 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTDA-HSED: Mutual-Assistance Tuning and Dual-Branch Aggregating for Heterogeneous Sound Event Detection
Paper and Code
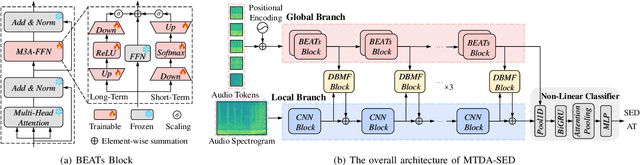
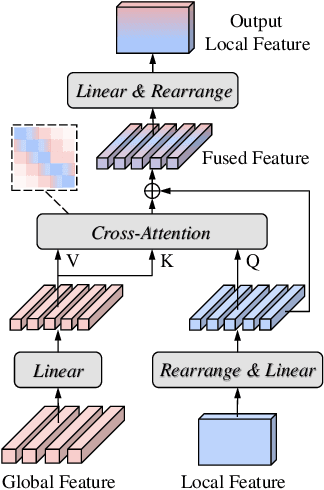
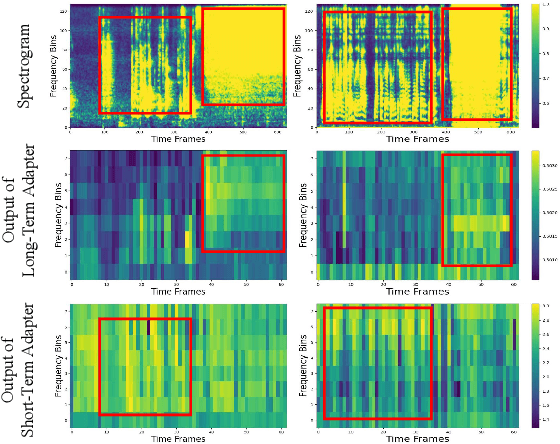
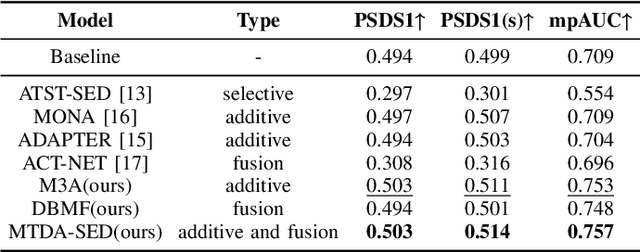
Sound Event Detection (SED) plays a vital role in comprehending and perceiving acoustic scenes. Previous methods have demonstrated impressive capabilities. However, they are deficient in learning features of complex scenes from heterogeneous dataset. In this paper, we introduce a novel dual-branch architecture named Mutual-Assistance Tuning and Dual-Branch Aggregating for Heterogeneous Sound Event Detection (MTDA-HSED). The MTDA-HSED architecture employs the Mutual-Assistance Audio Adapter (M3A) to effectively tackle the multi-scenario problem and uses the Dual-Branch Mid-Fusion (DBMF) module to tackle the multi-granularity problem. Specifically, M3A is integrated into the BEATs block as an adapter to improve the BEATs' performance by fine-tuning it on the multi-scenario dataset. The DBMF module connects BEATs and CNN branches, which facilitates the deep fusion of information from the BEATs and the CNN branches. Experimental results show that the proposed methods exceed the baseline of mpAUC by \textbf{$5\%$} on the DESED and MAESTRO Real datasets. Code is available at https://github.com/Visitor-W/MTDA.