 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE4C: Enhance Editability for Text-Based Image Editing by Harnessing Efficient CLIP Guidance
Mar 15, 2024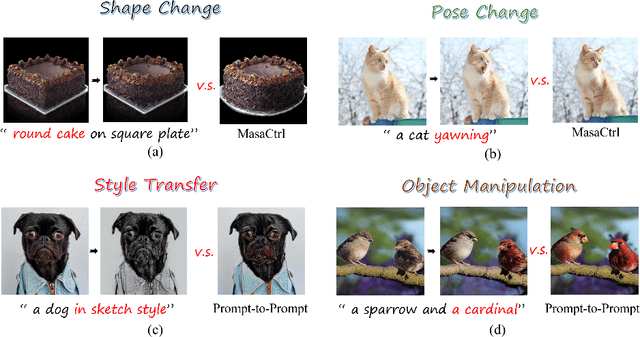
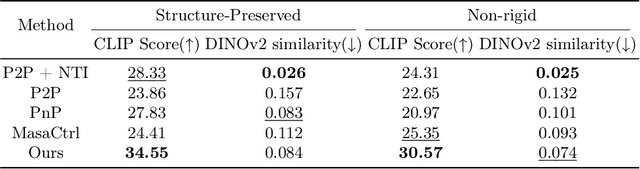
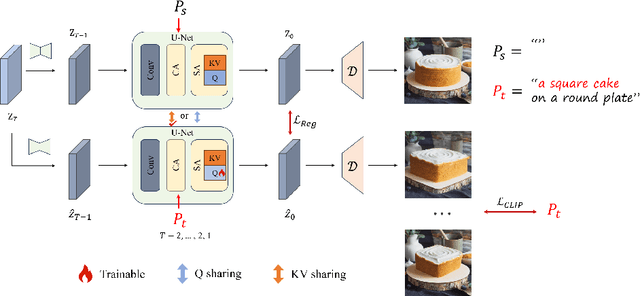

Diffusion-based image editing is a composite process of preserving the source image content and generating new content or applying modifications. While current editing approaches have made improvements under text guidance, most of them have only focused on preserving the information of the input image, disregarding the importance of editability and alignment to the target prompt. In this paper, we prioritize the editability by proposing a zero-shot image editing method, named \textbf{E}nhance \textbf{E}ditability for text-based image \textbf{E}diting via \textbf{E}fficient \textbf{C}LIP guidance (\textbf{E4C}), which only requires inference-stage optimization to explicitly enhance the edibility and text alignment. Specifically, we develop a unified dual-branch feature-sharing pipeline that enables the preservation of the structure or texture of the source image while allowing the other to be adapted based on the editing task. We further integrate CLIP guidance into our pipeline by utilizing our novel random-gateway optimization mechanism to efficiently enhance the semantic alignment with the target prompt. Comprehensive quantitative and qualitative experiments demonstrate that our method effectively resolves the text alignment issues prevalent in existing methods while maintaining the fidelity to the source image, and performs well across a wide range of editing tasks.
Concept-centric Personalization with Large-scale Diffusion Priors
Dec 13, 2023Despite large-scale diffusion models being highly capable of generating diverse open-world content, they still struggle to match the photorealism and fidelity of concept-specific generators. In this work, we present the task of customizing large-scale diffusion priors for specific concepts as concept-centric personalization. Our goal is to generate high-quality concept-centric images while maintaining the versatile controllability inherent to open-world models, enabling applications in diverse tasks such as concept-centric stylization and image translation. To tackle these challenges, we identify catastrophic forgetting of guidance prediction from diffusion priors as the fundamental issue. Consequently, we develop a guidance-decoupled personalization framework specifically designed to address this task. We propose Generalized Classifier-free Guidance (GCFG) as the foundational theory for our framework. This approach extends Classifier-free Guidance (CFG) to accommodate an arbitrary number of guidances, sourced from a variety of conditions and models. Employing GCFG enables us to separate conditional guidance into two distinct components: concept guidance for fidelity and control guidance for controllability. This division makes it feasible to train a specialized model for concept guidance, while ensuring both control and unconditional guidance remain intact. We then present a null-text Concept-centric Diffusion Model as a concept-specific generator to learn concept guidance without the need for text annotations. Code will be available at https://github.com/PRIV-Creation/Concept-centric-Personalization.