 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure-Aware Variational Learning of a Class of Generalized Diffusions
Apr 22, 2026Learning the underlying potential energy of stochastic gradient systems from partial and noisy observations is a fundamental problem arising in physics, chemistry, and data-driven modeling. Classical approaches often rely on direct regression of governing equations or velocity fields, which can be sensitive to noise and external perturbations and may fail when observations are incomplete. In this work, we propose a structure-aware, energy-based learning framework for inferring unknown potential functions in generalized diffusion processes, grounded in the energetic variational approach. Starting from the energy-dissipation law associated with the Fokker-Planck equation, we construct loss functions based on the De Giorgi dissipation functional, which consistently couple the free energy and the dissipation mechanism of the system. This formulation avoids explicit enforcement of the governing partial differential equation and preserves the underlying variational structure of the dynamics. Through numerical experiments in one, two, and three dimensions, we demonstrate that the proposed energy-based loss exhibits enhanced robustness with respect to observation time, noise level, and the diversity and amount of available training data. These results highlight the effectiveness of energy-dissipation principles as a reliable foundation for learning stochastic diffusion dynamics from data.
When Noise Lowers The Loss: Rethinking Likelihood-Based Evaluation in Music Large Language Models
Feb 02, 2026The rise of music large language models (LLMs) demands robust methods of evaluating output quality, especially in distinguishing high-quality compositions from "garbage music". Curiously, we observe that the standard cross-entropy loss -- a core training metric -- often decrease when models encounter systematically corrupted music, undermining its validity as a standalone quality indicator. To investigate this paradox, we introduce noise injection experiment, where controlled noise signal of varying lengths are injected into musical contexts. We hypothesize that a model's loss reacting positively to these perturbations, specifically a sharp increase ("Peak" area) for short injection, can serve as a proxy for its ability to discern musical integrity. Experiments with MusicGen models in the audio waveform domain confirm that Music LLMs respond more strongly to local, texture-level disruptions than to global semantic corruption. Beyond exposing this bias, our results highlight a new principle: the shape of the loss curve -- rather than its absolute value -- encodes critical information about the quality of the generated content (i.e., model behavior). We envision this profile-based evaluation as a label-free, model-intrinsic framework for assessing musical quality -- opening the door to more principled training objectives and sharper benchmarks.
Generating Transferrable Adversarial Examples via Local Mixing and Logits Optimization for Remote Sensing Object Recognition
Sep 09, 2025Deep Neural Networks (DNNs) are vulnerable to adversarial attacks, posing significant security threats to their deployment in remote sensing applications. Research on adversarial attacks not only reveals model vulnerabilities but also provides critical insights for enhancing robustness. Although current mixing-based strategies have been proposed to increase the transferability of adversarial examples, they either perform global blending or directly exchange a region in the images, which may destroy global semantic features and mislead the optimization of adversarial examples. Furthermore, their reliance on cross-entropy loss for perturbation optimization leads to gradient diminishing during iterative updates, compromising adversarial example quality. To address these limitations, we focus on non-targeted attacks and propose a novel framework via local mixing and logits optimization. First, we present a local mixing strategy to generate diverse yet semantically consistent inputs. Different from MixUp, which globally blends two images, and MixCut, which stitches images together, our method merely blends local regions to preserve global semantic information. Second, we adapt the logit loss from targeted attacks to non-targeted scenarios, mitigating the gradient vanishing problem of cross-entropy loss. Third, a perturbation smoothing loss is applied to suppress high-frequency noise and enhance transferability. Extensive experiments on FGSCR-42 and MTARSI datasets demonstrate superior performance over 12 state-of-the-art methods across 6 surrogate models. Notably, with ResNet as the surrogate on MTARSI, our method achieves a 17.28% average improvement in black-box attack success rate.
Few-shot Unknown Class Discovery of Hyperspectral Images with Prototype Learning and Clustering
Aug 25, 2025Open-set few-shot hyperspectral image (HSI) classification aims to classify image pixels by using few labeled pixels per class, where the pixels to be classified may be not all from the classes that have been seen. To address the open-set HSI classification challenge, current methods focus mainly on distinguishing the unknown class samples from the known class samples and rejecting them to increase the accuracy of identifying known class samples. They fails to further identify or discovery the unknow classes among the samples. This paper proposes a prototype learning and clustering method for discoverying unknown classes in HSIs under the few-shot environment. Using few labeled samples, it strives to develop the ability of infering the prototypes of unknown classes while distinguishing unknown classes from known classes. Once the unknown class samples are rejected by the learned known class classifier, the proposed method can further cluster the unknown class samples into different classes according to their distance to the inferred unknown class prototypes. Compared to existing state-of-the-art methods, extensive experiments on four benchmark HSI datasets demonstrate that our proposed method exhibits competitive performance in open-set few-shot HSI classification tasks. All the codes are available at \href{https://github.com/KOBEN-ff/OpenFUCD-main} {https://github.com/KOBEN-ff/OpenFUCD-main}
Active Learning for Manifold Gaussian Process Regression
Jun 26, 2025This paper introduces an active learning framework for manifold Gaussian Process (GP) regression, combining manifold learning with strategic data selection to improve accuracy in high-dimensional spaces. Our method jointly optimizes a neural network for dimensionality reduction and a Gaussian process regressor in the latent space, supervised by an active learning criterion that minimizes global prediction error. Experiments on synthetic data demonstrate superior performance over randomly sequential learning. The framework efficiently handles complex, discontinuous functions while preserving computational tractability, offering practical value for scientific and engineering applications. Future work will focus on scalability and uncertainty-aware manifold learning.
Accelerating Particle-based Energetic Variational Inference
Apr 04, 2025In this work, we propose a novel particle-based variational inference (ParVI) method that accelerates the EVI-Im. Inspired by energy quadratization (EQ) and operator splitting techniques for gradient flows, our approach efficiently drives particles towards the target distribution. Unlike EVI-Im, which employs the implicit Euler method to solve variational-preserving particle dynamics for minimizing the KL divergence, derived using a "discretize-then-variational" approach, the proposed algorithm avoids repeated evaluation of inter-particle interaction terms, significantly reducing computational cost. The framework is also extensible to other gradient-based sampling techniques. Through several numerical experiments, we demonstrate that our method outperforms existing ParVI approaches in efficiency, robustness, and accuracy.
LLMEmbed: Rethinking Lightweight LLM's Genuine Function in Text Classification
Jun 06, 2024
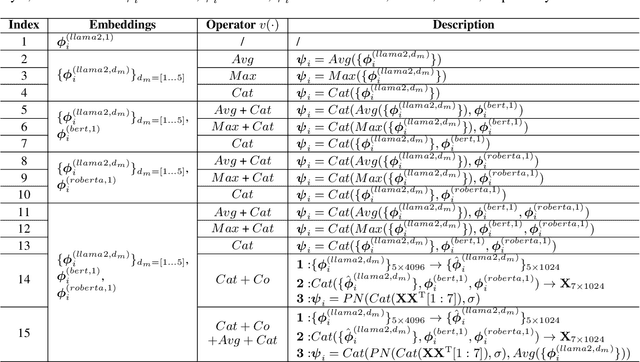
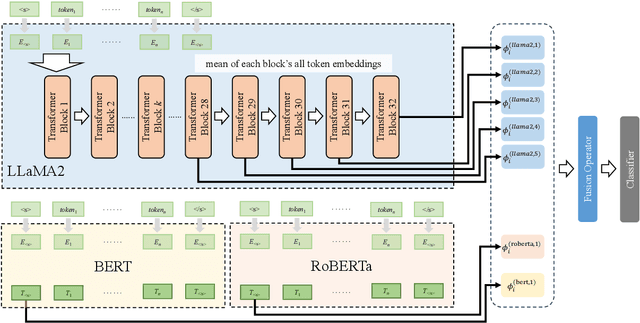
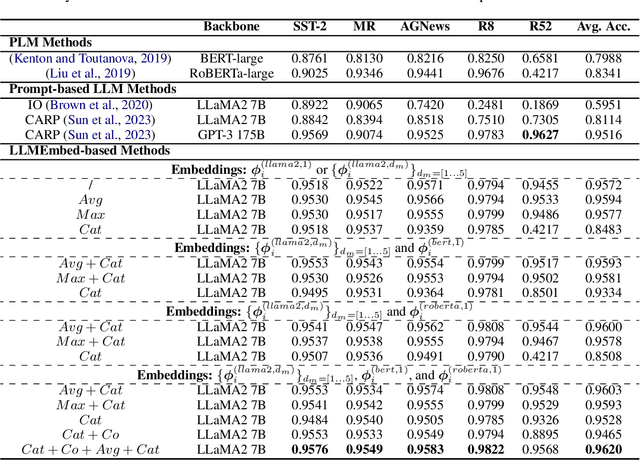
With the booming of Large Language Models (LLMs), prompt-learning has become a promising method mainly researched in various research areas. Recently, many attempts based on prompt-learning have been made to improve the performance of text classification. However, most of these methods are based on heuristic Chain-of-Thought (CoT), and tend to be more complex but less efficient. In this paper, we rethink the LLM-based text classification methodology, propose a simple and effective transfer learning strategy, namely LLMEmbed, to address this classical but challenging task. To illustrate, we first study how to properly extract and fuse the text embeddings via various lightweight LLMs at different network depths to improve their robustness and discrimination, then adapt such embeddings to train the classifier. We perform extensive experiments on publicly available datasets, and the results show that LLMEmbed achieves strong performance while enjoys low training overhead using lightweight LLM backbones compared to recent methods based on larger LLMs, i.e. GPT-3, and sophisticated prompt-based strategies. Our LLMEmbed achieves adequate accuracy on publicly available benchmarks without any fine-tuning while merely use 4% model parameters, 1.8% electricity consumption and 1.5% runtime compared to its counterparts. Code is available at: https://github.com/ChunLiu-cs/LLMEmbed-ACL2024.
Fast Estimation of Relative Transformation Based on Fusion of Odometry and UWB Ranging Data
May 21, 2024
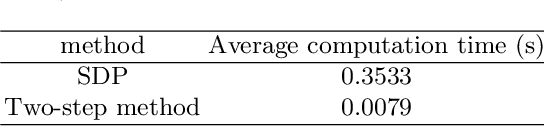
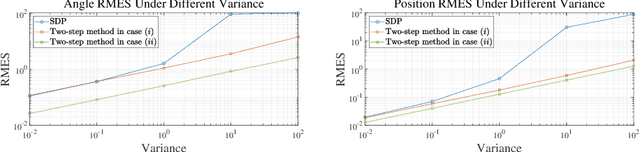

In this paper, we investigate the problem of estimating the 4-DOF (three-dimensional position and orientation) robot-robot relative frame transformation using odometers and distance measurements between robots. Firstly, we apply a two-step estimation method based on maximum likelihood estimation. Specifically, a good initial value is obtained through unconstrained least squares and projection, followed by a more accurate estimate achieved through one-step Gauss-Newton iteration. Additionally, the optimal installation positions of Ultra-Wideband (UWB) are provided, and the minimum operating time under different quantities of UWB devices is determined. Simulation demonstrates that the two-step approach offers faster computation with guaranteed accuracy while effectively addressing the relative transformation estimation problem within limited space constraints. Furthermore, this method can be applied to real-time relative transformation estimation when a specific number of UWB devices are installed.
E4C: Enhance Editability for Text-Based Image Editing by Harnessing Efficient CLIP Guidance
Mar 15, 2024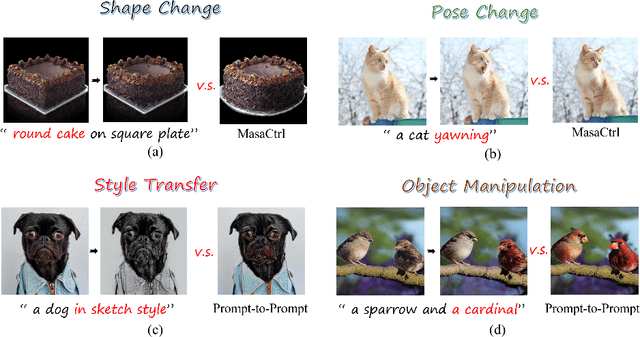
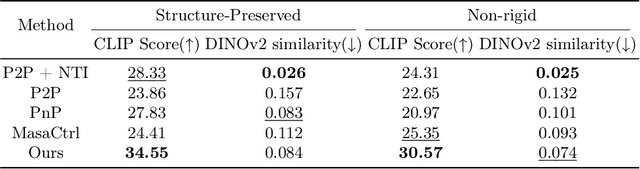
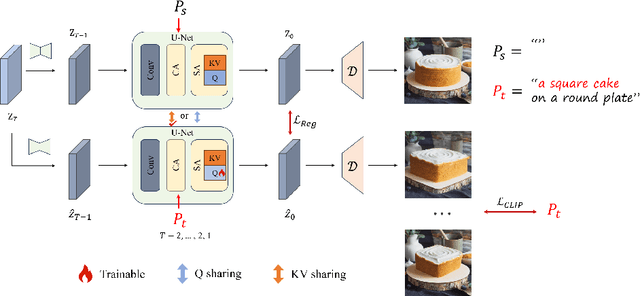

Diffusion-based image editing is a composite process of preserving the source image content and generating new content or applying modifications. While current editing approaches have made improvements under text guidance, most of them have only focused on preserving the information of the input image, disregarding the importance of editability and alignment to the target prompt. In this paper, we prioritize the editability by proposing a zero-shot image editing method, named \textbf{E}nhance \textbf{E}ditability for text-based image \textbf{E}diting via \textbf{E}fficient \textbf{C}LIP guidance (\textbf{E4C}), which only requires inference-stage optimization to explicitly enhance the edibility and text alignment. Specifically, we develop a unified dual-branch feature-sharing pipeline that enables the preservation of the structure or texture of the source image while allowing the other to be adapted based on the editing task. We further integrate CLIP guidance into our pipeline by utilizing our novel random-gateway optimization mechanism to efficiently enhance the semantic alignment with the target prompt. Comprehensive quantitative and qualitative experiments demonstrate that our method effectively resolves the text alignment issues prevalent in existing methods while maintaining the fidelity to the source image, and performs well across a wide range of editing tasks.
Augmenting Prototype Network with TransMix for Few-shot Hyperspectral Image Classification
Jan 22, 2024



Few-shot hyperspectral image classification aims to identify the classes of each pixel in the images by only marking few of these pixels. And in order to obtain the spatial-spectral joint features of each pixel, the fixed-size patches centering around each pixel are often used for classification. However, observing the classification results of existing methods, we found that boundary patches corresponding to the pixels which are located at the boundary of the objects in the hyperspectral images, are hard to classify. These boundary patchs are mixed with multi-class spectral information. Inspired by this, we propose to augment the prototype network with TransMix for few-shot hyperspectrial image classification(APNT). While taking the prototype network as the backbone, it adopts the transformer as feature extractor to learn the pixel-to-pixel relation and pay different attentions to different pixels. At the same time, instead of directly using the patches which are cut from the hyperspectral images for training, it randomly mixs up two patches to imitate the boundary patches and uses the synthetic patches to train the model, with the aim to enlarge the number of hard training samples and enhance their diversity. And by following the data agumentation technique TransMix, the attention returned by the transformer is also used to mix up the labels of two patches to generate better labels for synthetic patches. Compared with existing methods, the proposed method has demonstrated sate of the art performance and better robustness for few-shot hyperspectral image classification in our experiments.