 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDEFT-LLM: Disentangled Expert Feature Tuning for Micro-Expression Recognition
Nov 14, 2025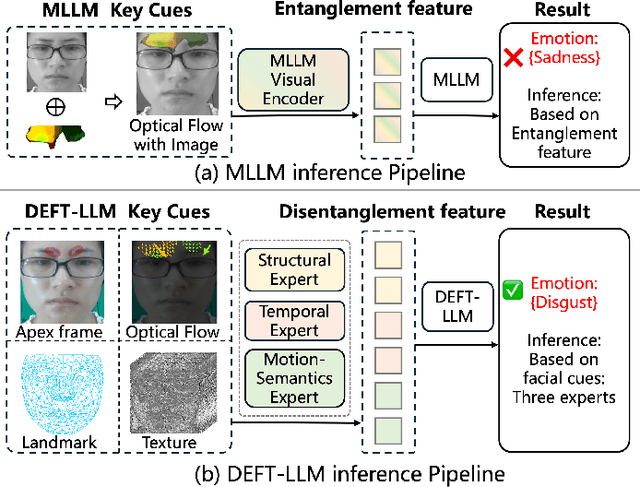
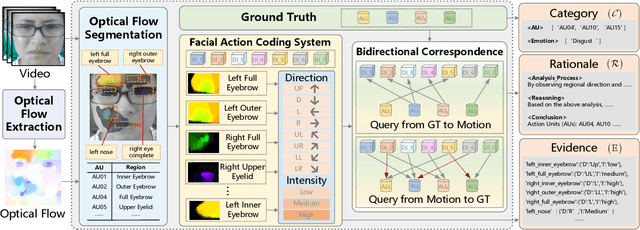
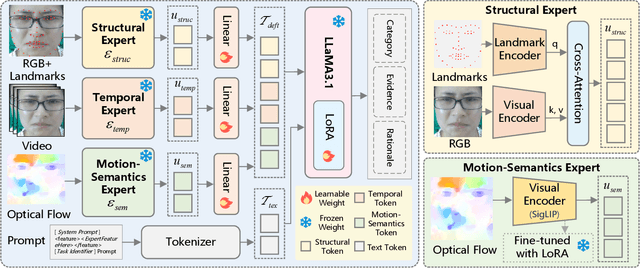
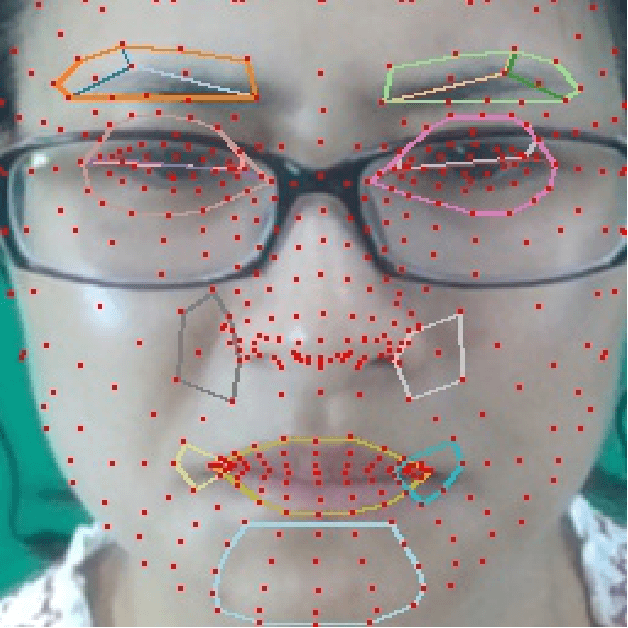
Micro expression recognition (MER) is crucial for inferring genuine emotion. Applying a multimodal large language model (MLLM) to this task enables spatio-temporal analysis of facial motion and provides interpretable descriptions. However, there are still two core challenges: (1) The entanglement of static appearance and dynamic motion cues prevents the model from focusing on subtle motion; (2) Textual labels in existing MER datasets do not fully correspond to underlying facial muscle movements, creating a semantic gap between text supervision and physical motion. To address these issues, we propose DEFT-LLM, which achieves motion semantic alignment by multi-expert disentanglement. We first introduce Uni-MER, a motion-driven instruction dataset designed to align text with local facial motion. Its construction leverages dual constraints from optical flow and Action Unit (AU) labels to ensure spatio-temporal consistency and reasonable correspondence to the movements. We then design an architecture with three experts to decouple facial dynamics into independent and interpretable representations (structure, dynamic textures, and motion-semantics). By integrating the instruction-aligned knowledge from Uni-MER into DEFT-LLM, our method injects effective physical priors for micro expressions while also leveraging the cross modal reasoning ability of large language models, thus enabling precise capture of subtle emotional cues. Experiments on multiple challenging MER benchmarks demonstrate state-of-the-art performance, as well as a particular advantage in interpretable modeling of local facial motion.
L2HCount:Generalizing Crowd Counting from Low to High Crowd Density via Density Simulation
Mar 17, 2025Since COVID-19, crowd-counting tasks have gained wide applications. While supervised methods are reliable, annotation is more challenging in high-density scenes due to small head sizes and severe occlusion, whereas it's simpler in low-density scenes. Interestingly, can we train the model in low-density scenes and generalize it to high-density scenes? Therefore, we propose a low- to high-density generalization framework (L2HCount) that learns the pattern related to high-density scenes from low-density ones, enabling it to generalize well to high-density scenes. Specifically, we first introduce a High-Density Simulation Module and a Ground-Truth Generation Module to construct fake high-density images along with their corresponding ground-truth crowd annotations respectively by image-shifting technique, effectively simulating high-density crowd patterns. However, the simulated images have two issues: image blurring and loss of low-density image characteristics. Therefore, we second propose a Head Feature Enhancement Module to extract clear features in the simulated high-density scene. Third, we propose a Dual-Density Memory Encoding Module that uses two crowd memories to learn scene-specific patterns from low- and simulated high-density scenes, respectively. Extensive experiments on four challenging datasets have shown the promising performance of L2HCount.
ActivityCLIP: Enhancing Group Activity Recognition by Mining Complementary Information from Text to Supplement Image Modality
Jul 29, 2024



Previous methods usually only extract the image modality's information to recognize group activity. However, mining image information is approaching saturation, making it difficult to extract richer information. Therefore, extracting complementary information from other modalities to supplement image information has become increasingly important. In fact, action labels provide clear text information to express the action's semantics, which existing methods often overlook. Thus, we propose ActivityCLIP, a plug-and-play method for mining the text information contained in the action labels to supplement the image information for enhancing group activity recognition. ActivityCLIP consists of text and image branches, where the text branch is plugged into the image branch (The off-the-shelf image-based method). The text branch includes Image2Text and relation modeling modules. Specifically, we propose the knowledge transfer module, Image2Text, which adapts image information into text information extracted by CLIP via knowledge distillation. Further, to keep our method convenient, we add fewer trainable parameters based on the relation module of the image branch to model interaction relation in the text branch. To show our method's generality, we replicate three representative methods by ActivityCLIP, which adds only limited trainable parameters, achieving favorable performance improvements for each method. We also conduct extensive ablation studies and compare our method with state-of-the-art methods to demonstrate the effectiveness of ActivityCLIP.
MLP-AIR: An Efficient MLP-Based Method for Actor Interaction Relation Learning in Group Activity Recognition
Apr 18, 2023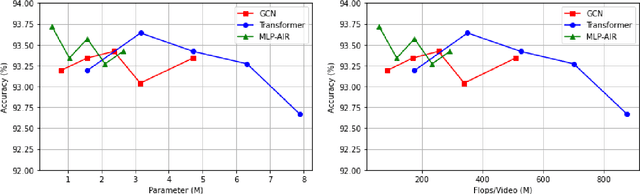

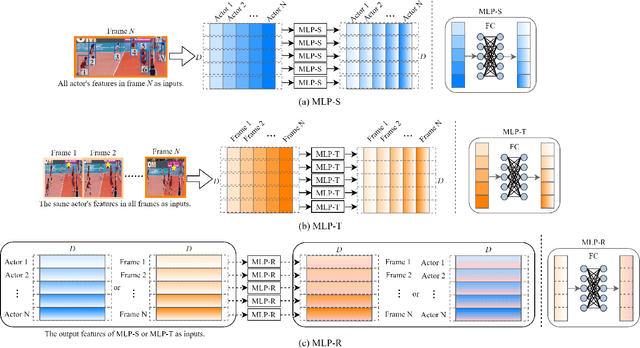

The task of Group Activity Recognition (GAR) aims to predict the activity category of the group by learning the actor spatial-temporal interaction relation in the group. Therefore, an effective actor relation learning method is crucial for the GAR task. The previous works mainly learn the interaction relation by the well-designed GCNs or Transformers. For example, to infer the actor interaction relation, GCNs need a learnable adjacency, and Transformers need to calculate the self-attention. Although the above methods can model the interaction relation effectively, they also increase the complexity of the model (the number of parameters and computations). In this paper, we design a novel MLP-based method for Actor Interaction Relation learning (MLP-AIR) in GAR. Compared with GCNs and Transformers, our method has a competitive but conceptually and technically simple alternative, significantly reducing the complexity. Specifically, MLP-AIR includes three sub-modules: MLP-based Spatial relation modeling module (MLP-S), MLP-based Temporal relation modeling module (MLP-T), and MLP-based Relation refining module (MLP-R). MLP-S is used to model the spatial relation between different actors in each frame. MLP-T is used to model the temporal relation between different frames for each actor. MLP-R is used further to refine the relation between different dimensions of relation features to improve the feature's expression ability. To evaluate the MLP-AIR, we conduct extensive experiments on two widely used benchmarks, including the Volleyball and Collective Activity datasets. Experimental results demonstrate that MLP-AIR can get competitive results but with low complexity.
Discrete schemes for Gaussian curvature and their convergence
Apr 07, 2008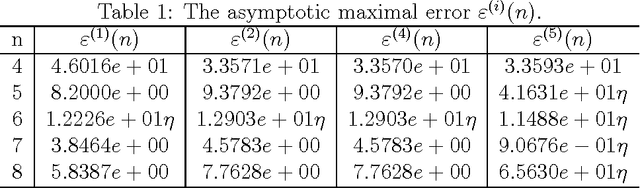

In this paper, several discrete schemes for Gaussian curvature are surveyed. The convergence property of a modified discrete scheme for the Gaussian curvature is considered. Furthermore, a new discrete scheme for Gaussian curvature is resented. We prove that the new scheme converges at the regular vertex with valence not less than 5. By constructing a counterexample, we also show that it is impossible for building a discrete scheme for Gaussian curvature which converges over the regular vertex with valence 4. Finally, asymptotic errors of several discrete scheme for Gaussian curvature are compared.