 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeL2HCount:Generalizing Crowd Counting from Low to High Crowd Density via Density Simulation
Mar 17, 2025Since COVID-19, crowd-counting tasks have gained wide applications. While supervised methods are reliable, annotation is more challenging in high-density scenes due to small head sizes and severe occlusion, whereas it's simpler in low-density scenes. Interestingly, can we train the model in low-density scenes and generalize it to high-density scenes? Therefore, we propose a low- to high-density generalization framework (L2HCount) that learns the pattern related to high-density scenes from low-density ones, enabling it to generalize well to high-density scenes. Specifically, we first introduce a High-Density Simulation Module and a Ground-Truth Generation Module to construct fake high-density images along with their corresponding ground-truth crowd annotations respectively by image-shifting technique, effectively simulating high-density crowd patterns. However, the simulated images have two issues: image blurring and loss of low-density image characteristics. Therefore, we second propose a Head Feature Enhancement Module to extract clear features in the simulated high-density scene. Third, we propose a Dual-Density Memory Encoding Module that uses two crowd memories to learn scene-specific patterns from low- and simulated high-density scenes, respectively. Extensive experiments on four challenging datasets have shown the promising performance of L2HCount.
GaussianCAD: Robust Self-Supervised CAD Reconstruction from Three Orthographic Views Using 3D Gaussian Splatting
Mar 07, 2025



The automatic reconstruction of 3D computer-aided design (CAD) models from CAD sketches has recently gained significant attention in the computer vision community. Most existing methods, however, rely on vector CAD sketches and 3D ground truth for supervision, which are often difficult to be obtained in industrial applications and are sensitive to noise inputs. We propose viewing CAD reconstruction as a specific instance of sparse-view 3D reconstruction to overcome these limitations. While this reformulation offers a promising perspective, existing 3D reconstruction methods typically require natural images and corresponding camera poses as inputs, which introduces two major significant challenges: (1) modality discrepancy between CAD sketches and natural images, and (2) difficulty of accurate camera pose estimation for CAD sketches. To solve these issues, we first transform the CAD sketches into representations resembling natural images and extract corresponding masks. Next, we manually calculate the camera poses for the orthographic views to ensure accurate alignment within the 3D coordinate system. Finally, we employ a customized sparse-view 3D reconstruction method to achieve high-quality reconstructions from aligned orthographic views. By leveraging raster CAD sketches for self-supervision, our approach eliminates the reliance on vector CAD sketches and 3D ground truth. Experiments on the Sub-Fusion360 dataset demonstrate that our proposed method significantly outperforms previous approaches in CAD reconstruction performance and exhibits strong robustness to noisy inputs.
QUART-Online: Latency-Free Large Multimodal Language Model for Quadruped Robot Learning
Dec 23, 2024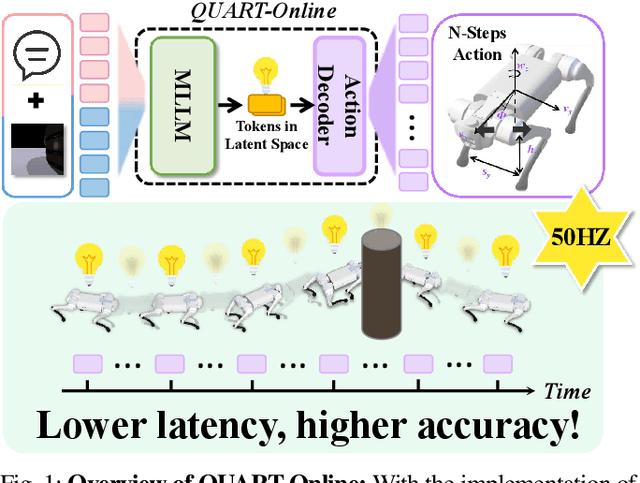
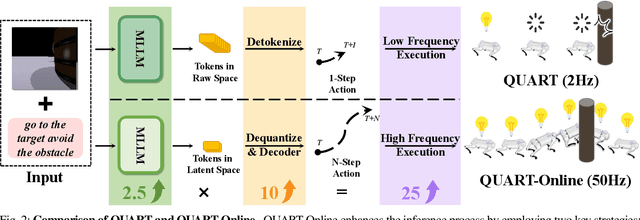
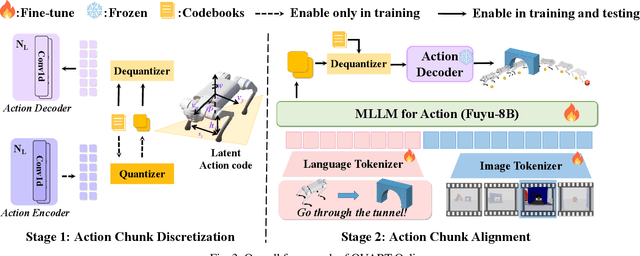
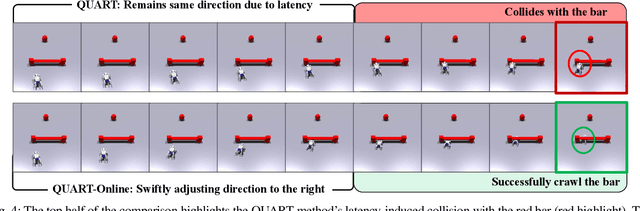
This paper addresses the inherent inference latency challenges associated with deploying multimodal large language models (MLLM) in quadruped vision-language-action (QUAR-VLA) tasks. Our investigation reveals that conventional parameter reduction techniques ultimately impair the performance of the language foundation model during the action instruction tuning phase, making them unsuitable for this purpose. We introduce a novel latency-free quadruped MLLM model, dubbed QUART-Online, designed to enhance inference efficiency without degrading the performance of the language foundation model. By incorporating Action Chunk Discretization (ACD), we compress the original action representation space, mapping continuous action values onto a smaller set of discrete representative vectors while preserving critical information. Subsequently, we fine-tune the MLLM to integrate vision, language, and compressed actions into a unified semantic space. Experimental results demonstrate that QUART-Online operates in tandem with the existing MLLM system, achieving real-time inference in sync with the underlying controller frequency, significantly boosting the success rate across various tasks by 65%. Our project page is https://quart-online.github.io.
MamKPD: A Simple Mamba Baseline for Real-Time 2D Keypoint Detection
Dec 02, 2024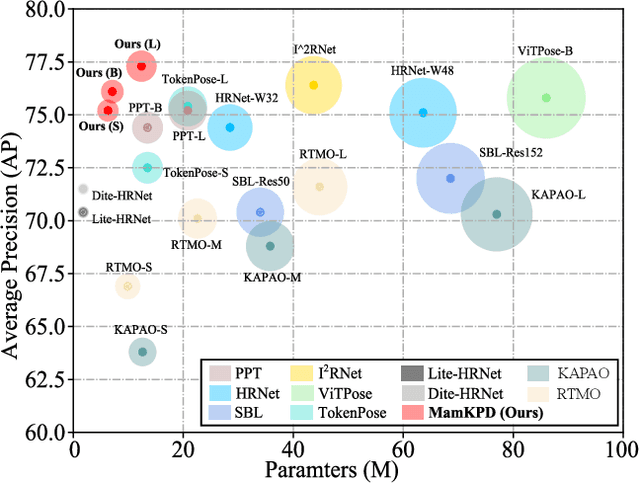
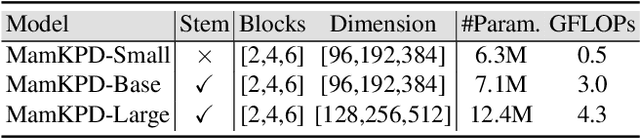
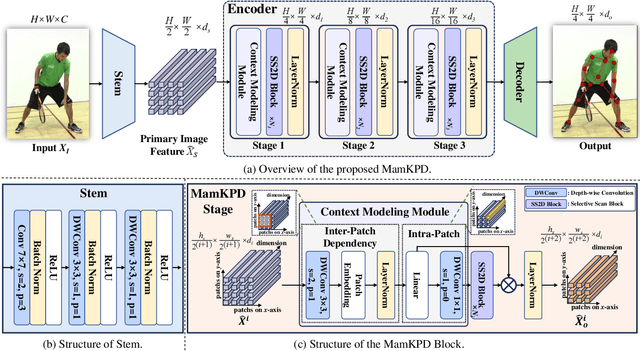
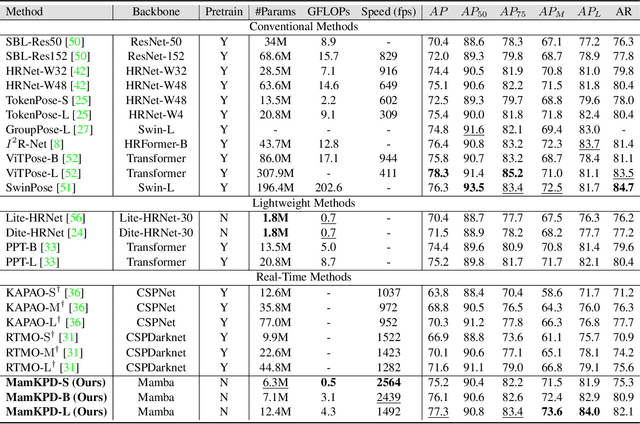
Real-time 2D keypoint detection plays an essential role in computer vision. Although CNN-based and Transformer-based methods have achieved breakthrough progress, they often fail to deliver superior performance and real-time speed. This paper introduces MamKPD, the first efficient yet effective mamba-based pose estimation framework for 2D keypoint detection. The conventional Mamba module exhibits limited information interaction between patches. To address this, we propose a lightweight contextual modeling module (CMM) that uses depth-wise convolutions to model inter-patch dependencies and linear layers to distill the pose cues within each patch. Subsequently, by combining Mamba for global modeling across all patches, MamKPD effectively extracts instances' pose information. We conduct extensive experiments on human and animal pose estimation datasets to validate the effectiveness of MamKPD. Our MamKPD-L achieves 77.3% AP on the COCO dataset with 1492 FPS on an NVIDIA GTX 4090 GPU. Moreover, MamKPD achieves state-of-the-art results on the MPII dataset and competitive results on the AP-10K dataset while saving 85% of the parameters compared to ViTPose. Our project page is available at https://mamkpd.github.io/.
Towards Physically-Realizable Adversarial Attacks in Embodied Vision Navigation
Sep 16, 2024
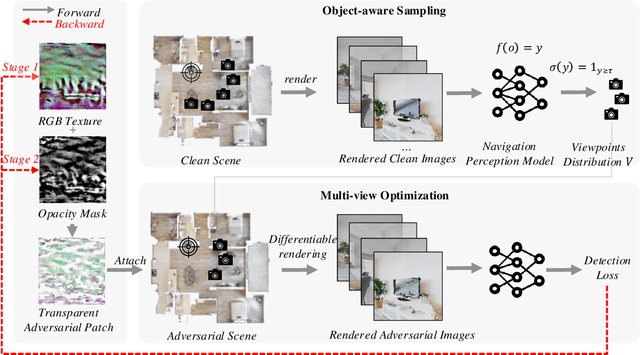

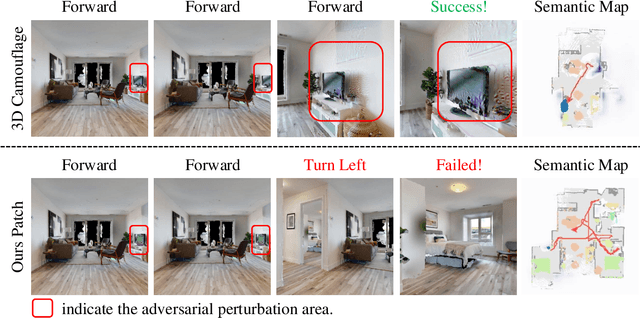
The deployment of embodied navigation agents in safety-critical environments raises concerns about their vulnerability to adversarial attacks on deep neural networks. However, current attack methods often lack practicality due to challenges in transitioning from the digital to the physical world, while existing physical attacks for object detection fail to achieve both multi-view effectiveness and naturalness. To address this, we propose a practical attack method for embodied navigation by attaching adversarial patches with learnable textures and opacity to objects. Specifically, to ensure effectiveness across varying viewpoints, we employ a multi-view optimization strategy based on object-aware sampling, which uses feedback from the navigation model to optimize the patch's texture. To make the patch inconspicuous to human observers, we introduce a two-stage opacity optimization mechanism, where opacity is refined after texture optimization. Experimental results show our adversarial patches reduce navigation success rates by about 40%, outperforming previous methods in practicality, effectiveness, and naturalness. Code is available at: [https://github.com/chen37058/Physical-Attacks-in-Embodied-Navigation].
ActivityCLIP: Enhancing Group Activity Recognition by Mining Complementary Information from Text to Supplement Image Modality
Jul 29, 2024



Previous methods usually only extract the image modality's information to recognize group activity. However, mining image information is approaching saturation, making it difficult to extract richer information. Therefore, extracting complementary information from other modalities to supplement image information has become increasingly important. In fact, action labels provide clear text information to express the action's semantics, which existing methods often overlook. Thus, we propose ActivityCLIP, a plug-and-play method for mining the text information contained in the action labels to supplement the image information for enhancing group activity recognition. ActivityCLIP consists of text and image branches, where the text branch is plugged into the image branch (The off-the-shelf image-based method). The text branch includes Image2Text and relation modeling modules. Specifically, we propose the knowledge transfer module, Image2Text, which adapts image information into text information extracted by CLIP via knowledge distillation. Further, to keep our method convenient, we add fewer trainable parameters based on the relation module of the image branch to model interaction relation in the text branch. To show our method's generality, we replicate three representative methods by ActivityCLIP, which adds only limited trainable parameters, achieving favorable performance improvements for each method. We also conduct extensive ablation studies and compare our method with state-of-the-art methods to demonstrate the effectiveness of ActivityCLIP.
Micro-expression recognition based on depth map to point cloud
Jun 12, 2024Micro-expressions are nonverbal facial expressions that reveal the covert emotions of individuals, making the micro-expression recognition task receive widespread attention. However, the micro-expression recognition task is challenging due to the subtle facial motion and brevity in duration. Many 2D image-based methods have been developed in recent years to recognize MEs effectively, but, these approaches are restricted by facial texture information and are susceptible to environmental factors, such as lighting. Conversely, depth information can effectively represent motion information related to facial structure changes and is not affected by lighting. Motion information derived from facial structures can describe motion features that pixel textures cannot delineate. We proposed a network for micro-expression recognition based on facial depth information, and our experiments have demonstrated the crucial role of depth maps in the micro-expression recognition task. Initially, we transform the depth map into a point cloud and obtain the motion information for each point by aligning the initiating frame with the apex frame and performing a differential operation. Subsequently, we adjusted all point cloud motion feature input dimensions and used them as inputs for multiple point cloud networks to assess the efficacy of this representation. PointNet++ was chosen as the ultimate outcome for micro-expression recognition due to its superior performance. Our experiments show that our proposed method significantly outperforms the existing deep learning methods, including the baseline, on the $CAS(ME)^3$ dataset, which includes depth information.
DHRNet: A Dual-Path Hierarchical Relation Network for Multi-Person Pose Estimation
Apr 27, 2024


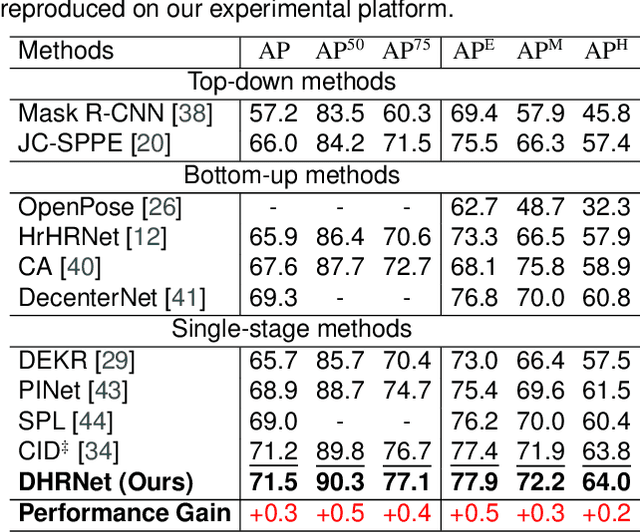
Multi-person pose estimation (MPPE) presents a formidable yet crucial challenge in computer vision. Most existing methods predominantly concentrate on isolated interaction either between instances or joints, which is inadequate for scenarios demanding concurrent localization of both instances and joints. This paper introduces a novel CNN-based single-stage method, named Dual-path Hierarchical Relation Network (DHRNet), to extract instance-to-joint and joint-to-instance interactions concurrently. Specifically, we design a dual-path interaction modeling module (DIM) that strategically organizes cross-instance and cross-joint interaction modeling modules in two complementary orders, enriching interaction information by integrating merits from different correlation modeling branches. Notably, DHRNet excels in joint localization by leveraging information from other instances and joints. Extensive evaluations on challenging datasets, including COCO, CrowdPose, and OCHuman datasets, showcase DHRNet's state-of-the-art performance. The code will be released at https://github.com/YHDang/dhrnet-multi-pose-estimation.
Full-frequency dynamic convolution: a physical frequency-dependent convolution for sound event detection
Jan 10, 2024



Recently, 2D convolution has been found unqualified in sound event detection (SED). It enforces translation equivariance on sound events along frequency axis, which is not a shift-invariant dimension. To address this issue, dynamic convolution is used to model the frequency dependency of sound events. In this paper, we proposed the first full-dynamic method named \emph{full-frequency dynamic convolution} (FFDConv). FFDConv generates frequency kernels for every frequency band, which is designed directly in the structure for frequency-dependent modeling. It physically furnished 2D convolution with the capability of frequency-dependent modeling. FFDConv outperforms not only the baseline by 6.6\% in DESED real validation dataset in terms of PSDS1, but outperforms the other full-dynamic methods. In addition, by visualizing features of sound events, we observed that FFDConv could effectively extract coherent features in specific frequency bands, consistent with the vocal continuity of sound events. This proves that FFDConv has great frequency-dependent perception ability.
Spatial-Temporal Decoupling Contrastive Learning for Skeleton-based Human Action Recognition
Jan 09, 2024Skeleton-based action recognition is a central task of human-computer interaction. However, most of the previous methods suffer from two issues: (i) semantic ambiguity arising from spatiotemporal information mixture; and (ii) overlooking the explicit exploitation of the latent data distributions (i.e., the intra-class variations and inter-class relations), thereby leading to local optimum solutions of the skeleton encoders. To mitigate this, we propose a spatial-temporal decoupling contrastive learning (STD-CL) framework to obtain discriminative and semantically distinct representations from the sequences, which can be incorporated into almost all previous skeleton encoders and have no impact on the skeleton encoders when testing. Specifically, we decouple the global features into spatial-specific and temporal-specific features to reduce the spatiotemporal coupling of features. Furthermore, to explicitly exploit the latent data distributions, we employ the attentive features to contrastive learning, which models the cross-sequence semantic relations by pulling together the features from the positive pairs and pushing away the negative pairs. Extensive experiments show that STD-CL with four various skeleton encoders (HCN, 2S-AGCN, CTR-GCN, and Hyperformer) achieves solid improvement on NTU60, NTU120, and NW-UCLA benchmarks. The code will be released.