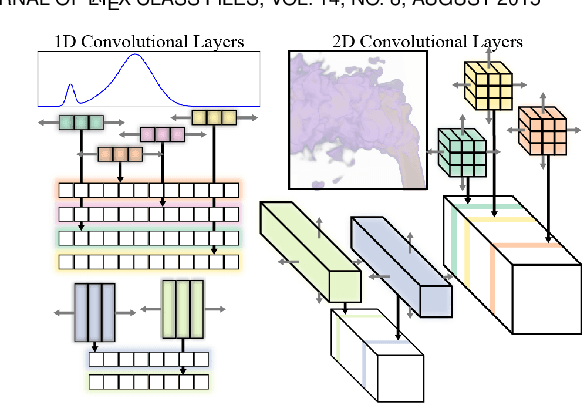
We present an approach for compressing volumetric scalar fields using implicit neural representations. Our approach represents a scalar field as a learned function, wherein a neural network maps a point in the domain to an output scalar value. By setting the number of weights of the neural network to be smaller than the input size, we achieve compressed representations of scalar fields, thus framing compression as a type of function approximation. Combined with carefully quantizing network weights, we show that this approach yields highly compact representations that outperform state-of-the-art volume compression approaches. The conceptual simplicity of our approach enables a number of benefits, such as support for time-varying scalar fields, optimizing to preserve spatial gradients, and random-access field evaluation. We study the impact of network design choices on compression performance, highlighting how simple network architectures are effective for a broad range of volumes.
Visually Analyzing and Steering Zero Shot Learning
Sep 11, 2020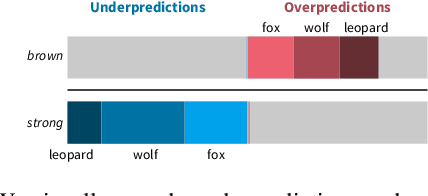
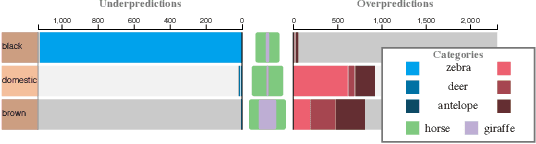
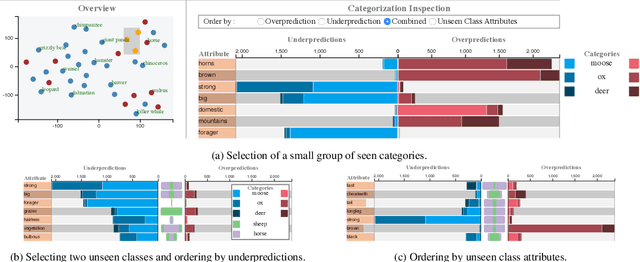
We propose a visual analytics system to help a user analyze and steer zero-shot learning models. Zero-shot learning has emerged as a viable scenario for categorizing data that consists of no labeled examples, and thus a promising approach to minimize data annotation from humans. However, it is challenging to understand where zero-shot learning fails, the cause of such failures, and how a user can modify the model to prevent such failures. Our visualization system is designed to help users diagnose and understand mispredictions in such models, so that they may gain insight on the behavior of a model when applied to data associated with categories not seen during training. Through usage scenarios, we highlight how our system can help a user improve performance in zero-shot learning.
Visually Analyzing Contextualized Embeddings
Sep 05, 2020

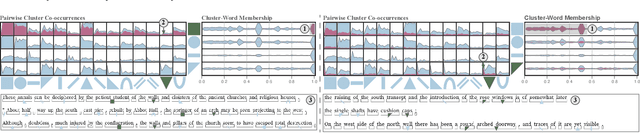
In this paper we introduce a method for visually analyzing contextualized embeddings produced by deep neural network-based language models. Our approach is inspired by linguistic probes for natural language processing, where tasks are designed to probe language models for linguistic structure, such as parts-of-speech and named entities. These approaches are largely confirmatory, however, only enabling a user to test for information known a priori. In this work, we eschew supervised probing tasks, and advocate for unsupervised probes, coupled with visual exploration techniques, to assess what is learned by language models. Specifically, we cluster contextualized embeddings produced from a large text corpus, and introduce a visualization design based on this clustering and textual structure - cluster co-occurrences, cluster spans, and cluster-word membership - to help elicit the functionality of, and relationship between, individual clusters. User feedback highlights the benefits of our design in discovering different types of linguistic structures.
Attention Flows: Analyzing and Comparing Attention Mechanisms in Language Models
Sep 03, 2020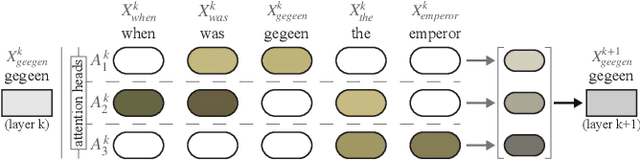
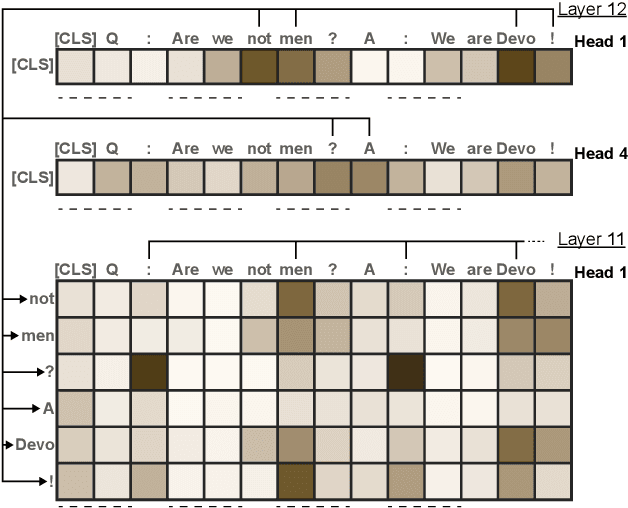
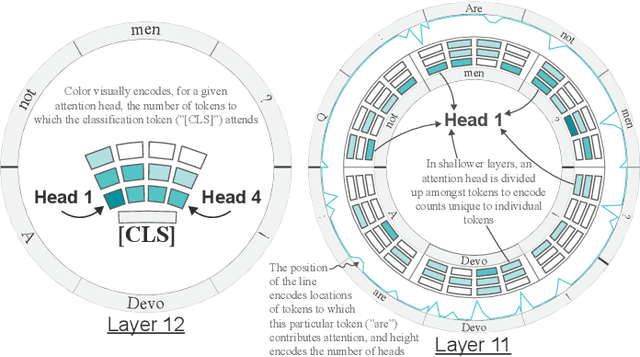
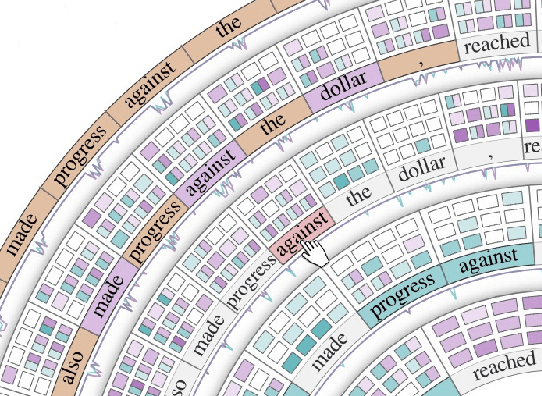
Advances in language modeling have led to the development of deep attention-based models that are performant across a wide variety of natural language processing (NLP) problems. These language models are typified by a pre-training process on large unlabeled text corpora and subsequently fine-tuned for specific tasks. Although considerable work has been devoted to understanding the attention mechanisms of pre-trained models, it is less understood how a model's attention mechanisms change when trained for a target NLP task. In this paper, we propose a visual analytics approach to understanding fine-tuning in attention-based language models. Our visualization, Attention Flows, is designed to support users in querying, tracing, and comparing attention within layers, across layers, and amongst attention heads in Transformer-based language models. To help users gain insight on how a classification decision is made, our design is centered on depicting classification-based attention at the deepest layer and how attention from prior layers flows throughout words in the input. Attention Flows supports the analysis of a single model, as well as the visual comparison between pre-trained and fine-tuned models via their similarities and differences. We use Attention Flows to study attention mechanisms in various sentence understanding tasks and highlight how attention evolves to address the nuances of solving these tasks.
A Generative Model for Volume Rendering
Oct 26, 2017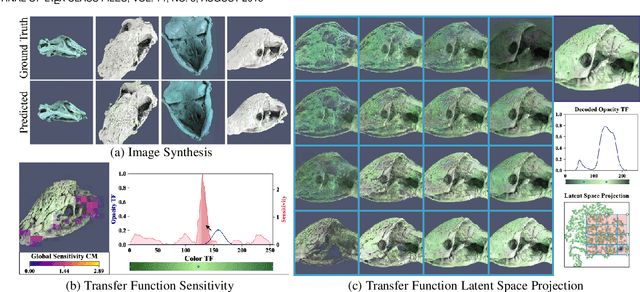

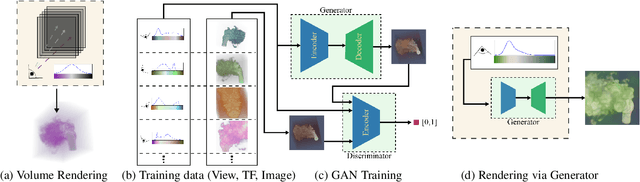
We present a technique to synthesize and analyze volume-rendered images using generative models. We use the Generative Adversarial Network (GAN) framework to compute a model from a large collection of volume renderings, conditioned on (1) viewpoint and (2) transfer functions for opacity and color. Our approach facilitates tasks for volume analysis that are challenging to achieve using existing rendering techniques such as ray casting or texture-based methods. We show how to guide the user in transfer function editing by quantifying expected change in the output image. Additionally, the generative model transforms transfer functions into a view-invariant latent space specifically designed to synthesize volume-rendered images. We use this space directly for rendering, enabling the user to explore the space of volume-rendered images. As our model is independent of the choice of volume rendering process, we show how to analyze volume-rendered images produced by direct and global illumination lighting, for a variety of volume datasets.
Active Perceptual Similarity Modeling with Auxiliary Information
Nov 06, 2015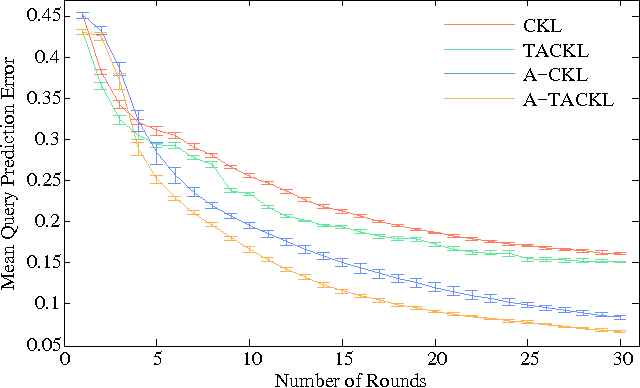
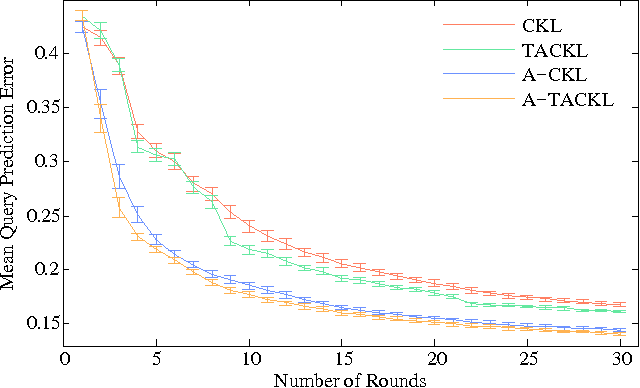
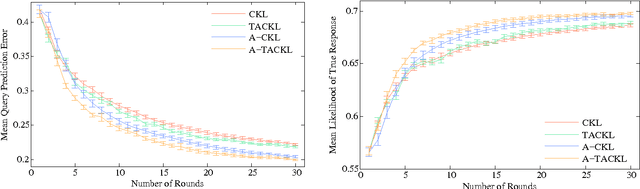

Learning a model of perceptual similarity from a collection of objects is a fundamental task in machine learning underlying numerous applications. A common way to learn such a model is from relative comparisons in the form of triplets: responses to queries of the form "Is object a more similar to b than it is to c?". If no consideration is made in the determination of which queries to ask, existing similarity learning methods can require a prohibitively large number of responses. In this work, we consider the problem of actively learning from triplets -finding which queries are most useful for learning. Different from previous active triplet learning approaches, we incorporate auxiliary information into our similarity model and introduce an active learning scheme to find queries that are informative for quickly learning both the relevant aspects of auxiliary data and the directly-learned similarity components. Compared to prior approaches, we show that we can learn just as effectively with much fewer queries. For evaluation, we introduce a new dataset of exhaustive triplet comparisons obtained from humans and demonstrate improved performance for different types of auxiliary information.