 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrive My Way: Preference Alignment of Vision-Language-Action Model for Personalized Driving
Mar 26, 2026Human driving behavior is inherently personal, which is shaped by long-term habits and influenced by short-term intentions. Individuals differ in how they accelerate, brake, merge, yield, and overtake across diverse situations. However, existing end-to-end autonomous driving systems either optimize for generic objectives or rely on fixed driving modes, lacking the ability to adapt to individual preferences or interpret natural language intent. To address this gap, we propose Drive My Way (DMW), a personalized Vision-Language-Action (VLA) driving framework that aligns with users' long-term driving habits and adapts to real-time user instructions. DMW learns a user embedding from our personalized driving dataset collected across multiple real drivers and conditions the policy on this embedding during planning, while natural language instructions provide additional short-term guidance. Closed-loop evaluation on the Bench2Drive benchmark demonstrates that DMW improves style instruction adaptation, and user studies show that its generated behaviors are recognizable as each driver's own style, highlighting personalization as a key capability for human-centered autonomous driving. Our data and code are available at https://dmw-cvpr.github.io/.
NavTrust: Benchmarking Trustworthiness for Embodied Navigation
Mar 19, 2026There are two major categories of embodied navigation: Vision-Language Navigation (VLN), where agents navigate by following natural language instructions; and Object-Goal Navigation (OGN), where agents navigate to a specified target object. However, existing work primarily evaluates model performance under nominal conditions, overlooking the potential corruptions that arise in real-world settings. To address this gap, we present NavTrust, a unified benchmark that systematically corrupts input modalities, including RGB, depth, and instructions, in realistic scenarios and evaluates their impact on navigation performance. To our best knowledge, NavTrust is the first benchmark that exposes embodied navigation agents to diverse RGB-Depth corruptions and instruction variations in a unified framework. Our extensive evaluation of seven state-of-the-art approaches reveals substantial performance degradation under realistic corruptions, which highlights critical robustness gaps and provides a roadmap toward more trustworthy embodied navigation systems. Furthermore, we systematically evaluate four distinct mitigation strategies to enhance robustness against RGB-Depth and instructions corruptions. Our base models include Uni-NaVid and ETPNav. We deployed them on a real mobile robot and observed improved robustness to corruptions. The project website is: https://navtrust.github.io.
U-OBCA: Uncertainty-Aware Optimization-Based Collision Avoidance via Wasserstein Distributionally Robust Chance Constraints
Mar 05, 2026Uncertainties arising from localization error, trajectory prediction errors of the moving obstacles and environmental disturbances pose significant challenges to robot's safe navigation. Existing uncertainty-aware planners often approximate polygon-shaped robots and obstacles using simple geometric primitives such as circles or ellipses. Though computationally convenient, these approximations substantially shrink the feasible space, leading to overly conservative trajectories and even planning failure in narrow environments. In addition, many such methods rely on specific assumptions about noise distributions, which may not hold in practice and thus limit their performance guarantees. To address these limitations, we extend the Optimization-Based Collision Avoidance (OBCA) framework to an uncertainty-aware formulation, termed \emph{U-OBCA}. The proposed method explicitly accounts for the collision risk between polygon-shaped robots and obstacles by formulating OBCA-based chance constraints, and hence avoiding geometric simplifications and reducing unnecessary conservatism. These probabilistic constraints are further tightened into deterministic nonlinear constraints under mild distributional assumptions, which can be solved efficiently by standard numerical optimization solvers. The proposed approach is validated through theoretical analysis, numerical simulations and real-world experiments. The results demonstrate that U-OBCA significantly mitigates the conservatism in trajectory planning and achieves higher navigation efficiency compared to existing baseline methods, particularly in narrow and cluttered environments.
Agentic AI for Scalable and Robust Optical Systems Control
Feb 23, 2026We present AgentOptics, an agentic AI framework for high-fidelity, autonomous optical system control built on the Model Context Protocol (MCP). AgentOptics interprets natural language tasks and executes protocol-compliant actions on heterogeneous optical devices through a structured tool abstraction layer. We implement 64 standardized MCP tools across 8 representative optical devices and construct a 410-task benchmark to evaluate request understanding, role-aware responses, multi-step coordination, robustness to linguistic variation, and error handling. We assess two deployment configurations--commercial online LLMs and locally hosted open-source LLMs--and compare them with LLM-based code generation baselines. AgentOptics achieves 87.7%--99.0% average task success rates, significantly outperforming code-generation approaches, which reach up to 50% success. We further demonstrate broader applicability through five case studies extending beyond device-level control to system orchestration, monitoring, and closed-loop optimization. These include DWDM link provisioning and coordinated monitoring of coherent 400 GbE and analog radio-over-fiber (ARoF) channels; autonomous characterization and bias optimization of a wideband ARoF link carrying 5G fronthaul traffic; multi-span channel provisioning with launch power optimization; closed-loop fiber polarization stabilization; and distributed acoustic sensing (DAS)-based fiber monitoring with LLM-assisted event detection. These results establish AgentOptics as a scalable, robust paradigm for autonomous control and orchestration of heterogeneous optical systems.
Optical Link Tomography: First Field Trial and 4D Extension
Oct 10, 2025Optical link tomography (OLT) is a rapidly evolving field that allows the multi-span, end-to-end visualization of optical power along fiber links in multiple dimensions from network endpoints, solely by processing signals received at coherent receivers. This paper has two objectives: (1) to report the first field trial of OLT, using a commercial transponder under standard DWDM transmission, and (2) to extend its capability to visualize across 4D (distance, time, frequency, and polarization), allowing for locating and measuring multiple QoT degradation causes, including time-varying power anomalies, spectral anomalies, and excessive polarization dependent loss. We also address a critical aspect of OLT, i.e., its need for high fiber launch power, by improving power profile signal-to-noise ratio through averaging across all available dimensions. Consequently, multiple loss anomalies in a field-deployed link are observed even at launch power lower than the system-optimal level. The applications and use cases of OLT from network commissioning to provisioning and operation for current and near-term network scenarios are also discussed.
* 12 pages, 7 figures, accepted version for Journal of Lightwave Technology
Breaking Down and Building Up: Mixture of Skill-Based Vision-and-Language Navigation Agents
Aug 11, 2025Vision-and-Language Navigation (VLN) poses significant challenges in enabling agents to interpret natural language instructions and navigate complex 3D environments. While recent progress has been driven by large-scale pre-training and data augmentation, current methods still struggle to generalize to unseen scenarios, particularly when complex spatial and temporal reasoning is required. In this work, we propose SkillNav, a modular framework that introduces structured, skill-based reasoning into Transformer-based VLN agents. Our method decomposes navigation into a set of interpretable atomic skills (e.g., Vertical Movement, Area and Region Identification, Stop and Pause), each handled by a specialized agent. We then introduce a novel zero-shot Vision-Language Model (VLM)-based router, which dynamically selects the most suitable agent at each time step by aligning sub-goals with visual observations and historical actions. SkillNav achieves a new state-of-the-art performance on the R2R benchmark and demonstrates strong generalization to the GSA-R2R benchmark that includes novel instruction styles and unseen environments.
NTIRE 2025 challenge on Text to Image Generation Model Quality Assessment
May 22, 2025This paper reports on the NTIRE 2025 challenge on Text to Image (T2I) generation model quality assessment, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2025. The aim of this challenge is to address the fine-grained quality assessment of text-to-image generation models. This challenge evaluates text-to-image models from two aspects: image-text alignment and image structural distortion detection, and is divided into the alignment track and the structural track. The alignment track uses the EvalMuse-40K, which contains around 40K AI-Generated Images (AIGIs) generated by 20 popular generative models. The alignment track has a total of 371 registered participants. A total of 1,883 submissions are received in the development phase, and 507 submissions are received in the test phase. Finally, 12 participating teams submitted their models and fact sheets. The structure track uses the EvalMuse-Structure, which contains 10,000 AI-Generated Images (AIGIs) with corresponding structural distortion mask. A total of 211 participants have registered in the structure track. A total of 1155 submissions are received in the development phase, and 487 submissions are received in the test phase. Finally, 8 participating teams submitted their models and fact sheets. Almost all methods have achieved better results than baseline methods, and the winning methods in both tracks have demonstrated superior prediction performance on T2I model quality assessment.
Generative AI for Autonomous Driving: Frontiers and Opportunities
May 13, 2025Generative Artificial Intelligence (GenAI) constitutes a transformative technological wave that reconfigures industries through its unparalleled capabilities for content creation, reasoning, planning, and multimodal understanding. This revolutionary force offers the most promising path yet toward solving one of engineering's grandest challenges: achieving reliable, fully autonomous driving, particularly the pursuit of Level 5 autonomy. This survey delivers a comprehensive and critical synthesis of the emerging role of GenAI across the autonomous driving stack. We begin by distilling the principles and trade-offs of modern generative modeling, encompassing VAEs, GANs, Diffusion Models, and Large Language Models (LLMs). We then map their frontier applications in image, LiDAR, trajectory, occupancy, video generation as well as LLM-guided reasoning and decision making. We categorize practical applications, such as synthetic data workflows, end-to-end driving strategies, high-fidelity digital twin systems, smart transportation networks, and cross-domain transfer to embodied AI. We identify key obstacles and possibilities such as comprehensive generalization across rare cases, evaluation and safety checks, budget-limited implementation, regulatory compliance, ethical concerns, and environmental effects, while proposing research plans across theoretical assurances, trust metrics, transport integration, and socio-technical influence. By unifying these threads, the survey provides a forward-looking reference for researchers, engineers, and policymakers navigating the convergence of generative AI and advanced autonomous mobility. An actively maintained repository of cited works is available at https://github.com/taco-group/GenAI4AD.
Verb Mirage: Unveiling and Assessing Verb Concept Hallucinations in Multimodal Large Language Models
Dec 06, 2024



Multimodal Large Language Models (MLLMs) have garnered significant attention recently and demonstrate outstanding capabilities in various tasks such as OCR, VQA, captioning, $\textit{etc}$. However, hallucination remains a persistent issue. While numerous methods have been proposed to mitigate hallucinations, achieving notable improvements, these methods primarily focus on mitigating hallucinations about $\textbf{object/noun-related}$ concepts. Verb concepts, crucial for understanding human actions, have been largely overlooked. In this paper, to the best of our knowledge, we are the $\textbf{first}$ to investigate the $\textbf{verb hallucination}$ phenomenon of MLLMs from various perspectives. Our findings reveal that most state-of-the-art MLLMs suffer from severe verb hallucination. To assess the effectiveness of existing mitigation methods for object concept hallucination on verb hallucination, we evaluated these methods and found that they do not effectively address verb hallucination. To address this issue, we propose a novel rich verb knowledge-based tuning method to mitigate verb hallucination. The experiment results demonstrate that our method significantly reduces hallucinations related to verbs. $\textit{Our code and data will be made publicly available}$.
Navigating the Nuances: A Fine-grained Evaluation of Vision-Language Navigation
Sep 25, 2024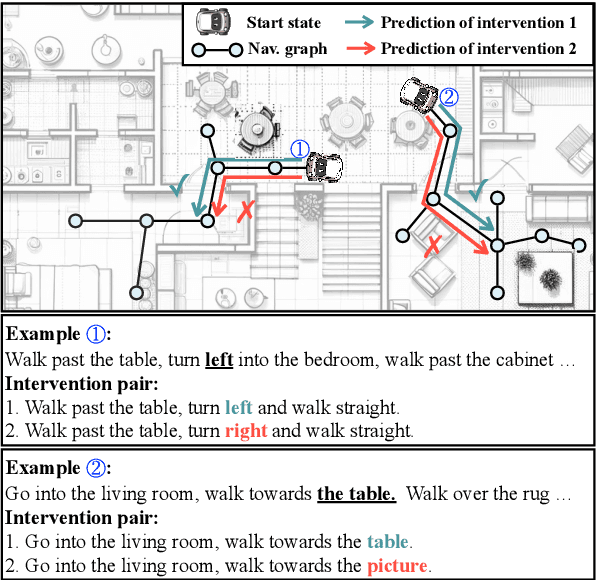
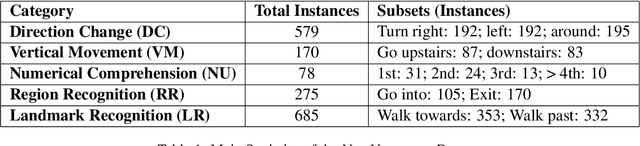

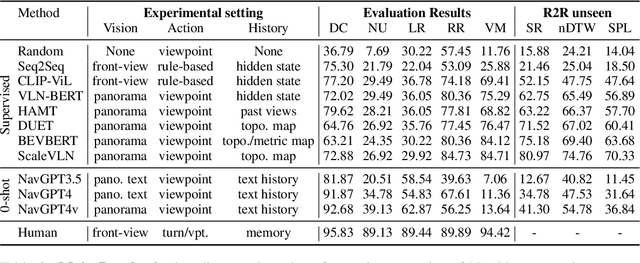
This study presents a novel evaluation framework for the Vision-Language Navigation (VLN) task. It aims to diagnose current models for various instruction categories at a finer-grained level. The framework is structured around the context-free grammar (CFG) of the task. The CFG serves as the basis for the problem decomposition and the core premise of the instruction categories design. We propose a semi-automatic method for CFG construction with the help of Large-Language Models (LLMs). Then, we induct and generate data spanning five principal instruction categories (i.e. direction change, landmark recognition, region recognition, vertical movement, and numerical comprehension). Our analysis of different models reveals notable performance discrepancies and recurrent issues. The stagnation of numerical comprehension, heavy selective biases over directional concepts, and other interesting findings contribute to the development of future language-guided navigation systems.