 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDEFT-LLM: Disentangled Expert Feature Tuning for Micro-Expression Recognition
Nov 14, 2025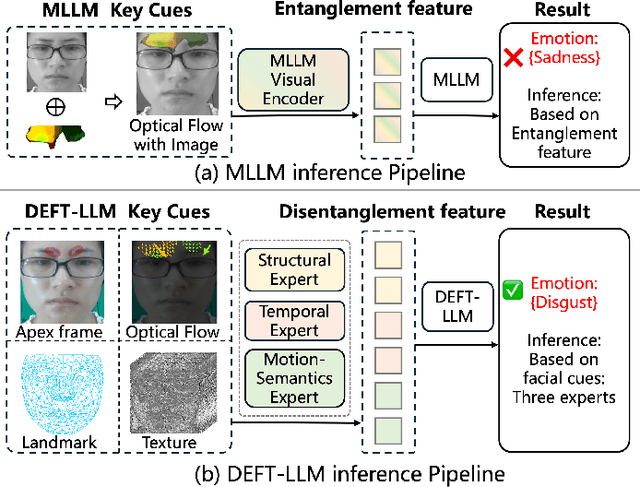
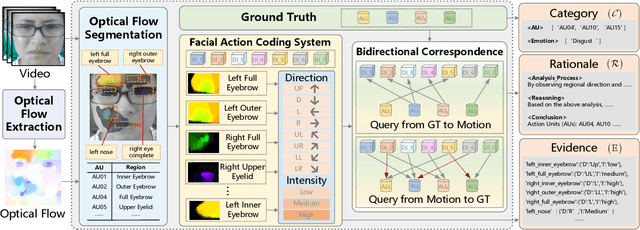
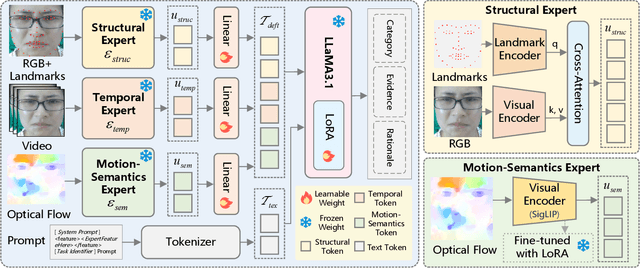
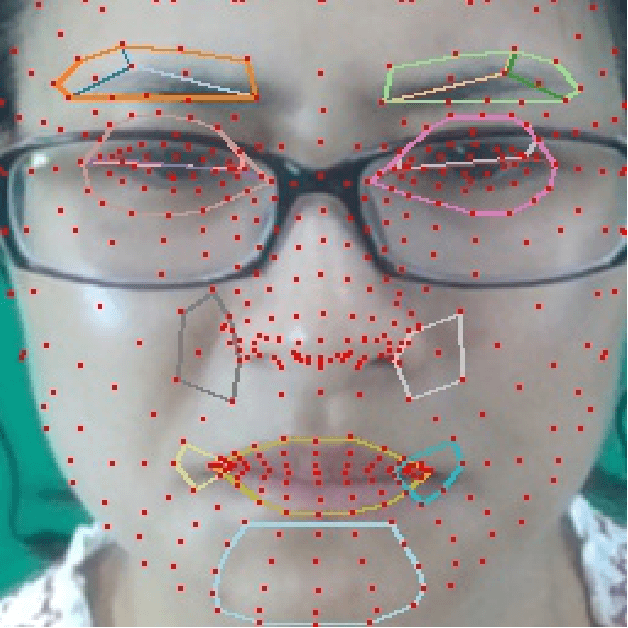
Micro expression recognition (MER) is crucial for inferring genuine emotion. Applying a multimodal large language model (MLLM) to this task enables spatio-temporal analysis of facial motion and provides interpretable descriptions. However, there are still two core challenges: (1) The entanglement of static appearance and dynamic motion cues prevents the model from focusing on subtle motion; (2) Textual labels in existing MER datasets do not fully correspond to underlying facial muscle movements, creating a semantic gap between text supervision and physical motion. To address these issues, we propose DEFT-LLM, which achieves motion semantic alignment by multi-expert disentanglement. We first introduce Uni-MER, a motion-driven instruction dataset designed to align text with local facial motion. Its construction leverages dual constraints from optical flow and Action Unit (AU) labels to ensure spatio-temporal consistency and reasonable correspondence to the movements. We then design an architecture with three experts to decouple facial dynamics into independent and interpretable representations (structure, dynamic textures, and motion-semantics). By integrating the instruction-aligned knowledge from Uni-MER into DEFT-LLM, our method injects effective physical priors for micro expressions while also leveraging the cross modal reasoning ability of large language models, thus enabling precise capture of subtle emotional cues. Experiments on multiple challenging MER benchmarks demonstrate state-of-the-art performance, as well as a particular advantage in interpretable modeling of local facial motion.
CMIP-CIL: A Cross-Modal Benchmark for Image-Point Class Incremental Learning
Apr 11, 2025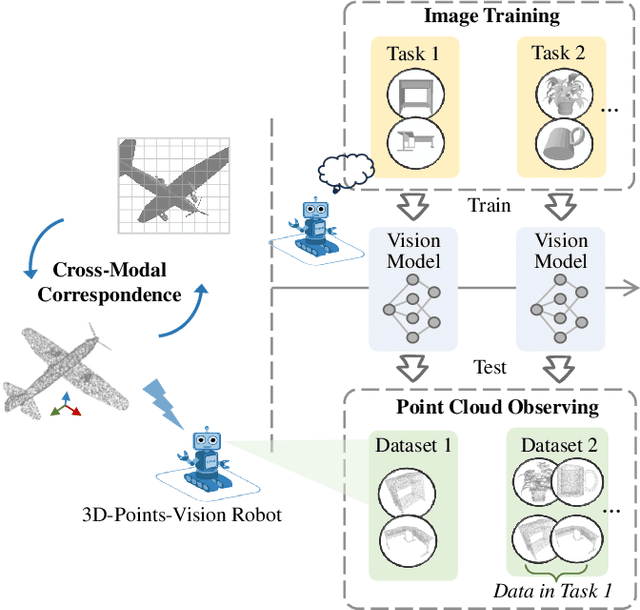
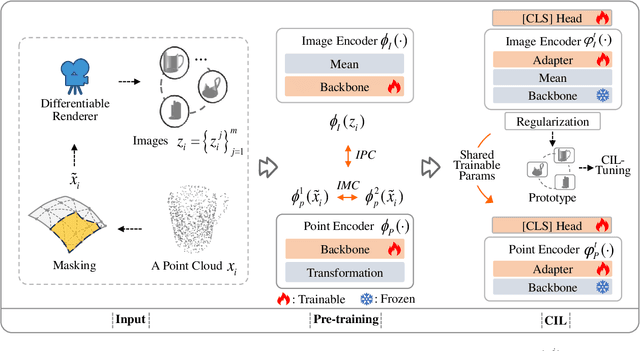
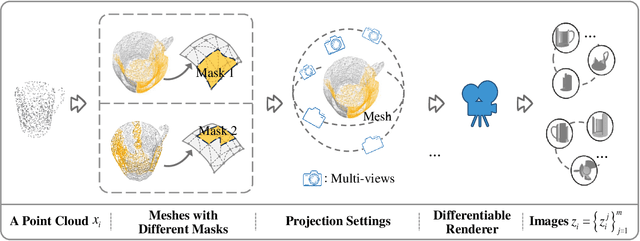
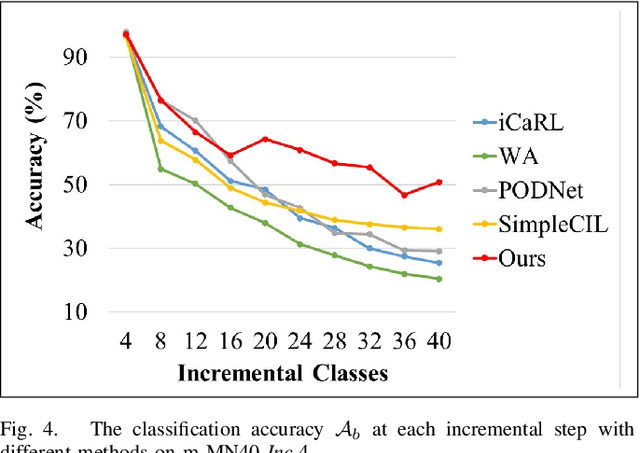
Image-point class incremental learning helps the 3D-points-vision robots continually learn category knowledge from 2D images, improving their perceptual capability in dynamic environments. However, some incremental learning methods address unimodal forgetting but fail in cross-modal cases, while others handle modal differences within training/testing datasets but assume no modal gaps between them. We first explore this cross-modal task, proposing a benchmark CMIP-CIL and relieving the cross-modal catastrophic forgetting problem. It employs masked point clouds and rendered multi-view images within a contrastive learning framework in pre-training, empowering the vision model with the generalizations of image-point correspondence. In the incremental stage, by freezing the backbone and promoting object representations close to their respective prototypes, the model effectively retains and generalizes knowledge across previously seen categories while continuing to learn new ones. We conduct comprehensive experiments on the benchmark datasets. Experiments prove that our method achieves state-of-the-art results, outperforming the baseline methods by a large margin.
L2HCount:Generalizing Crowd Counting from Low to High Crowd Density via Density Simulation
Mar 17, 2025Since COVID-19, crowd-counting tasks have gained wide applications. While supervised methods are reliable, annotation is more challenging in high-density scenes due to small head sizes and severe occlusion, whereas it's simpler in low-density scenes. Interestingly, can we train the model in low-density scenes and generalize it to high-density scenes? Therefore, we propose a low- to high-density generalization framework (L2HCount) that learns the pattern related to high-density scenes from low-density ones, enabling it to generalize well to high-density scenes. Specifically, we first introduce a High-Density Simulation Module and a Ground-Truth Generation Module to construct fake high-density images along with their corresponding ground-truth crowd annotations respectively by image-shifting technique, effectively simulating high-density crowd patterns. However, the simulated images have two issues: image blurring and loss of low-density image characteristics. Therefore, we second propose a Head Feature Enhancement Module to extract clear features in the simulated high-density scene. Third, we propose a Dual-Density Memory Encoding Module that uses two crowd memories to learn scene-specific patterns from low- and simulated high-density scenes, respectively. Extensive experiments on four challenging datasets have shown the promising performance of L2HCount.
Micro-expression recognition based on depth map to point cloud
Jun 12, 2024Micro-expressions are nonverbal facial expressions that reveal the covert emotions of individuals, making the micro-expression recognition task receive widespread attention. However, the micro-expression recognition task is challenging due to the subtle facial motion and brevity in duration. Many 2D image-based methods have been developed in recent years to recognize MEs effectively, but, these approaches are restricted by facial texture information and are susceptible to environmental factors, such as lighting. Conversely, depth information can effectively represent motion information related to facial structure changes and is not affected by lighting. Motion information derived from facial structures can describe motion features that pixel textures cannot delineate. We proposed a network for micro-expression recognition based on facial depth information, and our experiments have demonstrated the crucial role of depth maps in the micro-expression recognition task. Initially, we transform the depth map into a point cloud and obtain the motion information for each point by aligning the initiating frame with the apex frame and performing a differential operation. Subsequently, we adjusted all point cloud motion feature input dimensions and used them as inputs for multiple point cloud networks to assess the efficacy of this representation. PointNet++ was chosen as the ultimate outcome for micro-expression recognition due to its superior performance. Our experiments show that our proposed method significantly outperforms the existing deep learning methods, including the baseline, on the $CAS(ME)^3$ dataset, which includes depth information.