 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting the Class-Incremental Learning in 3D Point Clouds via Zero-Collection-Cost Basic Shape Pre-Training
Apr 11, 2025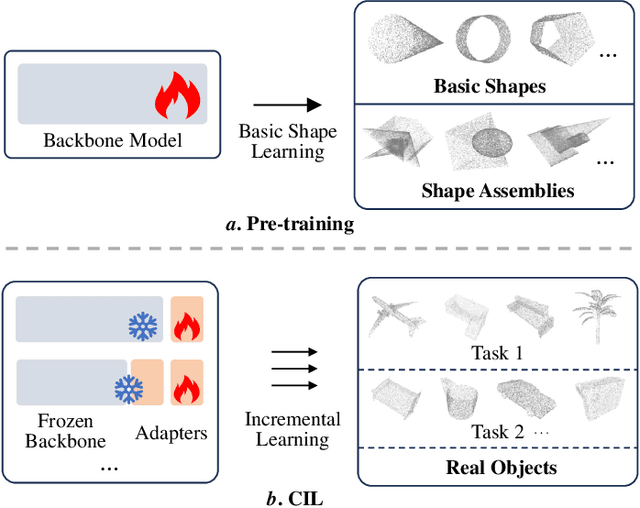
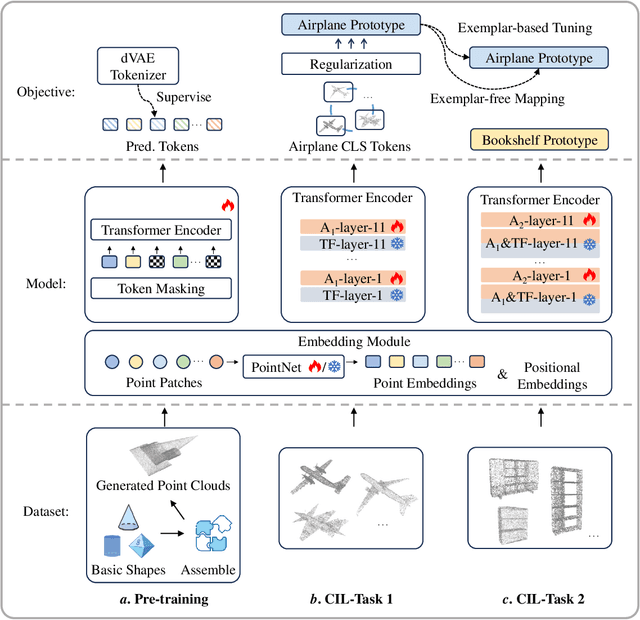
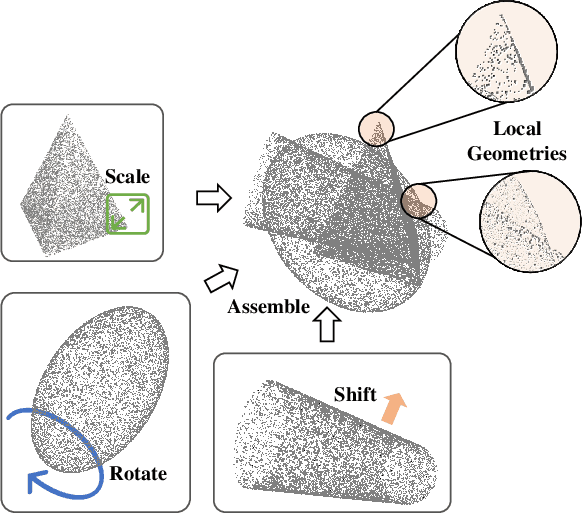
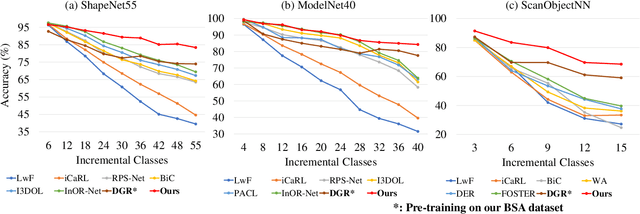
Existing class-incremental learning methods in 3D point clouds rely on exemplars (samples of former classes) to resist the catastrophic forgetting of models, and exemplar-free settings will greatly degrade the performance. For exemplar-free incremental learning, the pre-trained model methods have achieved state-of-the-art results in 2D domains. However, these methods cannot be migrated to the 3D domains due to the limited pre-training datasets and insufficient focus on fine-grained geometric details. This paper breaks through these limitations, proposing a basic shape dataset with zero collection cost for model pre-training. It helps a model obtain extensive knowledge of 3D geometries. Based on this, we propose a framework embedded with 3D geometry knowledge for incremental learning in point clouds, compatible with exemplar-free (-based) settings. In the incremental stage, the geometry knowledge is extended to represent objects in point clouds. The class prototype is calculated by regularizing the data representation with the same category and is kept adjusting in the learning process. It helps the model remember the shape features of different categories. Experiments show that our method outperforms other baseline methods by a large margin on various benchmark datasets, considering both exemplar-free (-based) settings.
CMIP-CIL: A Cross-Modal Benchmark for Image-Point Class Incremental Learning
Apr 11, 2025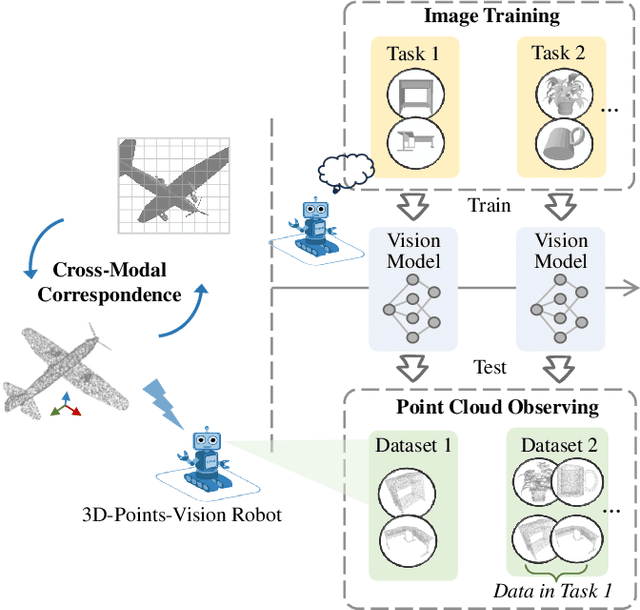
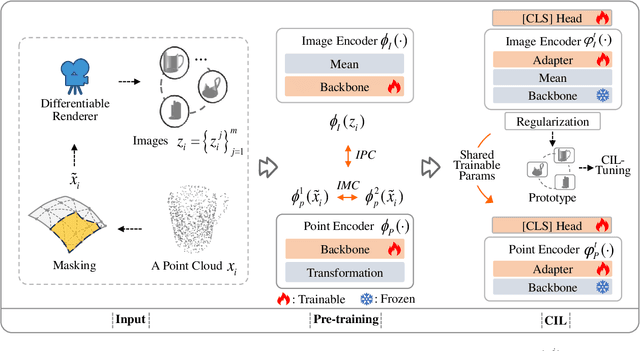
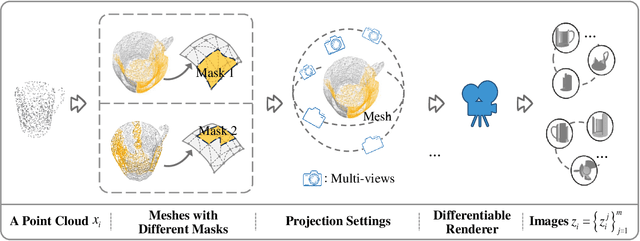
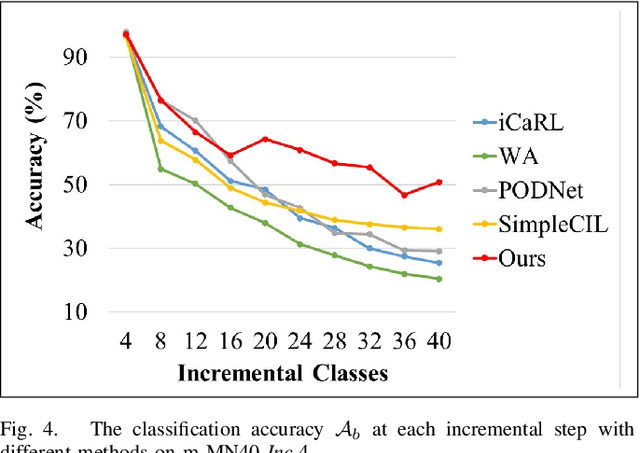
Image-point class incremental learning helps the 3D-points-vision robots continually learn category knowledge from 2D images, improving their perceptual capability in dynamic environments. However, some incremental learning methods address unimodal forgetting but fail in cross-modal cases, while others handle modal differences within training/testing datasets but assume no modal gaps between them. We first explore this cross-modal task, proposing a benchmark CMIP-CIL and relieving the cross-modal catastrophic forgetting problem. It employs masked point clouds and rendered multi-view images within a contrastive learning framework in pre-training, empowering the vision model with the generalizations of image-point correspondence. In the incremental stage, by freezing the backbone and promoting object representations close to their respective prototypes, the model effectively retains and generalizes knowledge across previously seen categories while continuing to learn new ones. We conduct comprehensive experiments on the benchmark datasets. Experiments prove that our method achieves state-of-the-art results, outperforming the baseline methods by a large margin.
Towards Physically-Realizable Adversarial Attacks in Embodied Vision Navigation
Sep 16, 2024
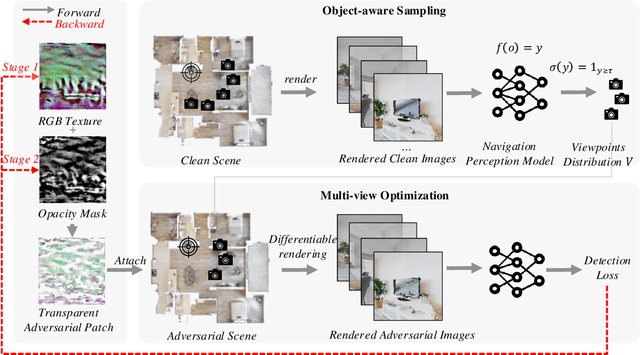

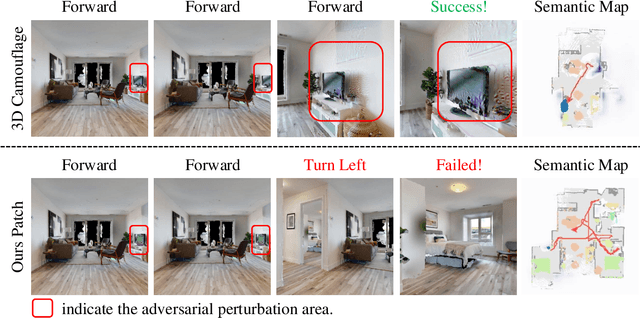
The deployment of embodied navigation agents in safety-critical environments raises concerns about their vulnerability to adversarial attacks on deep neural networks. However, current attack methods often lack practicality due to challenges in transitioning from the digital to the physical world, while existing physical attacks for object detection fail to achieve both multi-view effectiveness and naturalness. To address this, we propose a practical attack method for embodied navigation by attaching adversarial patches with learnable textures and opacity to objects. Specifically, to ensure effectiveness across varying viewpoints, we employ a multi-view optimization strategy based on object-aware sampling, which uses feedback from the navigation model to optimize the patch's texture. To make the patch inconspicuous to human observers, we introduce a two-stage opacity optimization mechanism, where opacity is refined after texture optimization. Experimental results show our adversarial patches reduce navigation success rates by about 40%, outperforming previous methods in practicality, effectiveness, and naturalness. Code is available at: [https://github.com/chen37058/Physical-Attacks-in-Embodied-Navigation].
Micro-expression recognition based on depth map to point cloud
Jun 12, 2024Micro-expressions are nonverbal facial expressions that reveal the covert emotions of individuals, making the micro-expression recognition task receive widespread attention. However, the micro-expression recognition task is challenging due to the subtle facial motion and brevity in duration. Many 2D image-based methods have been developed in recent years to recognize MEs effectively, but, these approaches are restricted by facial texture information and are susceptible to environmental factors, such as lighting. Conversely, depth information can effectively represent motion information related to facial structure changes and is not affected by lighting. Motion information derived from facial structures can describe motion features that pixel textures cannot delineate. We proposed a network for micro-expression recognition based on facial depth information, and our experiments have demonstrated the crucial role of depth maps in the micro-expression recognition task. Initially, we transform the depth map into a point cloud and obtain the motion information for each point by aligning the initiating frame with the apex frame and performing a differential operation. Subsequently, we adjusted all point cloud motion feature input dimensions and used them as inputs for multiple point cloud networks to assess the efficacy of this representation. PointNet++ was chosen as the ultimate outcome for micro-expression recognition due to its superior performance. Our experiments show that our proposed method significantly outperforms the existing deep learning methods, including the baseline, on the $CAS(ME)^3$ dataset, which includes depth information.
Instance-incremental Scene Graph Generation from Real-world Point Clouds via Normalizing Flows
Feb 21, 2023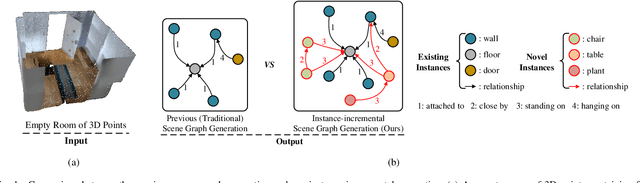
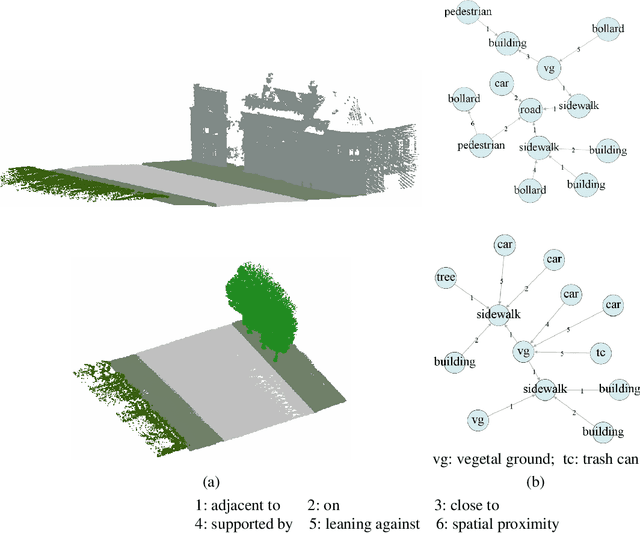
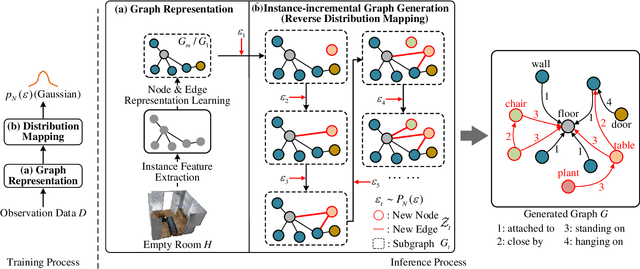
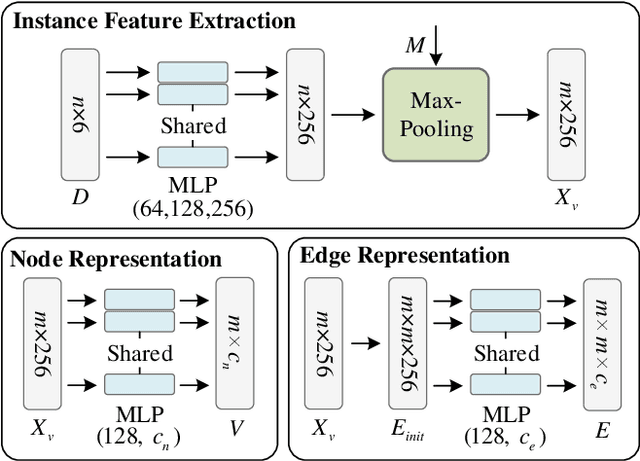
This work introduces a new task of instance-incremental scene graph generation: Given an empty room of the point cloud, representing it as a graph and automatically increasing novel instances. A graph denoting the object layout of the scene is finally generated. It is an important task since it helps to guide the insertion of novel 3D objects into a real-world scene in vision-based applications like augmented reality. It is also challenging because the complexity of the real-world point cloud brings difficulties in learning object layout experiences from the observation data (non-empty rooms with labeled semantics). We model this task as a conditional generation problem and propose a 3D autoregressive framework based on normalizing flows (3D-ANF) to address it. We first represent the point cloud as a graph by extracting the containing label semantics and contextual relationships. Next, a model based on normalizing flows is introduced to map the conditional generation of graphic elements into the Gaussian process. The mapping is invertible. Thus, the real-world experiences represented in the observation data can be modeled in the training phase, and novel instances can be sequentially generated based on the Gaussian process in the testing phase. We implement this new task on the dataset of 3D point-based scenes (3DSSG and 3RScan) and evaluate the performance of our method. Experiments show that our method generates reliable novel graphs from the real-world point cloud and achieves state-of-the-art performance on the benchmark dataset.
In-field early disease recognition of potato late blight based on deep learning and proximal hyperspectral imaging
Nov 23, 2021
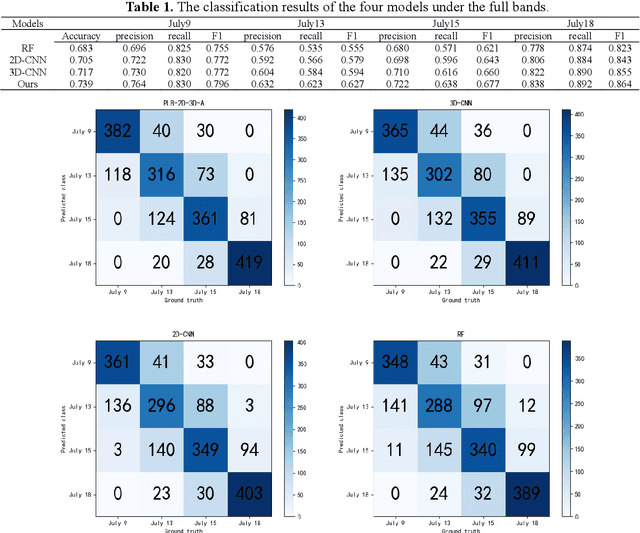

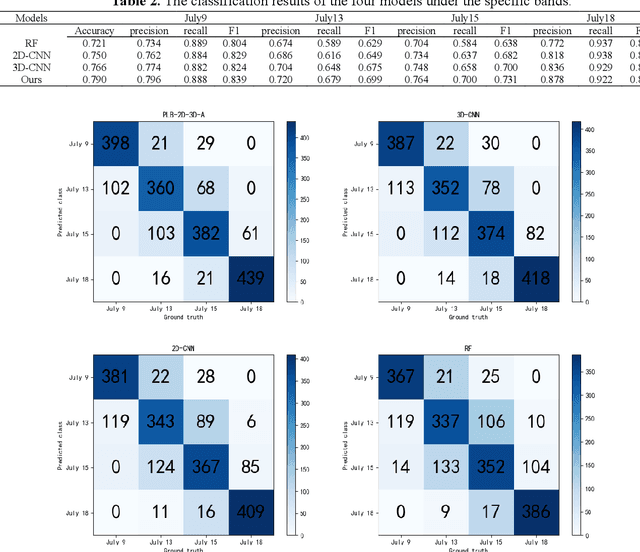
Effective early detection of potato late blight (PLB) is an essential aspect of potato cultivation. However, it is a challenge to detect late blight at an early stage in fields with conventional imaging approaches because of the lack of visual cues displayed at the canopy level. Hyperspectral imaging can, capture spectral signals from a wide range of wavelengths also outside the visual wavelengths. In this context, we propose a deep learning classification architecture for hyperspectral images by combining 2D convolutional neural network (2D-CNN) and 3D-CNN with deep cooperative attention networks (PLB-2D-3D-A). First, 2D-CNN and 3D-CNN are used to extract rich spectral space features, and then the attention mechanism AttentionBlock and SE-ResNet are used to emphasize the salient features in the feature maps and increase the generalization ability of the model. The dataset is built with 15,360 images (64x64x204), cropped from 240 raw images captured in an experimental field with over 20 potato genotypes. The accuracy in the test dataset of 2000 images reached 0.739 in the full band and 0.790 in the specific bands (492nm, 519nm, 560nm, 592nm, 717nm and 765nm). This study shows an encouraging result for early detection of PLB with deep learning and proximal hyperspectral imaging.
Tea Chrysanthemum Detection under Unstructured Environments Using the TC-YOLO Model
Nov 04, 2021

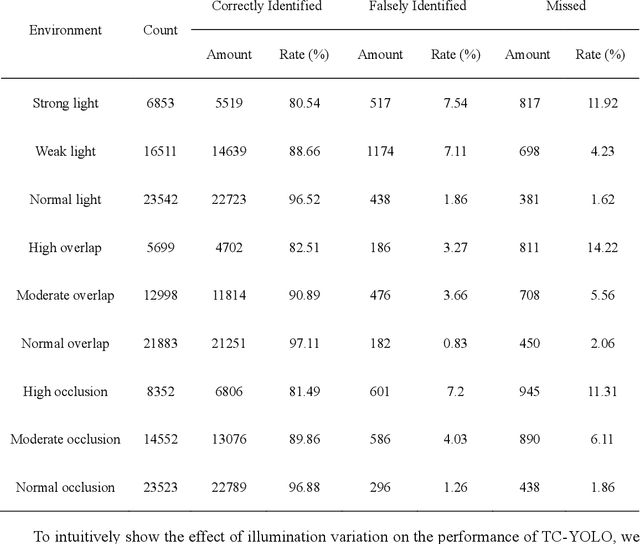
Tea chrysanthemum detection at its flowering stage is one of the key components for selective chrysanthemum harvesting robot development. However, it is a challenge to detect flowering chrysanthemums under unstructured field environments given the variations on illumination, occlusion and object scale. In this context, we propose a highly fused and lightweight deep learning architecture based on YOLO for tea chrysanthemum detection (TC-YOLO). First, in the backbone component and neck component, the method uses the Cross-Stage Partially Dense Network (CSPDenseNet) as the main network, and embeds custom feature fusion modules to guide the gradient flow. In the final head component, the method combines the recursive feature pyramid (RFP) multiscale fusion reflow structure and the Atrous Spatial Pyramid Pool (ASPP) module with cavity convolution to achieve the detection task. The resulting model was tested on 300 field images, showing that under the NVIDIA Tesla P100 GPU environment, if the inference speed is 47.23 FPS for each image (416 * 416), TC-YOLO can achieve the average precision (AP) of 92.49% on our own tea chrysanthemum dataset. In addition, this method (13.6M) can be deployed on a single mobile GPU, and it could be further developed as a perception system for a selective chrysanthemum harvesting robot in the future.
Representation Learning-Assisted Click-Through Rate Prediction
Jul 19, 2019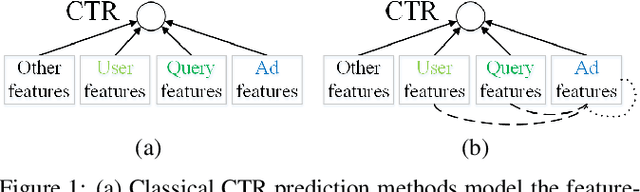
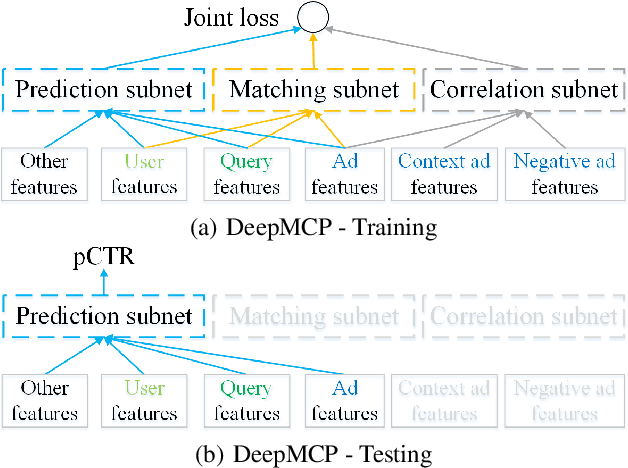
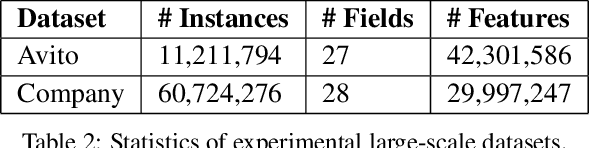
Click-through rate (CTR) prediction is a critical task in online advertising systems. Most existing methods mainly model the feature-CTR relationship and suffer from the data sparsity issue. In this paper, we propose DeepMCP, which models other types of relationships in order to learn more informative and statistically reliable feature representations, and in consequence to improve the performance of CTR prediction. In particular, DeepMCP contains three parts: a matching subnet, a correlation subnet and a prediction subnet. These subnets model the user-ad, ad-ad and feature-CTR relationship respectively. When these subnets are jointly optimized under the supervision of the target labels, the learned feature representations have both good prediction powers and good representation abilities. Experiments on two large-scale datasets demonstrate that DeepMCP outperforms several state-of-the-art models for CTR prediction.