 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Aware 3D Gaussian Editing for Driving Scene Generation
May 25, 20263D Gaussian Splatting (3DGS) has shown great potential in autonomous driving simulation and data generation, enabling photorealistic reconstruction and flexible scene manipulation. However, existing 3DGS scene editing methods have limited support for road geometry editing (e.g., inserting speed humps or sunken roads), and generally do not couple such edits with plausible vehicle-road interaction dynamics. Such editing is essential for generating training data under extreme driving scenarios or evaluating system reliability under these road irregularities. Moreover, many optimization-based methods require minutes of per-edit refinement, while existing efficient alternatives mainly focus on appearance-level or object-level manipulation rather than physics-aware road irregularity editing. To address these limitations, we propose RoVES, a Road-and-Vehicle Editing System for physics-aware 3D Gaussian editing in driving scenes. RoVES enables single-image-driven road geometry insertion and couples the edited road profile with a 4-DOF half-car vehicle dynamics model to achieve physics-aware vehicle pose correction in vertical displacement and pitch. RoVES inserts road elements in a one-shot, optimization-free pipeline (1.84s), and the full pipeline (including color transfer and vehicle-dynamics-based pose correction) completes in 6.24s; it edits dynamic vehicles via pose editing and corrects poses frame-by-frame to approximate dynamics-consistent vertical displacement and pitch responses. Experiments on the Waymo dataset show that RoVES provides practical efficiency and competitive visual consistency for physics-aware driving scene generation.
Meow-Omni 1: A Multimodal Large Language Model for Feline Ethology
May 09, 2026Deciphering animal intent is a fundamental challenge in computational ethology, largely because of semantic aliasing, the phenomenon where identical external signals (e.g., a cat's purr) correspond to radically different internal states depending on physiological context. Existing Multimodal Large Language Models (MLLMs) are blind to high-frequency biological time-series data, restricting them to superficial behavioural pattern matching rather than genuine latent-state reasoning. To bridge this gap, we introduce Meow-Omni 1, the first open-source, quad-modal MLLM purpose-built for computational ethology. It natively fuses video, audio, and physiological time-series streams with textual reasoning. Through targeted architectural adaptation, we integrate specialized scientific encoders into a unified backbone and formalize intent inference via physiologically grounded cross-modal alignment. Evaluated on MeowBench, a novel, expert-verified quad-modal benchmark, Meow-Omni 1 achieves state-of-the-art intent-recognition accuracy (71.16%), substantially outperforming leading vision-language and omni-modal baselines. We release the complete open-source pipeline including model weights, training framework, and the Meow-10K dataset, to establish a scalable paradigm for inter-species intent understanding and to advance foundation models toward real-world veterinary diagnostics and wildlife conservation.
InfoMamba: An Attention-Free Hybrid Mamba-Transformer Model
Mar 08, 2026Balancing fine-grained local modeling with long-range dependency capture under computational constraints remains a central challenge in sequence modeling. While Transformers provide strong token mixing, they suffer from quadratic complexity, whereas Mamba-style selective state-space models (SSMs) scale linearly but often struggle to capture high-rank and synchronous global interactions. We present a consistency boundary analysis that characterizes when diagonal short-memory SSMs can approximate causal attention and identifies structural gaps that remain. Motivated by this analysis, we propose InfoMamba, an attention-free hybrid architecture. InfoMamba replaces token-level self-attention with a concept bottleneck linear filtering layer that serves as a minimal-bandwidth global interface and integrates it with a selective recurrent stream through information-maximizing fusion (IMF). IMF dynamically injects global context into the SSM dynamics and encourages complementary information usage through a mutual-information-inspired objective. Extensive experiments on classification, dense prediction, and non-vision tasks show that InfoMamba consistently outperforms strong Transformer and SSM baselines, achieving competitive accuracy-efficiency trade-offs while maintaining near-linear scaling.
On the Expressive Power of Transformers for Maxout Networks and Continuous Piecewise Linear Functions
Mar 03, 2026Transformer networks have achieved remarkable empirical success across a wide range of applications, yet their theoretical expressive power remains insufficiently understood. In this paper, we study the expressive capabilities of Transformer architectures. We first establish an explicit approximation of maxout networks by Transformer networks while preserving comparable model complexity. As a consequence, Transformers inherit the universal approximation capability of ReLU networks under similar complexity constraints. Building on this connection, we develop a framework to analyze the approximation of continuous piecewise linear functions by Transformers and quantitatively characterize their expressivity via the number of linear regions, which grows exponentially with depth. Our analysis establishes a theoretical bridge between approximation theory for standard feedforward neural networks and Transformer architectures. It also yields structural insights into Transformers: self-attention layers implement max-type operations, while feedforward layers realize token-wise affine transformations.
Long-range Modeling and Processing of Multimodal Event Sequences
Feb 01, 2026Temporal point processes (TPPs) have emerged as powerful tools for modeling asynchronous event sequences. While recent advances have extended TPPs to handle textual information, existing approaches are limited in their ability to generate rich, multimodal content and reason about event dynamics. A key challenge is that incorporating multimodal data dramatically increases sequence length, hindering the ability of attention-based models to generate coherent, long-form textual descriptions that require long-range understanding. In this paper, we propose a novel framework that extends LLM-based TPPs to the visual modality, positioning text generation as a core capability alongside time and type prediction. Our approach addresses the long-context problem through an adaptive sequence compression mechanism based on temporal similarity, which reduces sequence length while preserving essential patterns. We employ a two-stage paradigm of pre-training on compressed sequences followed by supervised fine-tuning for downstream tasks. Extensive experiments, including on the challenging DanmakuTPP-QA benchmark, demonstrate that our method outperforms state-of-the-art baselines in both predictive accuracy and the quality of its generated textual analyses.
Diving into Kronecker Adapters: Component Design Matters
Feb 01, 2026Kronecker adapters have emerged as a promising approach for fine-tuning large-scale models, enabling high-rank updates through tunable component structures. However, existing work largely treats the component structure as a fixed or heuristic design choice, leaving the dimensions and number of Kronecker components underexplored. In this paper, we identify component structure as a key factor governing the capacity of Kronecker adapters. We perform a fine-grained analysis of both the dimensions and number of Kronecker components. In particular, we show that the alignment between Kronecker adapters and full fine-tuning depends on component configurations. Guided by these insights, we propose Component Designed Kronecker Adapters (CDKA). We further provide parameter-budget-aware configuration guidelines and a tailored training stabilization strategy for practical deployment. Experiments across various natural language processing tasks demonstrate the effectiveness of CDKA. Code is available at https://github.com/rainstonee/CDKA.
A Tilted Seesaw: Revisiting Autoencoder Trade-off for Controllable Diffusion
Jan 29, 2026In latent diffusion models, the autoencoder (AE) is typically expected to balance two capabilities: faithful reconstruction and a generation-friendly latent space (e.g., low gFID). In recent ImageNet-scale AE studies, we observe a systematic bias toward generative metrics in handling this trade-off: reconstruction metrics are increasingly under-reported, and ablation-based AE selection often favors the best-gFID configuration even when reconstruction fidelity degrades. We theoretically analyze why this gFID-dominant preference can appear unproblematic for ImageNet generation, yet becomes risky when scaling to controllable diffusion: AEs can induce condition drift, which limits achievable condition alignment. Meanwhile, we find that reconstruction fidelity, especially instance-level measures, better indicates controllability. We empirically validate the impact of tilted autoencoder evaluation on controllability by studying several recent ImageNet AEs. Using a multi-dimensional condition-drift evaluation protocol reflecting controllable generation tasks, we find that gFID is only weakly predictive of condition preservation, whereas reconstruction-oriented metrics are substantially more aligned. ControlNet experiments further confirm that controllability tracks condition preservation rather than gFID. Overall, our results expose a gap between ImageNet-centric AE evaluation and the requirements of scalable controllable diffusion, offering practical guidance for more reliable benchmarking and model selection.
Fair Bayesian Data Selection via Generalized Discrepancy Measures
Nov 10, 2025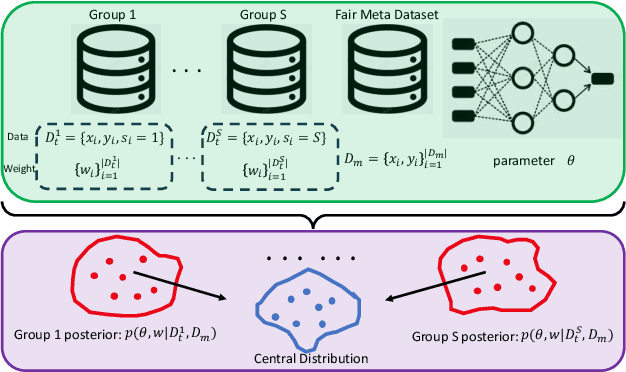
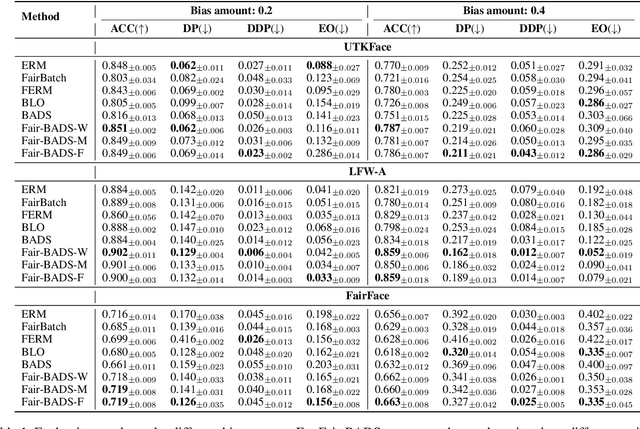

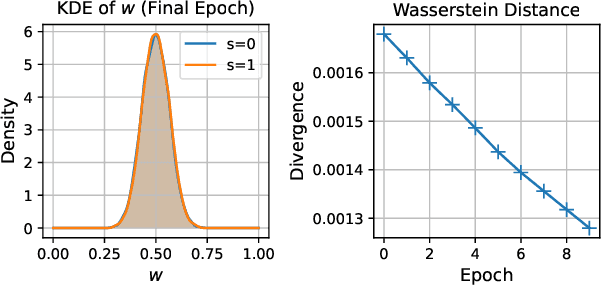
Fairness concerns are increasingly critical as machine learning models are deployed in high-stakes applications. While existing fairness-aware methods typically intervene at the model level, they often suffer from high computational costs, limited scalability, and poor generalization. To address these challenges, we propose a Bayesian data selection framework that ensures fairness by aligning group-specific posterior distributions of model parameters and sample weights with a shared central distribution. Our framework supports flexible alignment via various distributional discrepancy measures, including Wasserstein distance, maximum mean discrepancy, and $f$-divergence, allowing geometry-aware control without imposing explicit fairness constraints. This data-centric approach mitigates group-specific biases in training data and improves fairness in downstream tasks, with theoretical guarantees. Experiments on benchmark datasets show that our method consistently outperforms existing data selection and model-based fairness methods in both fairness and accuracy.
Negative Binomial Variational Autoencoders for Overdispersed Latent Modeling
Aug 07, 2025



Biological neurons communicate through spike trains, discrete, irregular bursts of activity that exhibit variability far beyond the modeling capacity of conventional variational autoencoders (VAEs). Recent work, such as the Poisson-VAE, makes a biologically inspired move by modeling spike counts using the Poisson distribution. However, they impose a rigid constraint: equal mean and variance, which fails to reflect the true stochastic nature of neural activity. In this work, we challenge this constraint and introduce NegBio-VAE, a principled extension of the VAE framework that models spike counts using the negative binomial distribution. This shift grants explicit control over dispersion, unlocking a broader and more accurate family of neural representations. We further develop two ELBO optimization schemes and two differentiable reparameterization strategies tailored to the negative binomial setting. By introducing one additional dispersion parameter, NegBio-VAE generalizes the Poisson latent model to a negative binomial formulation. Empirical results demonstrate this minor yet impactful change leads to significant gains in reconstruction fidelity, highlighting the importance of explicitly modeling overdispersion in spike-like activations.
AU-Blendshape for Fine-grained Stylized 3D Facial Expression Manipulation
Jul 16, 2025



While 3D facial animation has made impressive progress, challenges still exist in realizing fine-grained stylized 3D facial expression manipulation due to the lack of appropriate datasets. In this paper, we introduce the AUBlendSet, a 3D facial dataset based on AU-Blendshape representation for fine-grained facial expression manipulation across identities. AUBlendSet is a blendshape data collection based on 32 standard facial action units (AUs) across 500 identities, along with an additional set of facial postures annotated with detailed AUs. Based on AUBlendSet, we propose AUBlendNet to learn AU-Blendshape basis vectors for different character styles. AUBlendNet predicts, in parallel, the AU-Blendshape basis vectors of the corresponding style for a given identity mesh, thereby achieving stylized 3D emotional facial manipulation. We comprehensively validate the effectiveness of AUBlendSet and AUBlendNet through tasks such as stylized facial expression manipulation, speech-driven emotional facial animation, and emotion recognition data augmentation. Through a series of qualitative and quantitative experiments, we demonstrate the potential and importance of AUBlendSet and AUBlendNet in 3D facial animation tasks. To the best of our knowledge, AUBlendSet is the first dataset, and AUBlendNet is the first network for continuous 3D facial expression manipulation for any identity through facial AUs. Our source code is available at https://github.com/wslh852/AUBlendNet.git.