 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2025 challenge on Text to Image Generation Model Quality Assessment
May 22, 2025This paper reports on the NTIRE 2025 challenge on Text to Image (T2I) generation model quality assessment, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2025. The aim of this challenge is to address the fine-grained quality assessment of text-to-image generation models. This challenge evaluates text-to-image models from two aspects: image-text alignment and image structural distortion detection, and is divided into the alignment track and the structural track. The alignment track uses the EvalMuse-40K, which contains around 40K AI-Generated Images (AIGIs) generated by 20 popular generative models. The alignment track has a total of 371 registered participants. A total of 1,883 submissions are received in the development phase, and 507 submissions are received in the test phase. Finally, 12 participating teams submitted their models and fact sheets. The structure track uses the EvalMuse-Structure, which contains 10,000 AI-Generated Images (AIGIs) with corresponding structural distortion mask. A total of 211 participants have registered in the structure track. A total of 1155 submissions are received in the development phase, and 487 submissions are received in the test phase. Finally, 8 participating teams submitted their models and fact sheets. Almost all methods have achieved better results than baseline methods, and the winning methods in both tracks have demonstrated superior prediction performance on T2I model quality assessment.
MTDA-HSED: Mutual-Assistance Tuning and Dual-Branch Aggregating for Heterogeneous Sound Event Detection
Sep 11, 2024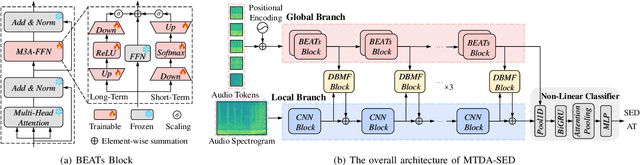
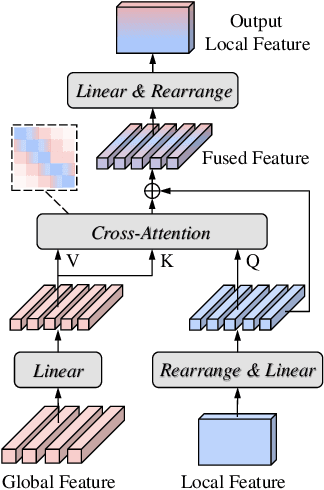
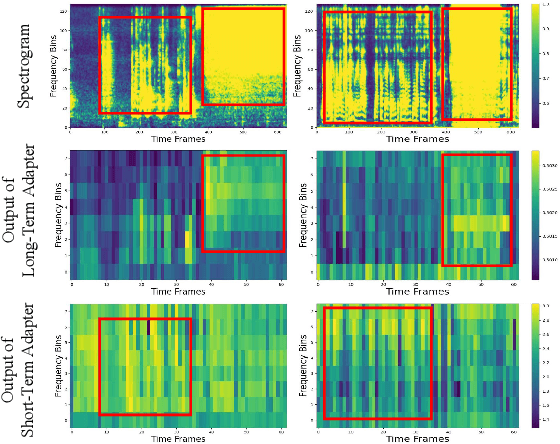
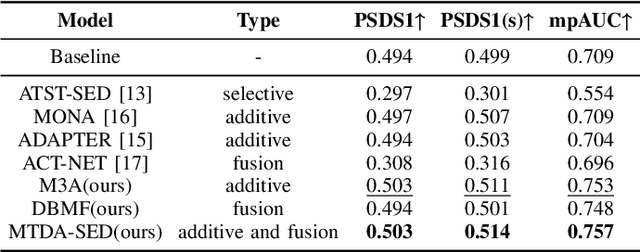
Sound Event Detection (SED) plays a vital role in comprehending and perceiving acoustic scenes. Previous methods have demonstrated impressive capabilities. However, they are deficient in learning features of complex scenes from heterogeneous dataset. In this paper, we introduce a novel dual-branch architecture named Mutual-Assistance Tuning and Dual-Branch Aggregating for Heterogeneous Sound Event Detection (MTDA-HSED). The MTDA-HSED architecture employs the Mutual-Assistance Audio Adapter (M3A) to effectively tackle the multi-scenario problem and uses the Dual-Branch Mid-Fusion (DBMF) module to tackle the multi-granularity problem. Specifically, M3A is integrated into the BEATs block as an adapter to improve the BEATs' performance by fine-tuning it on the multi-scenario dataset. The DBMF module connects BEATs and CNN branches, which facilitates the deep fusion of information from the BEATs and the CNN branches. Experimental results show that the proposed methods exceed the baseline of mpAUC by \textbf{$5\%$} on the DESED and MAESTRO Real datasets. Code is available at https://github.com/Visitor-W/MTDA.
SELD-Mamba: Selective State-Space Model for Sound Event Localization and Detection with Source Distance Estimation
Aug 09, 2024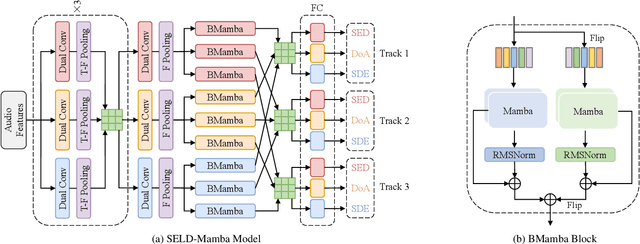

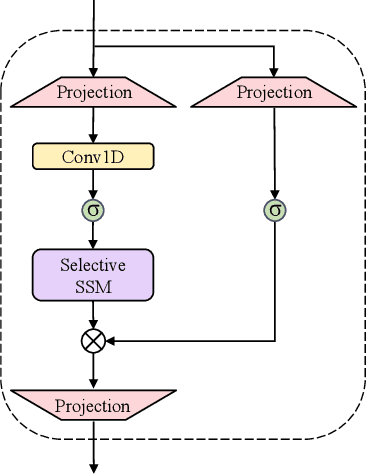

In the Sound Event Localization and Detection (SELD) task, Transformer-based models have demonstrated impressive capabilities. However, the quadratic complexity of the Transformer's self-attention mechanism results in computational inefficiencies. In this paper, we propose a network architecture for SELD called SELD-Mamba, which utilizes Mamba, a selective state-space model. We adopt the Event-Independent Network V2 (EINV2) as the foundational framework and replace its Conformer blocks with bidirectional Mamba blocks to capture a broader range of contextual information while maintaining computational efficiency. Additionally, we implement a two-stage training method, with the first stage focusing on Sound Event Detection (SED) and Direction of Arrival (DoA) estimation losses, and the second stage reintroducing the Source Distance Estimation (SDE) loss. Our experimental results on the 2024 DCASE Challenge Task3 dataset demonstrate the effectiveness of the selective state-space model in SELD and highlight the benefits of the two-stage training approach in enhancing SELD performance.
MFF-EINV2: Multi-scale Feature Fusion across Spectral-Spatial-Temporal Domains for Sound Event Localization and Detection
Jun 15, 2024



Sound Event Localization and Detection (SELD) involves detecting and localizing sound events using multichannel sound recordings. Previously proposed Event-Independent Network V2 (EINV2) has achieved outstanding performance on SELD. However, it still faces challenges in effectively extracting features across spectral, spatial, and temporal domains. This paper proposes a three-stage network structure named Multi-scale Feature Fusion (MFF) module to fully extract multi-scale features across spectral, spatial, and temporal domains. The MFF module utilizes parallel subnetworks architecture to generate multi-scale spectral and spatial features. The TF-Convolution Module is employed to provide multi-scale temporal features. We incorporated MFF into EINV2 and term the proposed method as MFF-EINV2. Experimental results in 2022 and 2023 DCASE challenge task3 datasets show the effectiveness of our MFF-EINV2, which achieves state-of-the-art (SOTA) performance compared to published methods.
Full-frequency dynamic convolution: a physical frequency-dependent convolution for sound event detection
Jan 10, 2024



Recently, 2D convolution has been found unqualified in sound event detection (SED). It enforces translation equivariance on sound events along frequency axis, which is not a shift-invariant dimension. To address this issue, dynamic convolution is used to model the frequency dependency of sound events. In this paper, we proposed the first full-dynamic method named \emph{full-frequency dynamic convolution} (FFDConv). FFDConv generates frequency kernels for every frequency band, which is designed directly in the structure for frequency-dependent modeling. It physically furnished 2D convolution with the capability of frequency-dependent modeling. FFDConv outperforms not only the baseline by 6.6\% in DESED real validation dataset in terms of PSDS1, but outperforms the other full-dynamic methods. In addition, by visualizing features of sound events, we observed that FFDConv could effectively extract coherent features in specific frequency bands, consistent with the vocal continuity of sound events. This proves that FFDConv has great frequency-dependent perception ability.