 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDEFT-LLM: Disentangled Expert Feature Tuning for Micro-Expression Recognition
Nov 14, 2025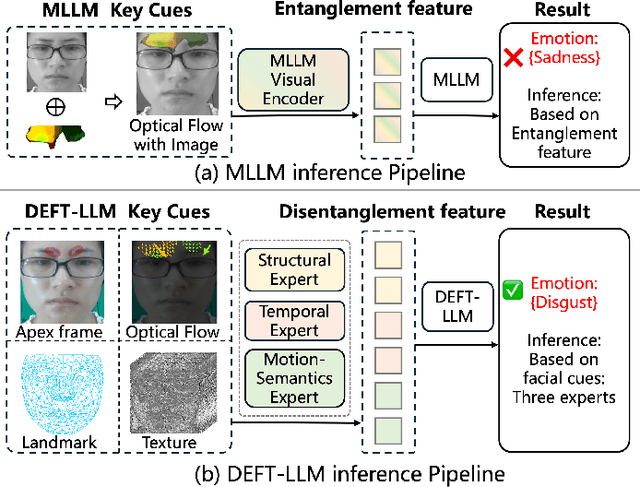
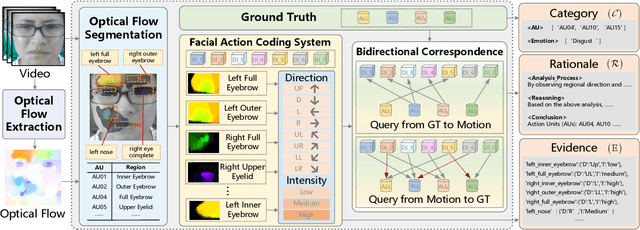
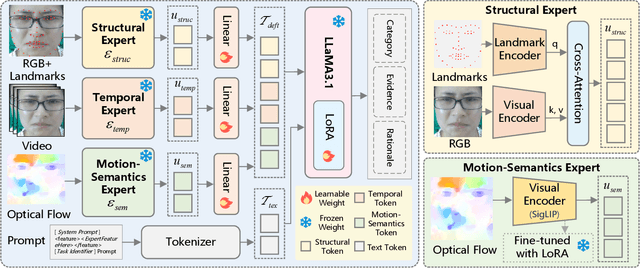
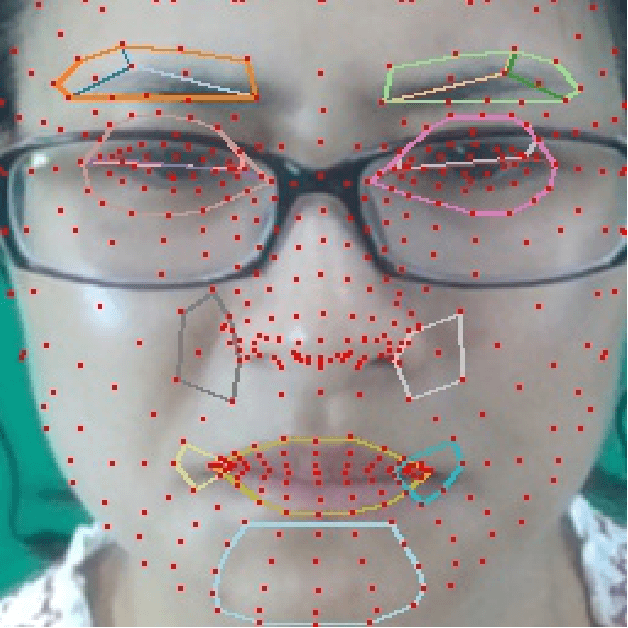
Micro expression recognition (MER) is crucial for inferring genuine emotion. Applying a multimodal large language model (MLLM) to this task enables spatio-temporal analysis of facial motion and provides interpretable descriptions. However, there are still two core challenges: (1) The entanglement of static appearance and dynamic motion cues prevents the model from focusing on subtle motion; (2) Textual labels in existing MER datasets do not fully correspond to underlying facial muscle movements, creating a semantic gap between text supervision and physical motion. To address these issues, we propose DEFT-LLM, which achieves motion semantic alignment by multi-expert disentanglement. We first introduce Uni-MER, a motion-driven instruction dataset designed to align text with local facial motion. Its construction leverages dual constraints from optical flow and Action Unit (AU) labels to ensure spatio-temporal consistency and reasonable correspondence to the movements. We then design an architecture with three experts to decouple facial dynamics into independent and interpretable representations (structure, dynamic textures, and motion-semantics). By integrating the instruction-aligned knowledge from Uni-MER into DEFT-LLM, our method injects effective physical priors for micro expressions while also leveraging the cross modal reasoning ability of large language models, thus enabling precise capture of subtle emotional cues. Experiments on multiple challenging MER benchmarks demonstrate state-of-the-art performance, as well as a particular advantage in interpretable modeling of local facial motion.
Learning Unified Force and Position Control for Legged Loco-Manipulation
May 27, 2025Robotic loco-manipulation tasks often involve contact-rich interactions with the environment, requiring the joint modeling of contact force and robot position. However, recent visuomotor policies often focus solely on learning position or force control, overlooking their co-learning. In this work, we propose the first unified policy for legged robots that jointly models force and position control learned without reliance on force sensors. By simulating diverse combinations of position and force commands alongside external disturbance forces, we use reinforcement learning to learn a policy that estimates forces from historical robot states and compensates for them through position and velocity adjustments. This policy enables a wide range of manipulation behaviors under varying force and position inputs, including position tracking, force application, force tracking, and compliant interactions. Furthermore, we demonstrate that the learned policy enhances trajectory-based imitation learning pipelines by incorporating essential contact information through its force estimation module, achieving approximately 39.5% higher success rates across four challenging contact-rich manipulation tasks compared to position-control policies. Extensive experiments on both a quadrupedal manipulator and a humanoid robot validate the versatility and robustness of the proposed policy across diverse scenarios.
CMIP-CIL: A Cross-Modal Benchmark for Image-Point Class Incremental Learning
Apr 11, 2025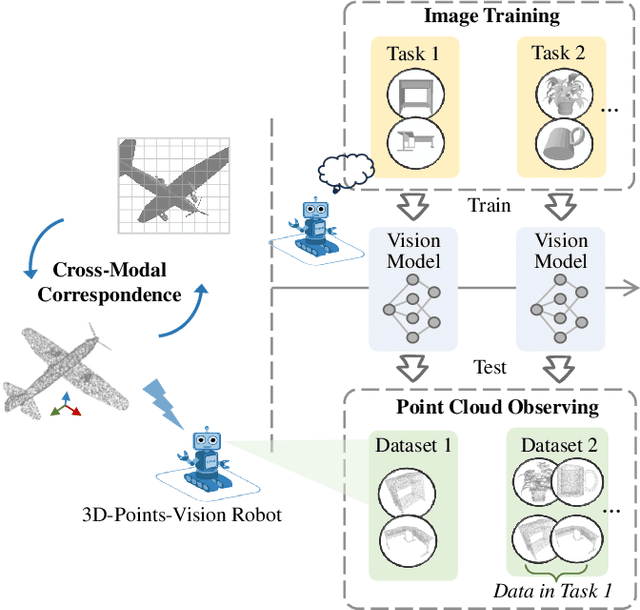
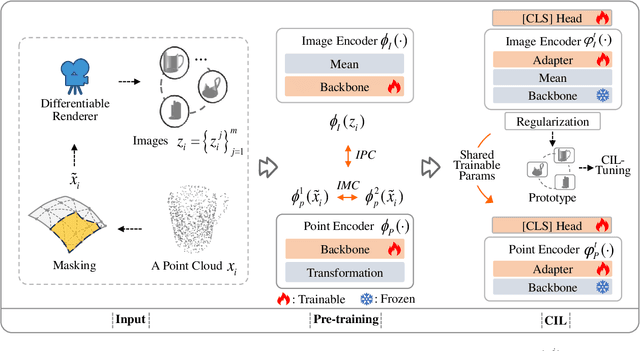
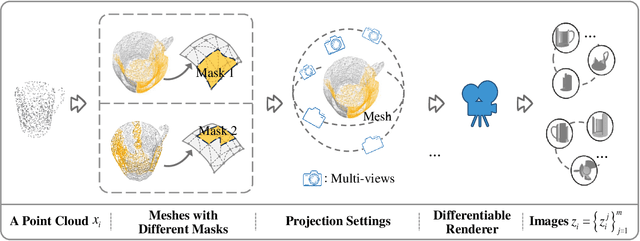
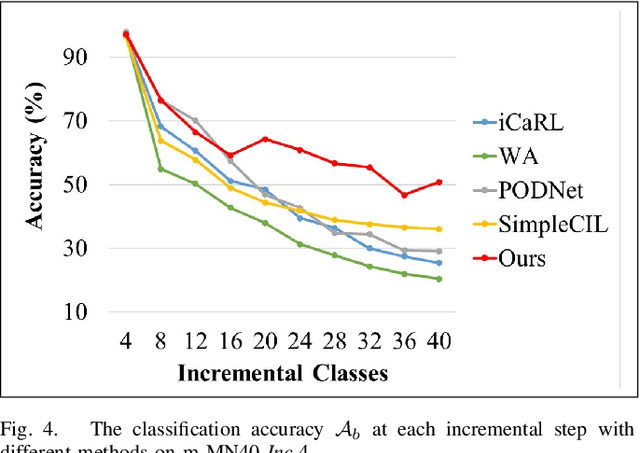
Image-point class incremental learning helps the 3D-points-vision robots continually learn category knowledge from 2D images, improving their perceptual capability in dynamic environments. However, some incremental learning methods address unimodal forgetting but fail in cross-modal cases, while others handle modal differences within training/testing datasets but assume no modal gaps between them. We first explore this cross-modal task, proposing a benchmark CMIP-CIL and relieving the cross-modal catastrophic forgetting problem. It employs masked point clouds and rendered multi-view images within a contrastive learning framework in pre-training, empowering the vision model with the generalizations of image-point correspondence. In the incremental stage, by freezing the backbone and promoting object representations close to their respective prototypes, the model effectively retains and generalizes knowledge across previously seen categories while continuing to learn new ones. We conduct comprehensive experiments on the benchmark datasets. Experiments prove that our method achieves state-of-the-art results, outperforming the baseline methods by a large margin.
Boosting the Class-Incremental Learning in 3D Point Clouds via Zero-Collection-Cost Basic Shape Pre-Training
Apr 11, 2025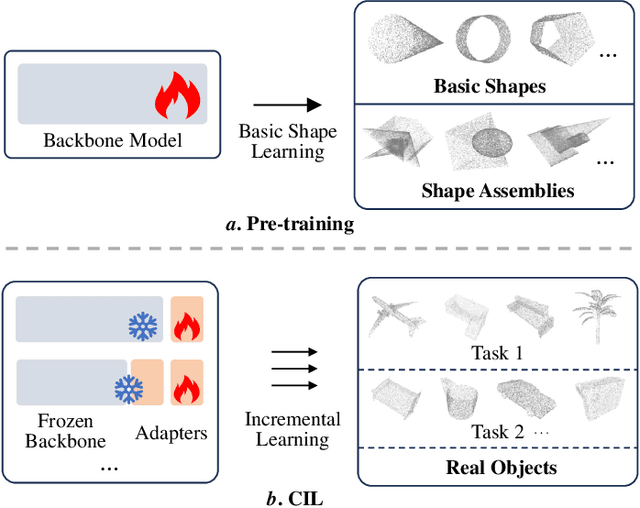
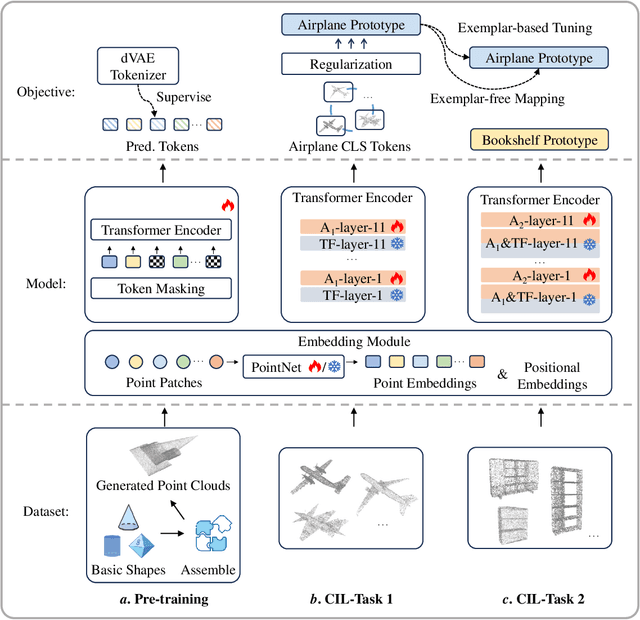
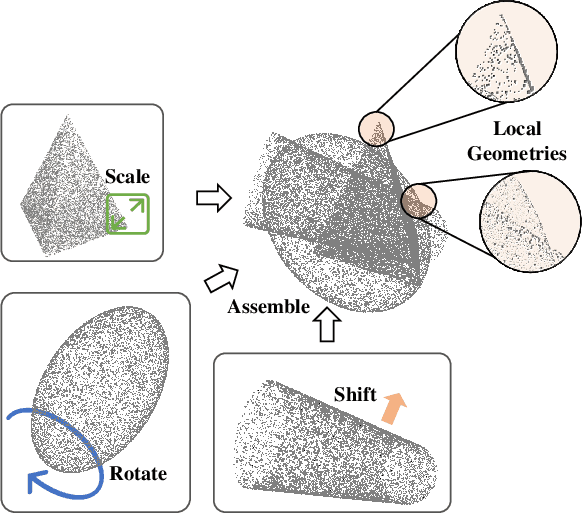
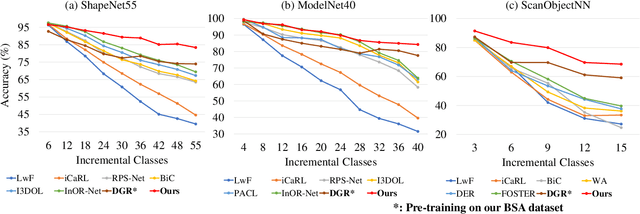
Existing class-incremental learning methods in 3D point clouds rely on exemplars (samples of former classes) to resist the catastrophic forgetting of models, and exemplar-free settings will greatly degrade the performance. For exemplar-free incremental learning, the pre-trained model methods have achieved state-of-the-art results in 2D domains. However, these methods cannot be migrated to the 3D domains due to the limited pre-training datasets and insufficient focus on fine-grained geometric details. This paper breaks through these limitations, proposing a basic shape dataset with zero collection cost for model pre-training. It helps a model obtain extensive knowledge of 3D geometries. Based on this, we propose a framework embedded with 3D geometry knowledge for incremental learning in point clouds, compatible with exemplar-free (-based) settings. In the incremental stage, the geometry knowledge is extended to represent objects in point clouds. The class prototype is calculated by regularizing the data representation with the same category and is kept adjusting in the learning process. It helps the model remember the shape features of different categories. Experiments show that our method outperforms other baseline methods by a large margin on various benchmark datasets, considering both exemplar-free (-based) settings.
L2HCount:Generalizing Crowd Counting from Low to High Crowd Density via Density Simulation
Mar 17, 2025Since COVID-19, crowd-counting tasks have gained wide applications. While supervised methods are reliable, annotation is more challenging in high-density scenes due to small head sizes and severe occlusion, whereas it's simpler in low-density scenes. Interestingly, can we train the model in low-density scenes and generalize it to high-density scenes? Therefore, we propose a low- to high-density generalization framework (L2HCount) that learns the pattern related to high-density scenes from low-density ones, enabling it to generalize well to high-density scenes. Specifically, we first introduce a High-Density Simulation Module and a Ground-Truth Generation Module to construct fake high-density images along with their corresponding ground-truth crowd annotations respectively by image-shifting technique, effectively simulating high-density crowd patterns. However, the simulated images have two issues: image blurring and loss of low-density image characteristics. Therefore, we second propose a Head Feature Enhancement Module to extract clear features in the simulated high-density scene. Third, we propose a Dual-Density Memory Encoding Module that uses two crowd memories to learn scene-specific patterns from low- and simulated high-density scenes, respectively. Extensive experiments on four challenging datasets have shown the promising performance of L2HCount.
Exploring Position Encoding in Diffusion U-Net for Training-free High-resolution Image Generation
Mar 12, 2025



Denoising higher-resolution latents via a pre-trained U-Net leads to repetitive and disordered image patterns. Although recent studies make efforts to improve generative quality by aligning denoising process across original and higher resolutions, the root cause of suboptimal generation is still lacking exploration. Through comprehensive analysis of position encoding in U-Net, we attribute it to inconsistent position encoding, sourced by the inadequate propagation of position information from zero-padding to latent features in convolution layers as resolution increases. To address this issue, we propose a novel training-free approach, introducing a Progressive Boundary Complement (PBC) method. This method creates dynamic virtual image boundaries inside the feature map to enhance position information propagation, enabling high-quality and rich-content high-resolution image synthesis. Extensive experiments demonstrate the superiority of our method.
GaussianCAD: Robust Self-Supervised CAD Reconstruction from Three Orthographic Views Using 3D Gaussian Splatting
Mar 07, 2025



The automatic reconstruction of 3D computer-aided design (CAD) models from CAD sketches has recently gained significant attention in the computer vision community. Most existing methods, however, rely on vector CAD sketches and 3D ground truth for supervision, which are often difficult to be obtained in industrial applications and are sensitive to noise inputs. We propose viewing CAD reconstruction as a specific instance of sparse-view 3D reconstruction to overcome these limitations. While this reformulation offers a promising perspective, existing 3D reconstruction methods typically require natural images and corresponding camera poses as inputs, which introduces two major significant challenges: (1) modality discrepancy between CAD sketches and natural images, and (2) difficulty of accurate camera pose estimation for CAD sketches. To solve these issues, we first transform the CAD sketches into representations resembling natural images and extract corresponding masks. Next, we manually calculate the camera poses for the orthographic views to ensure accurate alignment within the 3D coordinate system. Finally, we employ a customized sparse-view 3D reconstruction method to achieve high-quality reconstructions from aligned orthographic views. By leveraging raster CAD sketches for self-supervision, our approach eliminates the reliance on vector CAD sketches and 3D ground truth. Experiments on the Sub-Fusion360 dataset demonstrate that our proposed method significantly outperforms previous approaches in CAD reconstruction performance and exhibits strong robustness to noisy inputs.
MamKPD: A Simple Mamba Baseline for Real-Time 2D Keypoint Detection
Dec 02, 2024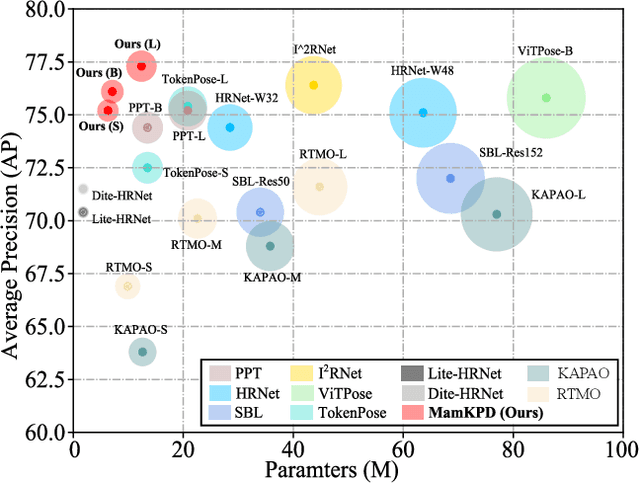
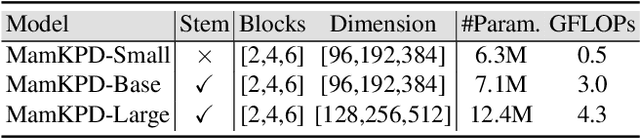
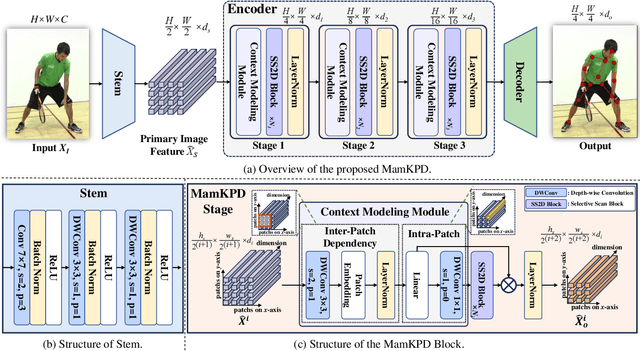
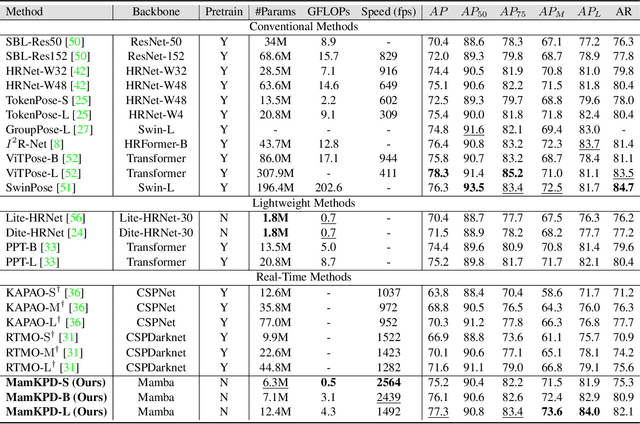
Real-time 2D keypoint detection plays an essential role in computer vision. Although CNN-based and Transformer-based methods have achieved breakthrough progress, they often fail to deliver superior performance and real-time speed. This paper introduces MamKPD, the first efficient yet effective mamba-based pose estimation framework for 2D keypoint detection. The conventional Mamba module exhibits limited information interaction between patches. To address this, we propose a lightweight contextual modeling module (CMM) that uses depth-wise convolutions to model inter-patch dependencies and linear layers to distill the pose cues within each patch. Subsequently, by combining Mamba for global modeling across all patches, MamKPD effectively extracts instances' pose information. We conduct extensive experiments on human and animal pose estimation datasets to validate the effectiveness of MamKPD. Our MamKPD-L achieves 77.3% AP on the COCO dataset with 1492 FPS on an NVIDIA GTX 4090 GPU. Moreover, MamKPD achieves state-of-the-art results on the MPII dataset and competitive results on the AP-10K dataset while saving 85% of the parameters compared to ViTPose. Our project page is available at https://mamkpd.github.io/.
InstruGen: Automatic Instruction Generation for Vision-and-Language Navigation Via Large Multimodal Models
Nov 18, 2024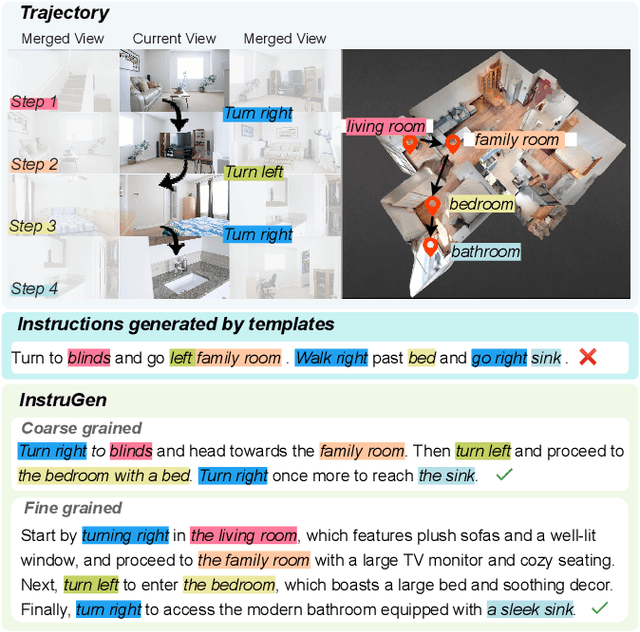
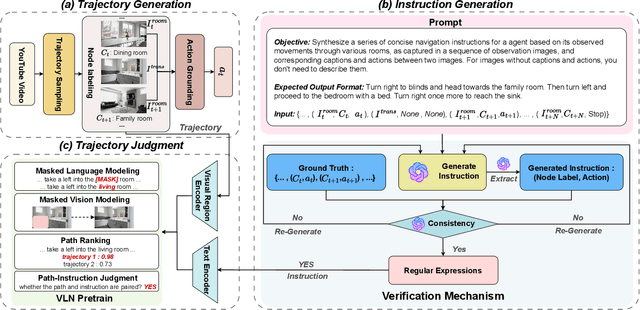


Recent research on Vision-and-Language Navigation (VLN) indicates that agents suffer from poor generalization in unseen environments due to the lack of realistic training environments and high-quality path-instruction pairs. Most existing methods for constructing realistic navigation scenes have high costs, and the extension of instructions mainly relies on predefined templates or rules, lacking adaptability. To alleviate the issue, we propose InstruGen, a VLN path-instruction pairs generation paradigm. Specifically, we use YouTube house tour videos as realistic navigation scenes and leverage the powerful visual understanding and generation abilities of large multimodal models (LMMs) to automatically generate diverse and high-quality VLN path-instruction pairs. Our method generates navigation instructions with different granularities and achieves fine-grained alignment between instructions and visual observations, which was difficult to achieve with previous methods. Additionally, we design a multi-stage verification mechanism to reduce hallucinations and inconsistency of LMMs. Experimental results demonstrate that agents trained with path-instruction pairs generated by InstruGen achieves state-of-the-art performance on the R2R and RxR benchmarks, particularly in unseen environments. Code is available at https://github.com/yanyu0526/InstruGen.
Towards Physically-Realizable Adversarial Attacks in Embodied Vision Navigation
Sep 16, 2024
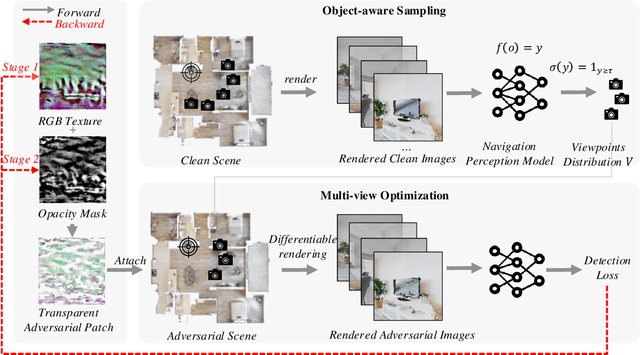

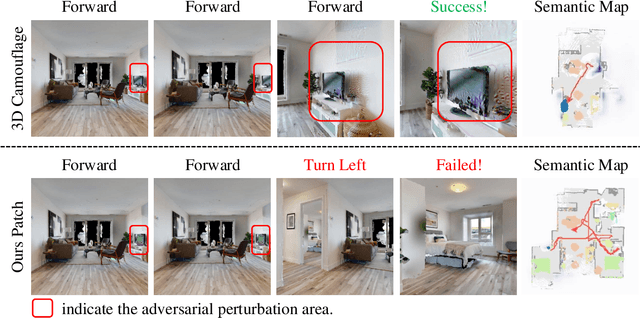
The deployment of embodied navigation agents in safety-critical environments raises concerns about their vulnerability to adversarial attacks on deep neural networks. However, current attack methods often lack practicality due to challenges in transitioning from the digital to the physical world, while existing physical attacks for object detection fail to achieve both multi-view effectiveness and naturalness. To address this, we propose a practical attack method for embodied navigation by attaching adversarial patches with learnable textures and opacity to objects. Specifically, to ensure effectiveness across varying viewpoints, we employ a multi-view optimization strategy based on object-aware sampling, which uses feedback from the navigation model to optimize the patch's texture. To make the patch inconspicuous to human observers, we introduce a two-stage opacity optimization mechanism, where opacity is refined after texture optimization. Experimental results show our adversarial patches reduce navigation success rates by about 40%, outperforming previous methods in practicality, effectiveness, and naturalness. Code is available at: [https://github.com/chen37058/Physical-Attacks-in-Embodied-Navigation].