 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFigure It Out: Improve the Frontier of Reasoning with Executable Visual States
Jan 06, 2026Complex reasoning problems often involve implicit spatial and geometric relationships that are not explicitly encoded in text. While recent reasoning models perform well across many domains, purely text-based reasoning struggles to capture structural constraints in complex settings. In this paper, we introduce FIGR, which integrates executable visual construction into multi-turn reasoning via end-to-end reinforcement learning. Rather than relying solely on textual chains of thought, FIGR externalizes intermediate hypotheses by generating executable code that constructs diagrams within the reasoning loop. An adaptive reward mechanism selectively regulates when visual construction is invoked, enabling more consistent reasoning over latent global properties that are difficult to infer from text alone. Experiments on eight challenging mathematical benchmarks demonstrate that FIGR outperforms strong text-only chain-of-thought baselines, improving the base model by 13.12% on AIME 2025 and 11.00% on BeyondAIME. These results highlight the effectiveness of precise, controllable figure construction of FIGR in enhancing complex reasoning ability.
Figure It Out: Improving the Frontier of Reasoning with Active Visual Thinking
Dec 30, 2025Complex reasoning problems often involve implicit spatial, geometric, and structural relationships that are not explicitly encoded in text. While recent reasoning models have achieved strong performance across many domains, purely text-based reasoning struggles to represent global structural constraints in complex settings. In this paper, we introduce FIGR, which integrates active visual thinking into multi-turn reasoning via end-to-end reinforcement learning. FIGR externalizes intermediate structural hypotheses by constructing visual representations during problem solving. By adaptively regulating when and how visual reasoning should be invoked, FIGR enables more stable and coherent reasoning over global structural properties that are difficult to capture from text alone. Experiments on challenging mathematical reasoning benchmarks demonstrate that FIGR outperforms strong text-only chain-of-thought baselines. In particular, FIGR improves the base model by 13.12% on AIME 2025 and 11.00% on BeyondAIME, highlighting the effectiveness of figure-guided multimodal reasoning in enhancing the stability and reliability of complex reasoning.
CRAT: A Multi-Agent Framework for Causality-Enhanced Reflective and Retrieval-Augmented Translation with Large Language Models
Oct 28, 2024
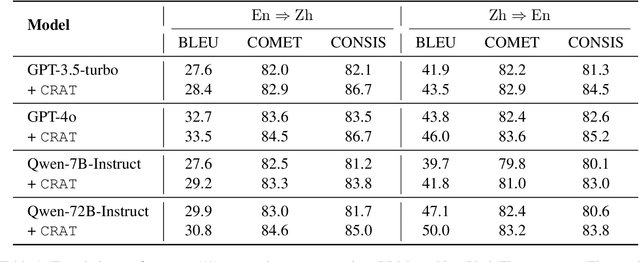
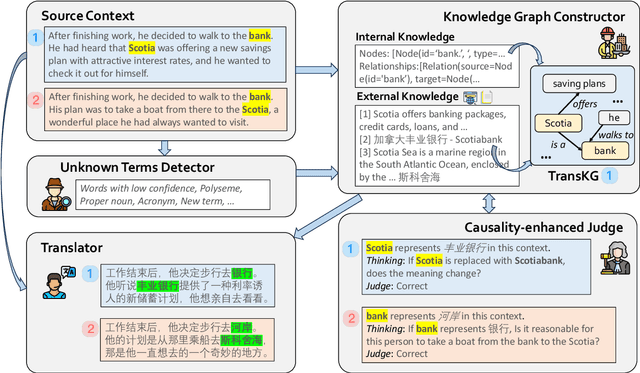
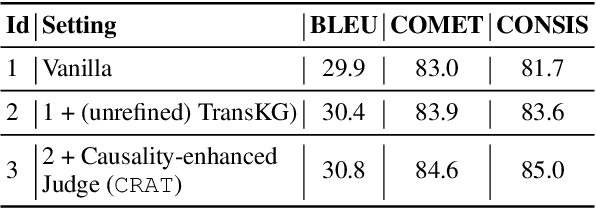
Large language models (LLMs) have shown great promise in machine translation, but they still struggle with contextually dependent terms, such as new or domain-specific words. This leads to inconsistencies and errors that are difficult to address. Existing solutions often depend on manual identification of such terms, which is impractical given the complexity and evolving nature of language. While Retrieval-Augmented Generation (RAG) could provide some assistance, its application to translation is limited by issues such as hallucinations from information overload. In this paper, we propose CRAT, a novel multi-agent translation framework that leverages RAG and causality-enhanced self-reflection to address these challenges. This framework consists of several specialized agents: the Unknown Terms Identification agent detects unknown terms within the context, the Knowledge Graph (KG) Constructor agent extracts relevant internal knowledge about these terms and retrieves bilingual information from external sources, the Causality-enhanced Judge agent validates the accuracy of the information, and the Translator agent incorporates the refined information into the final output. This automated process allows for more precise and consistent handling of key terms during translation. Our results show that CRAT significantly improves translation accuracy, particularly in handling context-sensitive terms and emerging vocabulary.
Navigating the Nuances: A Fine-grained Evaluation of Vision-Language Navigation
Sep 25, 2024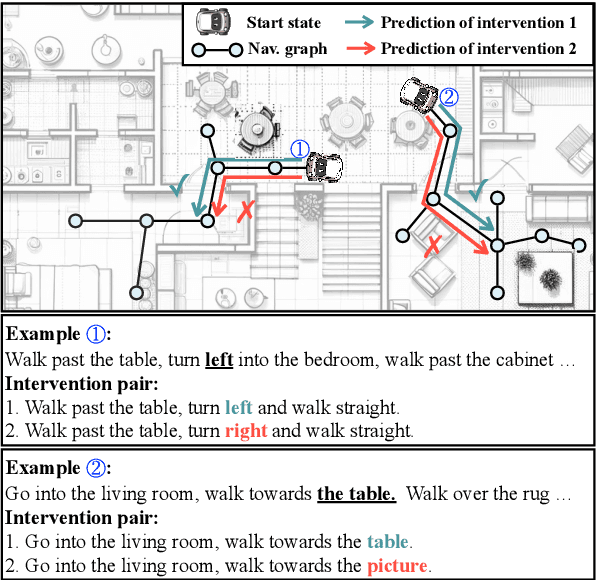
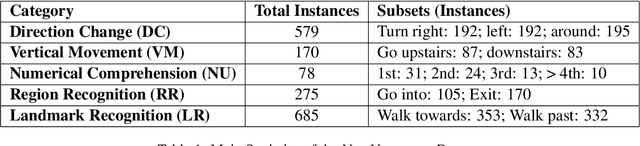

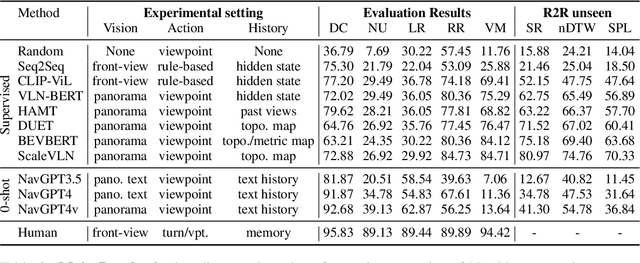
This study presents a novel evaluation framework for the Vision-Language Navigation (VLN) task. It aims to diagnose current models for various instruction categories at a finer-grained level. The framework is structured around the context-free grammar (CFG) of the task. The CFG serves as the basis for the problem decomposition and the core premise of the instruction categories design. We propose a semi-automatic method for CFG construction with the help of Large-Language Models (LLMs). Then, we induct and generate data spanning five principal instruction categories (i.e. direction change, landmark recognition, region recognition, vertical movement, and numerical comprehension). Our analysis of different models reveals notable performance discrepancies and recurrent issues. The stagnation of numerical comprehension, heavy selective biases over directional concepts, and other interesting findings contribute to the development of future language-guided navigation systems.
MMLongBench-Doc: Benchmarking Long-context Document Understanding with Visualizations
Jul 01, 2024Understanding documents with rich layouts and multi-modal components is a long-standing and practical task. Recent Large Vision-Language Models (LVLMs) have made remarkable strides in various tasks, particularly in single-page document understanding (DU). However, their abilities on long-context DU remain an open problem. This work presents MMLongBench-Doc, a long-context, multi-modal benchmark comprising 1,062 expert-annotated questions. Distinct from previous datasets, it is constructed upon 130 lengthy PDF-formatted documents with an average of 49.4 pages and 20,971 textual tokens. Towards comprehensive evaluation, answers to these questions rely on pieces of evidence from (1) different sources (text, image, chart, table, and layout structure) and (2) various locations (i.e. page number). Moreover, 33.2% of the questions are cross-page questions requiring evidence across multiple pages. 22.8% of the questions are designed to be unanswerable for detecting potential hallucinations. Experiments on 14 LVLMs demonstrate that long-context DU greatly challenges current models. Notably, the best-performing model, GPT-4o, achieves an F1 score of only 42.7%, while the second-best, GPT-4V, scores 31.4%. Furthermore, 12 LVLMs (all except GPT-4o and GPT-4V) even present worse performance than their LLM counterparts which are fed with lossy-parsed OCR documents. These results validate the necessity of future research toward more capable long-context LVLMs. Project Page: https://mayubo2333.github.io/MMLongBench-Doc
CELLO: Causal Evaluation of Large Vision-Language Models
Jun 27, 2024Causal reasoning is fundamental to human intelligence and crucial for effective decision-making in real-world environments. Despite recent advancements in large vision-language models (LVLMs), their ability to comprehend causality remains unclear. Previous work typically focuses on commonsense causality between events and/or actions, which is insufficient for applications like embodied agents and lacks the explicitly defined causal graphs required for formal causal reasoning. To overcome these limitations, we introduce a fine-grained and unified definition of causality involving interactions between humans and/or objects. Building on the definition, we construct a novel dataset, CELLO, consisting of 14,094 causal questions across all four levels of causality: discovery, association, intervention, and counterfactual. This dataset surpasses traditional commonsense causality by including explicit causal graphs that detail the interactions between humans and objects. Extensive experiments on CELLO reveal that current LVLMs still struggle with causal reasoning tasks, but they can benefit significantly from our proposed CELLO-CoT, a causally inspired chain-of-thought prompting strategy. Both quantitative and qualitative analyses from this study provide valuable insights for future research. Our project page is at https://github.com/OpenCausaLab/CELLO.
Causal Evaluation of Language Models
May 01, 2024Causal reasoning is viewed as crucial for achieving human-level machine intelligence. Recent advances in language models have expanded the horizons of artificial intelligence across various domains, sparking inquiries into their potential for causal reasoning. In this work, we introduce Causal evaluation of Language Models (CaLM), which, to the best of our knowledge, is the first comprehensive benchmark for evaluating the causal reasoning capabilities of language models. First, we propose the CaLM framework, which establishes a foundational taxonomy consisting of four modules: causal target (i.e., what to evaluate), adaptation (i.e., how to obtain the results), metric (i.e., how to measure the results), and error (i.e., how to analyze the bad results). This taxonomy defines a broad evaluation design space while systematically selecting criteria and priorities. Second, we compose the CaLM dataset, comprising 126,334 data samples, to provide curated sets of causal targets, adaptations, metrics, and errors, offering extensive coverage for diverse research pursuits. Third, we conduct an extensive evaluation of 28 leading language models on a core set of 92 causal targets, 9 adaptations, 7 metrics, and 12 error types. Fourth, we perform detailed analyses of the evaluation results across various dimensions (e.g., adaptation, scale). Fifth, we present 50 high-level empirical findings across 9 dimensions (e.g., model), providing valuable guidance for future language model development. Finally, we develop a multifaceted platform, including a website, leaderboards, datasets, and toolkits, to support scalable and adaptable assessments. We envision CaLM as an ever-evolving benchmark for the community, systematically updated with new causal targets, adaptations, models, metrics, and error types to reflect ongoing research advancements. Project website is at https://opencausalab.github.io/CaLM.
Quantifying and Mitigating Unimodal Biases in Multimodal Large Language Models: A Causal Perspective
Apr 03, 2024Recent advancements in Large Language Models (LLMs) have facilitated the development of Multimodal LLMs (MLLMs). Despite their impressive capabilities, MLLMs often suffer from an over-reliance on unimodal biases (e.g., language bias and vision bias), leading to incorrect answers in complex multimodal tasks. To investigate this issue, we propose a causal framework to interpret the biases in Visual Question Answering (VQA) problems. Within our framework, we devise a causal graph to elucidate the predictions of MLLMs on VQA problems, and assess the causal effect of biases through an in-depth causal analysis. Motivated by the causal graph, we introduce a novel MORE dataset, consisting of 12,000 VQA instances. This dataset is designed to challenge MLLMs' abilities, necessitating multi-hop reasoning and the surmounting of unimodal biases. Furthermore, we propose two strategies to mitigate unimodal biases and enhance MLLMs' reasoning capabilities, including a Decompose-Verify-Answer (DeVA) framework for limited-access MLLMs and the refinement of open-source MLLMs through fine-tuning. Extensive quantitative and qualitative experiments offer valuable insights for future research. Our project page is at https://opencausalab.github.io/MORE.
From GPT-4 to Gemini and Beyond: Assessing the Landscape of MLLMs on Generalizability, Trustworthiness and Causality through Four Modalities
Jan 29, 2024



Multi-modal Large Language Models (MLLMs) have shown impressive abilities in generating reasonable responses with respect to multi-modal contents. However, there is still a wide gap between the performance of recent MLLM-based applications and the expectation of the broad public, even though the most powerful OpenAI's GPT-4 and Google's Gemini have been deployed. This paper strives to enhance understanding of the gap through the lens of a qualitative study on the generalizability, trustworthiness, and causal reasoning capabilities of recent proprietary and open-source MLLMs across four modalities: ie, text, code, image, and video, ultimately aiming to improve the transparency of MLLMs. We believe these properties are several representative factors that define the reliability of MLLMs, in supporting various downstream applications. To be specific, we evaluate the closed-source GPT-4 and Gemini and 6 open-source LLMs and MLLMs. Overall we evaluate 230 manually designed cases, where the qualitative results are then summarized into 12 scores (ie, 4 modalities times 3 properties). In total, we uncover 14 empirical findings that are useful to understand the capabilities and limitations of both proprietary and open-source MLLMs, towards more reliable downstream multi-modal applications.
Learning To Teach Large Language Models Logical Reasoning
Oct 13, 2023Large language models (LLMs) have gained enormous attention from both academia and industry, due to their exceptional ability in language generation and extremely powerful generalization. However, current LLMs still output unreliable content in practical reasoning tasks due to their inherent issues (e.g., hallucination). To better disentangle this problem, in this paper, we conduct an in-depth investigation to systematically explore the capability of LLMs in logical reasoning. More in detail, we first investigate the deficiency of LLMs in logical reasoning on different tasks, including event relation extraction and deductive reasoning. Our study demonstrates that LLMs are not good reasoners in solving tasks with rigorous reasoning and will produce counterfactual answers, which require us to iteratively refine. Therefore, we comprehensively explore different strategies to endow LLMs with logical reasoning ability, and thus enable them to generate more logically consistent answers across different scenarios. Based on our approach, we also contribute a synthesized dataset (LLM-LR) involving multi-hop reasoning for evaluation and pre-training. Extensive quantitative and qualitative analyses on different tasks also validate the effectiveness and necessity of teaching LLMs with logic and provide insights for solving practical tasks with LLMs in future work.