 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLP-AIR: An Efficient MLP-Based Method for Actor Interaction Relation Learning in Group Activity Recognition
Paper and Code
Apr 18, 2023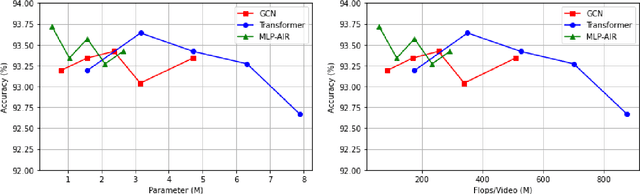

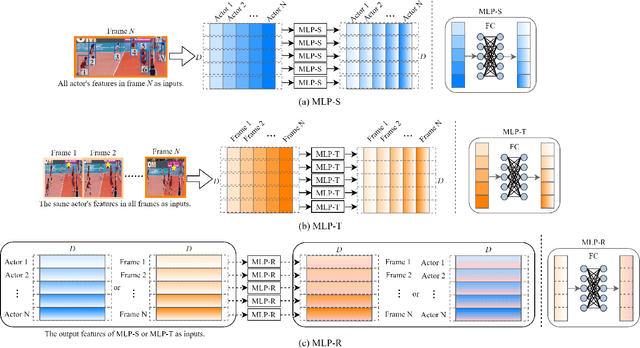

The task of Group Activity Recognition (GAR) aims to predict the activity category of the group by learning the actor spatial-temporal interaction relation in the group. Therefore, an effective actor relation learning method is crucial for the GAR task. The previous works mainly learn the interaction relation by the well-designed GCNs or Transformers. For example, to infer the actor interaction relation, GCNs need a learnable adjacency, and Transformers need to calculate the self-attention. Although the above methods can model the interaction relation effectively, they also increase the complexity of the model (the number of parameters and computations). In this paper, we design a novel MLP-based method for Actor Interaction Relation learning (MLP-AIR) in GAR. Compared with GCNs and Transformers, our method has a competitive but conceptually and technically simple alternative, significantly reducing the complexity. Specifically, MLP-AIR includes three sub-modules: MLP-based Spatial relation modeling module (MLP-S), MLP-based Temporal relation modeling module (MLP-T), and MLP-based Relation refining module (MLP-R). MLP-S is used to model the spatial relation between different actors in each frame. MLP-T is used to model the temporal relation between different frames for each actor. MLP-R is used further to refine the relation between different dimensions of relation features to improve the feature's expression ability. To evaluate the MLP-AIR, we conduct extensive experiments on two widely used benchmarks, including the Volleyball and Collective Activity datasets. Experimental results demonstrate that MLP-AIR can get competitive results but with low complexity.