 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCMIP-CIL: A Cross-Modal Benchmark for Image-Point Class Incremental Learning
Paper and Code
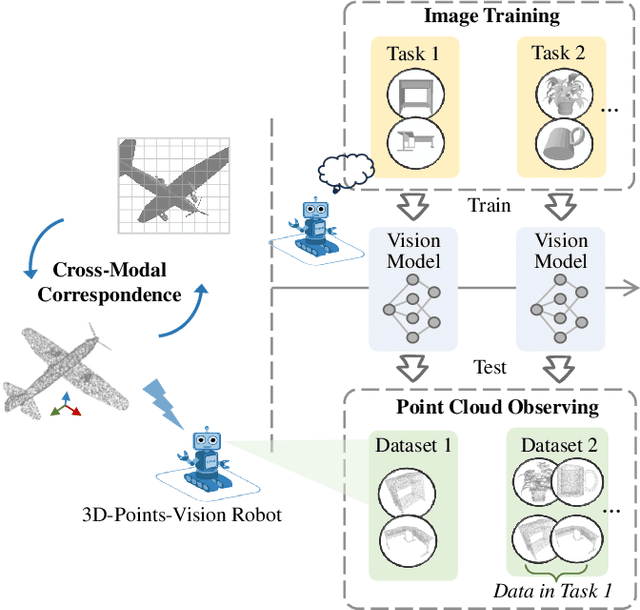
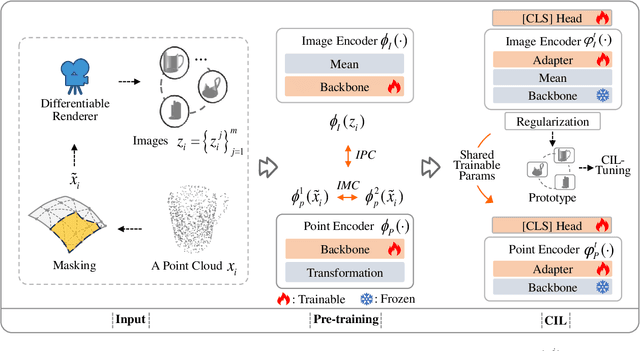
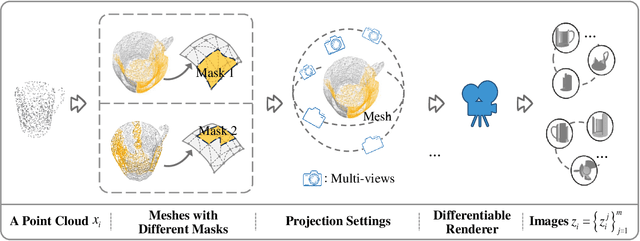
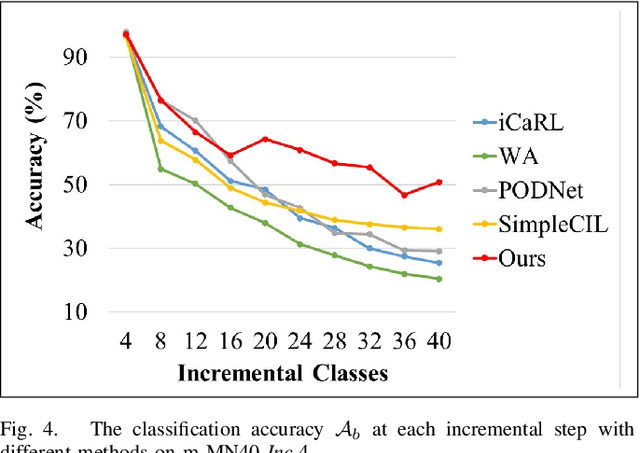
Image-point class incremental learning helps the 3D-points-vision robots continually learn category knowledge from 2D images, improving their perceptual capability in dynamic environments. However, some incremental learning methods address unimodal forgetting but fail in cross-modal cases, while others handle modal differences within training/testing datasets but assume no modal gaps between them. We first explore this cross-modal task, proposing a benchmark CMIP-CIL and relieving the cross-modal catastrophic forgetting problem. It employs masked point clouds and rendered multi-view images within a contrastive learning framework in pre-training, empowering the vision model with the generalizations of image-point correspondence. In the incremental stage, by freezing the backbone and promoting object representations close to their respective prototypes, the model effectively retains and generalizes knowledge across previously seen categories while continuing to learn new ones. We conduct comprehensive experiments on the benchmark datasets. Experiments prove that our method achieves state-of-the-art results, outperforming the baseline methods by a large margin.