 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisually Analyzing Contextualized Embeddings
Paper and Code
Sep 05, 2020

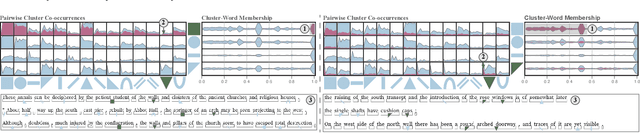
In this paper we introduce a method for visually analyzing contextualized embeddings produced by deep neural network-based language models. Our approach is inspired by linguistic probes for natural language processing, where tasks are designed to probe language models for linguistic structure, such as parts-of-speech and named entities. These approaches are largely confirmatory, however, only enabling a user to test for information known a priori. In this work, we eschew supervised probing tasks, and advocate for unsupervised probes, coupled with visual exploration techniques, to assess what is learned by language models. Specifically, we cluster contextualized embeddings produced from a large text corpus, and introduce a visualization design based on this clustering and textual structure - cluster co-occurrences, cluster spans, and cluster-word membership - to help elicit the functionality of, and relationship between, individual clusters. User feedback highlights the benefits of our design in discovering different types of linguistic structures.