 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBadRSSD: Backdoor Attacks on Regularized Self-Supervised Diffusion Models
Mar 01, 2026Self-supervised diffusion models learn high-quality visual representations via latent space denoising. However, their representation layer poses a distinct threat: unlike traditional attacks targeting generative outputs, its unconstrained latent semantic space allows for stealthy backdoors, permitting malicious control upon triggering. In this paper, we propose BadRSSD, the first backdoor attack targeting the representation layer of self-supervised diffusion models. Specifically, it hijacks the semantic representations of poisoned samples with triggers in Principal Component Analysis (PCA) space toward those of a target image, then controls the denoising trajectory during diffusion by applying coordinated constraints across latent, pixel, and feature distribution spaces to steer the model toward generating the specified target. Additionally, we integrate representation dispersion regularization into the constraint framework to maintain feature space uniformity, significantly enhancing attack stealth. This approach preserves normal model functionality (high utility) while achieving precise target generation upon trigger activation (high specificity). Experiments on multiple benchmark datasets demonstrate that BadRSSD substantially outperforms existing attacks in both FID and MSE metrics, reliably establishing backdoors across different architectures and configurations, and effectively resisting state-of-the-art backdoor defenses.
Generating Transferrable Adversarial Examples via Local Mixing and Logits Optimization for Remote Sensing Object Recognition
Sep 09, 2025Deep Neural Networks (DNNs) are vulnerable to adversarial attacks, posing significant security threats to their deployment in remote sensing applications. Research on adversarial attacks not only reveals model vulnerabilities but also provides critical insights for enhancing robustness. Although current mixing-based strategies have been proposed to increase the transferability of adversarial examples, they either perform global blending or directly exchange a region in the images, which may destroy global semantic features and mislead the optimization of adversarial examples. Furthermore, their reliance on cross-entropy loss for perturbation optimization leads to gradient diminishing during iterative updates, compromising adversarial example quality. To address these limitations, we focus on non-targeted attacks and propose a novel framework via local mixing and logits optimization. First, we present a local mixing strategy to generate diverse yet semantically consistent inputs. Different from MixUp, which globally blends two images, and MixCut, which stitches images together, our method merely blends local regions to preserve global semantic information. Second, we adapt the logit loss from targeted attacks to non-targeted scenarios, mitigating the gradient vanishing problem of cross-entropy loss. Third, a perturbation smoothing loss is applied to suppress high-frequency noise and enhance transferability. Extensive experiments on FGSCR-42 and MTARSI datasets demonstrate superior performance over 12 state-of-the-art methods across 6 surrogate models. Notably, with ResNet as the surrogate on MTARSI, our method achieves a 17.28% average improvement in black-box attack success rate.
IPBA: Imperceptible Perturbation Backdoor Attack in Federated Self-Supervised Learning
Aug 11, 2025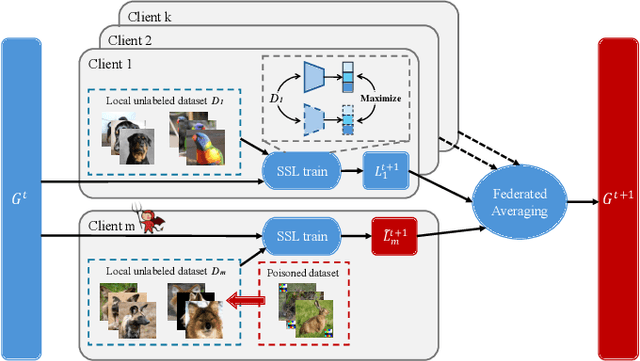
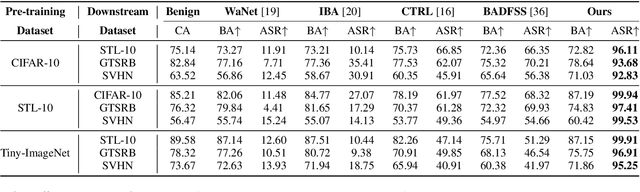

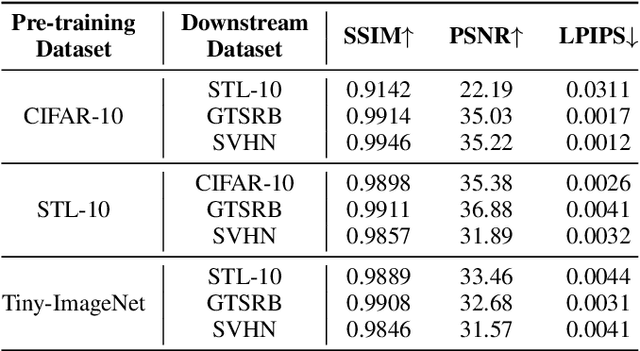
Federated self-supervised learning (FSSL) combines the advantages of decentralized modeling and unlabeled representation learning, serving as a cutting-edge paradigm with strong potential for scalability and privacy preservation. Although FSSL has garnered increasing attention, research indicates that it remains vulnerable to backdoor attacks. Existing methods generally rely on visually obvious triggers, which makes it difficult to meet the requirements for stealth and practicality in real-world deployment. In this paper, we propose an imperceptible and effective backdoor attack method against FSSL, called IPBA. Our empirical study reveals that existing imperceptible triggers face a series of challenges in FSSL, particularly limited transferability, feature entanglement with augmented samples, and out-of-distribution properties. These issues collectively undermine the effectiveness and stealthiness of traditional backdoor attacks in FSSL. To overcome these challenges, IPBA decouples the feature distributions of backdoor and augmented samples, and introduces Sliced-Wasserstein distance to mitigate the out-of-distribution properties of backdoor samples, thereby optimizing the trigger generation process. Our experimental results on several FSSL scenarios and datasets show that IPBA significantly outperforms existing backdoor attack methods in performance and exhibits strong robustness under various defense mechanisms.
Augmenting Prototype Network with TransMix for Few-shot Hyperspectral Image Classification
Jan 22, 2024



Few-shot hyperspectral image classification aims to identify the classes of each pixel in the images by only marking few of these pixels. And in order to obtain the spatial-spectral joint features of each pixel, the fixed-size patches centering around each pixel are often used for classification. However, observing the classification results of existing methods, we found that boundary patches corresponding to the pixels which are located at the boundary of the objects in the hyperspectral images, are hard to classify. These boundary patchs are mixed with multi-class spectral information. Inspired by this, we propose to augment the prototype network with TransMix for few-shot hyperspectrial image classification(APNT). While taking the prototype network as the backbone, it adopts the transformer as feature extractor to learn the pixel-to-pixel relation and pay different attentions to different pixels. At the same time, instead of directly using the patches which are cut from the hyperspectral images for training, it randomly mixs up two patches to imitate the boundary patches and uses the synthetic patches to train the model, with the aim to enlarge the number of hard training samples and enhance their diversity. And by following the data agumentation technique TransMix, the attention returned by the transformer is also used to mix up the labels of two patches to generate better labels for synthetic patches. Compared with existing methods, the proposed method has demonstrated sate of the art performance and better robustness for few-shot hyperspectral image classification in our experiments.
Attention Flows: Analyzing and Comparing Attention Mechanisms in Language Models
Sep 03, 2020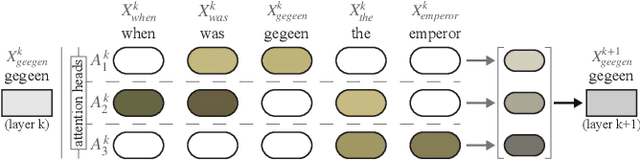
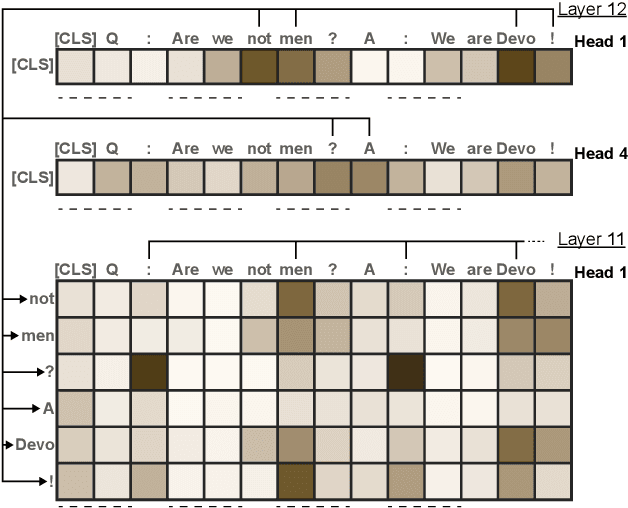
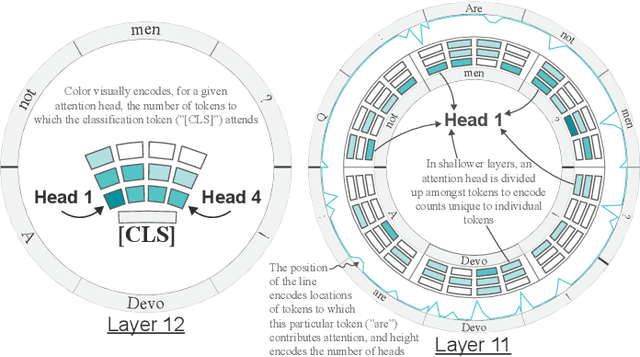
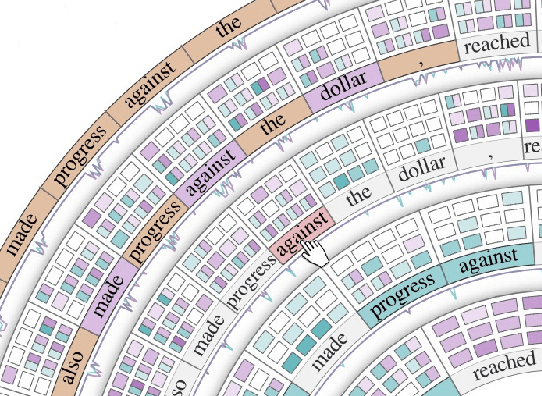
Advances in language modeling have led to the development of deep attention-based models that are performant across a wide variety of natural language processing (NLP) problems. These language models are typified by a pre-training process on large unlabeled text corpora and subsequently fine-tuned for specific tasks. Although considerable work has been devoted to understanding the attention mechanisms of pre-trained models, it is less understood how a model's attention mechanisms change when trained for a target NLP task. In this paper, we propose a visual analytics approach to understanding fine-tuning in attention-based language models. Our visualization, Attention Flows, is designed to support users in querying, tracing, and comparing attention within layers, across layers, and amongst attention heads in Transformer-based language models. To help users gain insight on how a classification decision is made, our design is centered on depicting classification-based attention at the deepest layer and how attention from prior layers flows throughout words in the input. Attention Flows supports the analysis of a single model, as well as the visual comparison between pre-trained and fine-tuned models via their similarities and differences. We use Attention Flows to study attention mechanisms in various sentence understanding tasks and highlight how attention evolves to address the nuances of solving these tasks.